[MSA] CQRS 패턴
개요
이전 게시글에서 MSA의 단점 중 하나로 거론한 `데이터 일관성 및 트랜잭션 처리 어려움`을 해결하기 위해 도입된 SAGA 패턴에 대해 간단히 정리했습니다.
https://jaimemin.tistory.com/2619
[MSA] SAGA 패턴
개요MSA (Microservices Architecture)는 하나의 커다란 애플리케이션 (Monolithic Architecture)를 독립적으로 배포되고 운영될 수 있는 작은 서비스들로 분리해 개발 운영하는 소프트웨어 아키텍처 스타일입
jaimemin.tistory.com
CQRS (Command Query Responsibility Segregation) 패턴은 읽기 (조회)와 쓰기 (명령)의 책임을 명확하게 분리하는 아키텍처 패턴으로 단일 모델이 모든 역할을 수행할 때 발생하는 복잡성, 성능 병목, 그리고 확장성 한계를 해결하기 위해 도입되었습니다.
이번 게시글에서는 CQRS 패턴에 대해 간단히 알아보겠습니다.
MSA의 태생적인 한계
MSA는 각 서비스가 독립적인 프로덕트로서 특정 도메인을 책임지도록 설계되었습니다.
이로 인해 서비스 간 협업이나 의존성을 최소화하려는 원칙을 따르며, 각각의 서비스는 자신만의 DB를 소유하고 해당 서비스의 경로를 통해서만 접근할 수 있게 됩니다.
이러한 데이터 오너십은 서비스 간의 독립성과 안정성을 유지하는 데 중요한 역할을 하지만, 동시에 몇 가지 한계를 가져옵니다.
- 서비스의 독립성 및 자율성: 각 서비스는 자신의 도메인과 관련된 모든 책임을 지며, 다른 서비스와의 직접적인 협업이나 연계를 피하며 이러한 독립성은 서비스 확장성과 유지보수에 유리하지만, 전체 시스템 내에서 정보를 연계하는 측면에서는 제약이 됨
- DB 접근의 제한: 각 서비스는 자신만의 DB를 가지고 있으며, 이는 데이터의 소유권과 무결성을 보장하기 위한 정책, 모든 데이터는 해당 서비스를 통해서만 접근 가능하므로, 하나의 통합된 데이터 저장소처럼 활용하기 어려움
- 다중 서비스 데이터 Join의 어려움: 여러 서비스에 분산되어 있는 데이터를 하나로 Join 하여 조회하거나 분석하려는 요구가 생길 경우, 각 서비스의 데이터가 독립적으로 관리되기 때문에 자연스럽게 Join이 어려워짐
- 두 개의 서로 다른 서비스에 분산된 관련 데이터를 결합하여 복합적인 정보 분석이 필요할 때, 각 서비스 API 호출을 통해 데이터를 가져와 다시 조합하는 등의 추가 작업이 필요
API Aggregation 패턴
- 각 서비스는 자신만의 데이터 오너십을 갖고 있어, 요청하는 쿼리는 언제나 해당 서비스에 소속된 데이터만 다루도록 처리
- 기존 모놀리식 시스템에서의 DB 테이블 간 Join을 사용해야 하는 경우, 각 서비스에 대해 별도로 여러 번 요청하여 데이터를 수집
- 이런 Query 방식을 API Aggregation 패턴이라고 지칭하며 적은 부하나 적은 데이터양의 경우에는, 이렇게 개별 API 호출을 통해 데이터를 수집하는 방식으로도 충분히 비즈니스 요구사항을 만족시킴
- API Aggregation 패턴은 소규모 데이터나 낮은 부하 환경에서는 문제없이 작동하지만, 대용량 데이터 처리나 고부하 환경일 경우에는 추가적으로 호출되는 API로 인해 DB 부하 또는 다른 서비스들에 장애를 전파시킬 수 있으므로 데이터 연계 및 집계 과정에서 추가적인 최적화나 별도의 데이터 통합 전략 필요
- 모놀리스 환경에서는 여러 테이블을 SQL의 Join으로 처리해 한 번에 해결할 수 있는 문제가, MSA에서는 개별 API 호출과 Aggregation 과정을 통해 대응해야 하는 상황으로 전환이 되며 이와 관련해 고려해야 할 사항은 다음과 같음
- 여러 번의 API 호출 과정 중 하나라도 실패하면, 전체 호출이 실패로 간주되어야 함, 이는 하나의 호출 실패가 전체 데이터의 신뢰성 및 정확도에 영향을 줄 수 있음을 의미
- Aggregation API는 여러 서비스에 API 호출을 실행하는 과정을 포함하므로, 개별 서비스 API보다 전체 처리 시간이 길어지며 이는 호출 횟수(N회)와 내부 로직 실행 시간이 모두 누적되어 발생하는 현상
정리하면 API Aggregation Pattern은 단순함과 직관성을 제공하지만, 그에 따른 시스템 전반의 관리와 설계 복잡성도 함께 고려해야 하는 단점이 존재합니다.
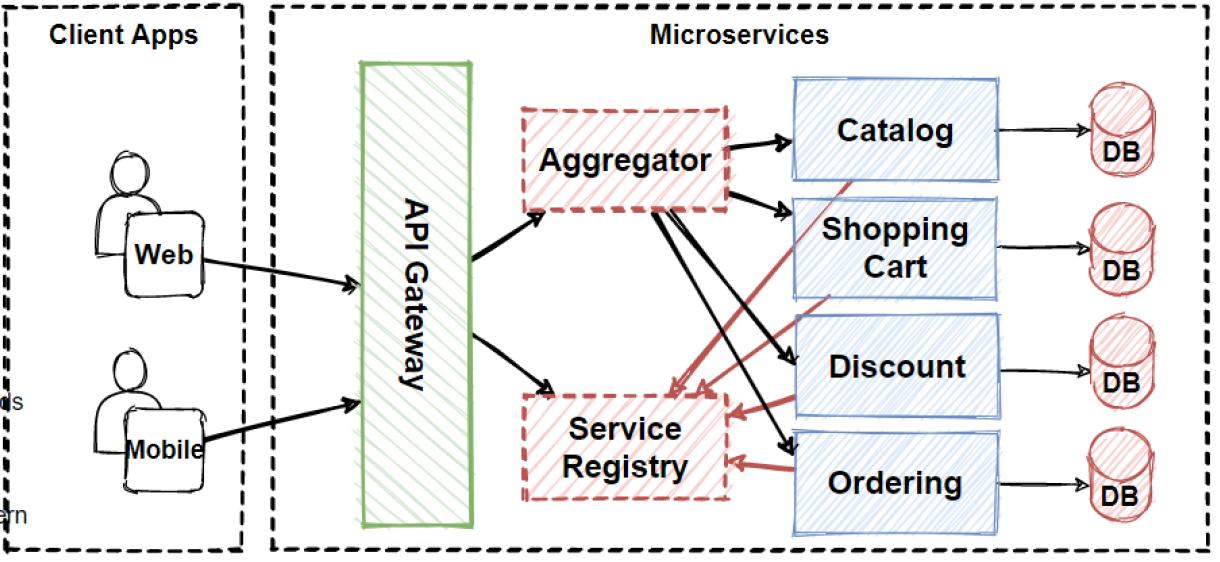
1. API Aggregation 패턴의 한계
회원 정보를 가진 서비스와 잔액 정보를 가진 서비스가 분리되어 있는 MSA 환경이고 앱 홈 화면에서 특정 구(예: 강남구)에 거주하는 전체 회원들의 잔액 변화 정보를 실시간으로 제공하고 싶은 요구사항이 있다고 가정하겠습니다.
위 요구사항 분석 및 처리 과정은 다음과 같습니다.
- 각 고객의 거주지를 확인하여 해당 구(예: 강남구)에 포함되는 고객을 식별
- 강남구에 해당하는 모든 회원들의 리스트 조회
- 해당 고객들의 잔액 정보를 개별적으로 조회
- 얻은 잔액 정보를 통대로 최종 집계 값 도출
- 계산된 총 잔액 정보를 실시간으로 앱 홈 화면에 전달
위 방식은 간단해 보이나 실제로 실시간으로 변환하는 데이터 (예: 고객 주소 변경 등)를 반영하기 위해 즉각적으로 처리해야 하는 상황에서 복잡한 문제가 발생할 수 있습니다.
- 최악의 경우 강남구에 거주하는 모든 고객 수만큼 잔액 정보를 개별적으로 가져와야 하므로 "잔액 정보를 가진 서비스"에 과도한 부하와 높은 Latency 문제가 발생할 수 있음
- 이러한 부하와 응답 지연은 실시간 업데이트가 필수적인 홈 화면 같은 중요한 서비스에서 심각한 영향을 미칠 가능성이 큼
API Aggregation 패턴이 갖는 한계는 이벤트 중심의 처리를 통해 해결을 할 수 있을 것 같습니다.
- 이벤트 중심의 처리: 강남구 고객의 잔액이 변동되면, 즉시 이벤트가 발생하며 해당 이벤트를 통해 “강남구 총잔액”에 반영하고, 별도의 저장소(SQL 등)에 해당 지역 전체 잔액을 업데이트
- 즉시 반영되는 총잔액:어떤 고객이 “강남구” 소속임을 회원 서비스에서 확인한 뒤, 잔액 서비스에서 잔액이 변동되는 이벤트를 전달받음, 그런 후 총잔액 변동분을 더하거나 빼서 최신 상태를 유지
- 실시간 조회 간소화: 실시간으로 홈 화면 등에 보여주기 위해 “강남구 총잔액”을 직접 계산하기보다는, 이미 집계해 둔 값을 그대로 가져오면 되므로 높은 부하 상황에서도 빠른 응답을 제공 가능
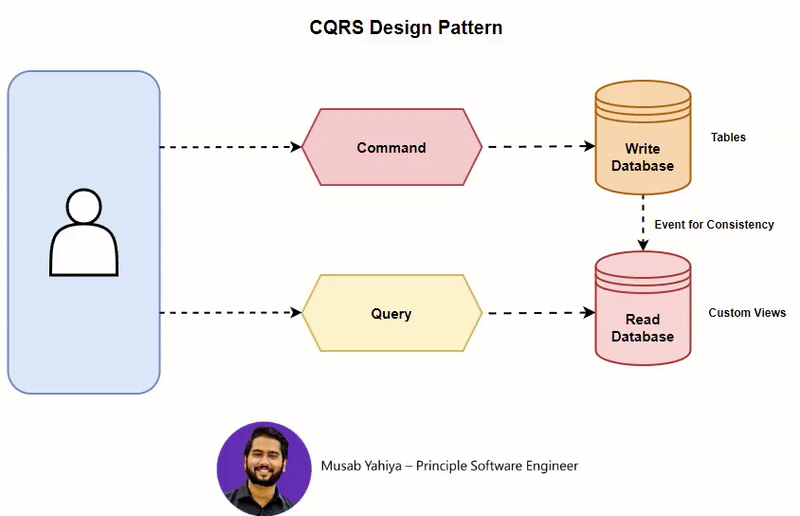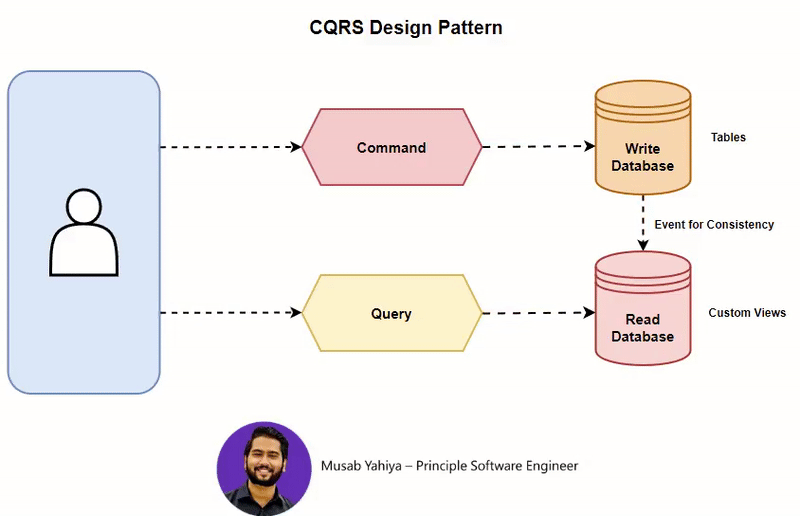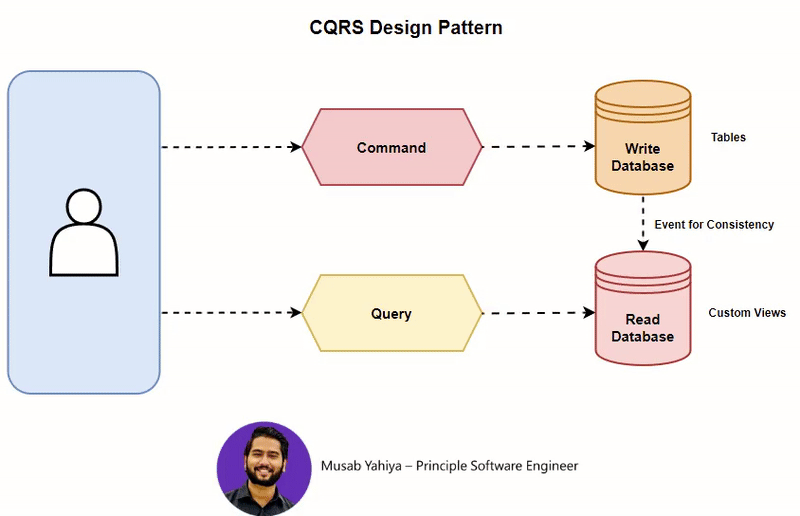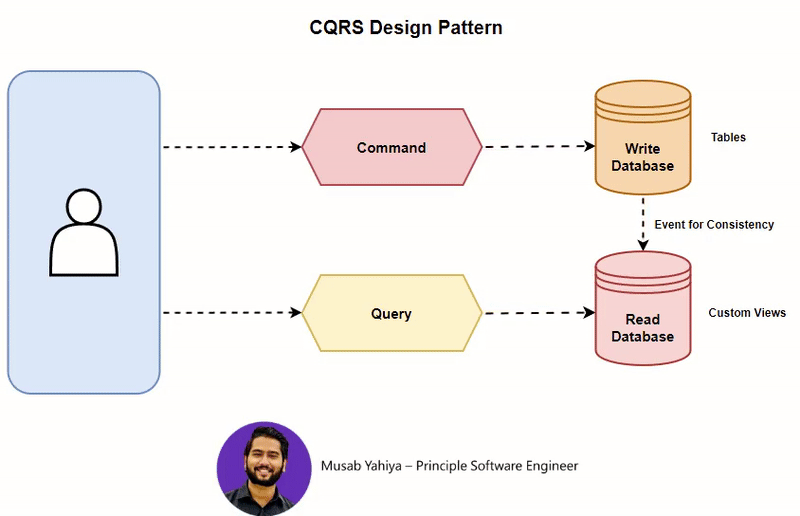
CQRS (Command Query Responsibility Segregation) 패턴
이벤트를 활용해 데이터의 변경 (Commands)과 데이터 조회( Queries)를 분리함으로써, 비즈니스 로직이 포함된 API를 더 효율적으로 구성할 수 있습니다.
CQRS 패턴은 이러한 방식으로 Command를 처리하는 부분과 Query를 담당하는 부분을 별도의 서비스나 모듈로 구분하는 아키텍처 패턴이며 필요에 따라 이벤트 소싱(Event Sourcing) 패턴과 함께 사용되어, 모든 상태 변경을 이벤트로 기록하고 이를 기반으로 현재 상태를 재구성할 수 있습니다.
앞서 API Aggregation 패턴에서 다룬 사례로 예를 들겠습니다.
- 머니가 +5,000 변동되었다는 이벤트가 발생
- 회원 서비스에서 해당 고객이 강남구 거주자임을 확인
- "강남구 총 잔액”에 5,000을 추가하여 최신 상태를 유지
- Query 전용 서비스가 해당 정보를 관리 및 제공
- Query 전용 서비스가 잔액 데이터에 접근은 하지만 변동시키지는 않기 때문에 "모든 데이터는 데이터 오너십을 가진 서비스에서만 해당 데이터를 관리해야 한다"라는 원칙에 위배되지 않음
- 모든 잔액의 정보를 "변동시키는 주체"는 여전히 Money 서비스

정리하면 MSA에서 CQRS 패턴은 읽기와 쓰기의 부하를 분리하고 각 역할에 최적화된 시스템을 구성하는 데 큰 장점을 제공합니다.
복잡한 비즈니스 로직과 높은 트래픽이 존재하는 서비스에서 특히 유용하지만, 시스템의 복잡성이 증가할 수 있으므로 요구사항과 시스템 특성을 고려하여 도입 여부를 결정해야 합니다.
CQRS 패턴을 효과적으로 적용하기 위해서는 도메인 주도 설계, 이벤트 소싱, 메시지 기반 통신 등 다른 패턴 및 기술과의 조합이 중요하며, 최종적 일관성을 어떻게 관리할지에 대한 명확한 전략이 필요합니다.
이와 같이 CQRS 패턴은 MSA 환경에서 유연성과 확장성, 성능 최적화를 위한 강력한 도구가 될 수 있습니다.
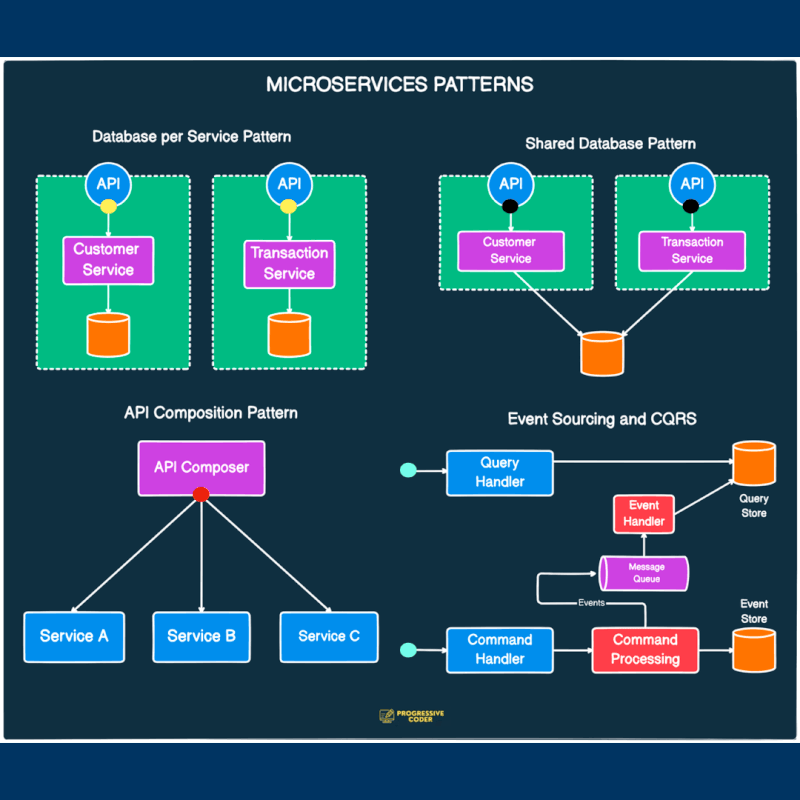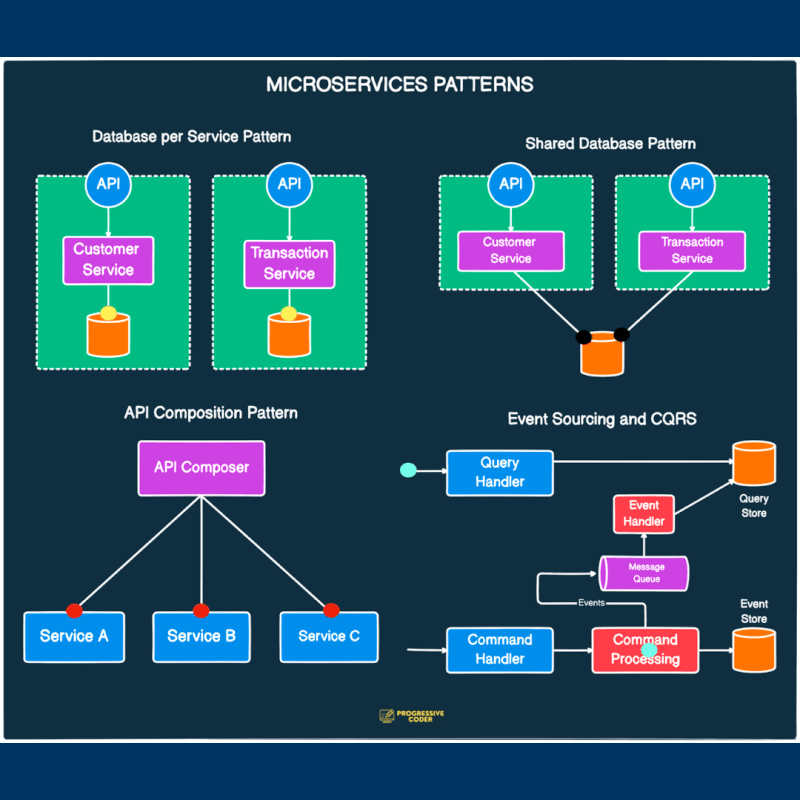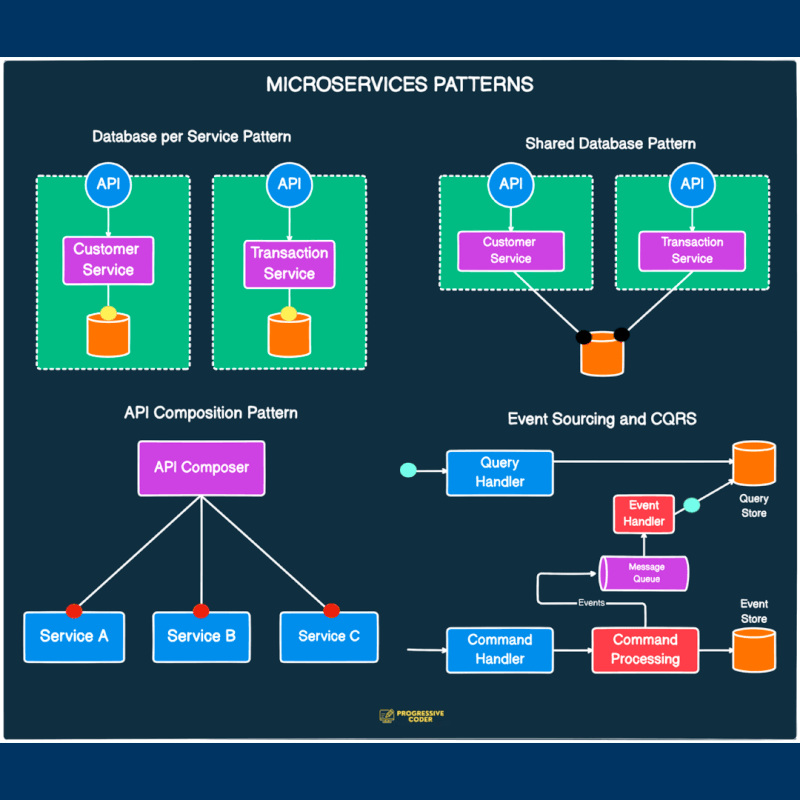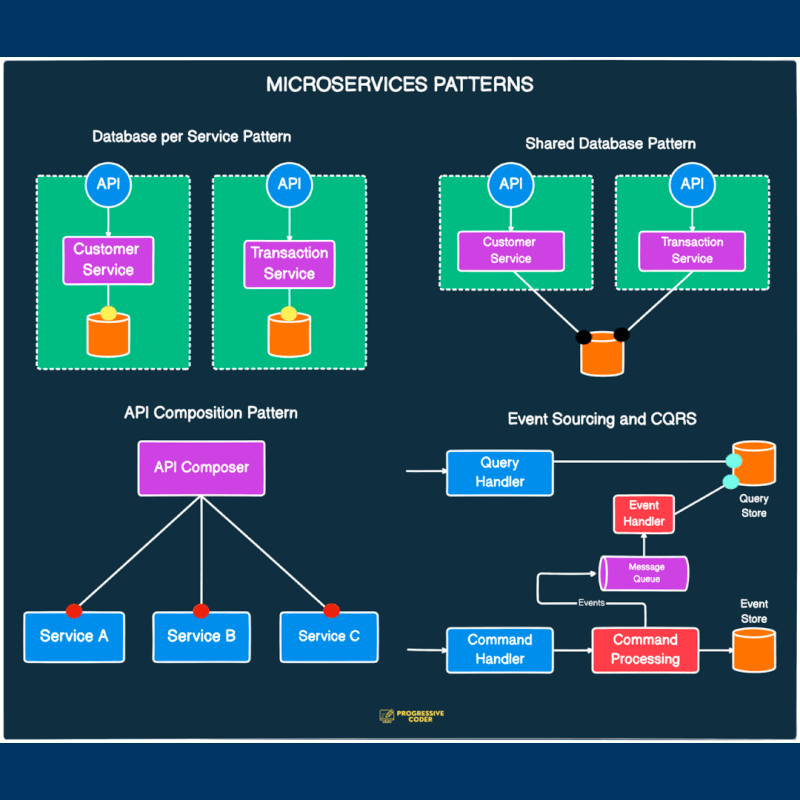
실습을 통해 비교하는 API Aggregation 패턴 vs CQRS 패턴
1. API Aggregation 패턴
1.1 실습 환경
MSA 환경이기 때문에 domain 성격에 따라 여러 서비스로 분리되어 있습니다.
- 회원 정보를 가지고 있는 membership-service
- 잔액 정보를 가지고 있는 money-service
- 위 두 서비스에 api를 호출하여 특정 지역에 거주하는 회원들의 잔액 합을 조회하는 money-aggregation-service
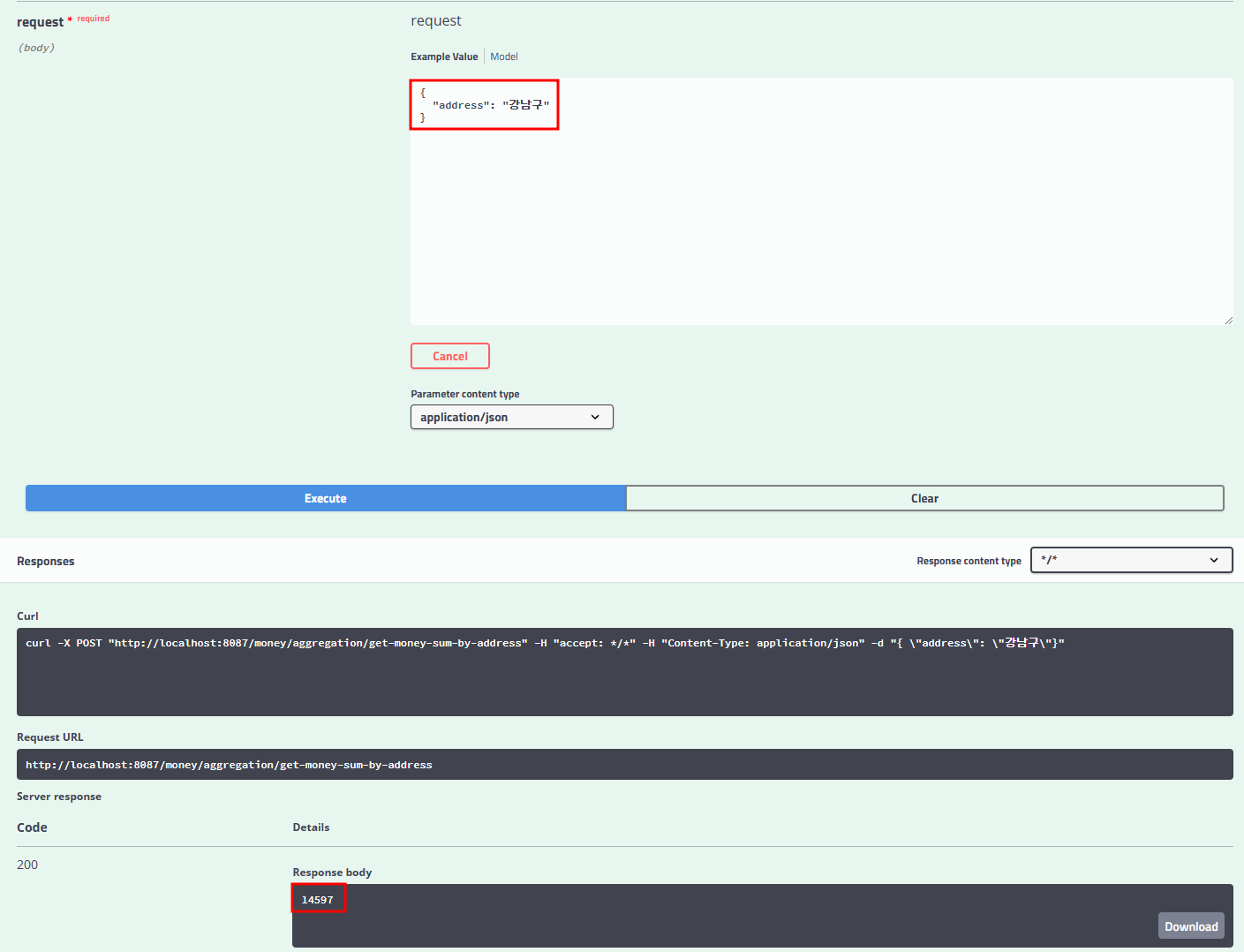
1.2 money-aggregation-service 로직
- membersip-service에 api를 호출하여 원하는 주소의 회원 리스트를 조회
- 조회된 회원 리스트를 100개씩 쪼개어 money-service로부터 전달한 회원 리스트의 전체 잔액을 받아옴
- 대량의 데이터를 효율적으로 처리하기 위해 100개 단위로 끊어서 조회
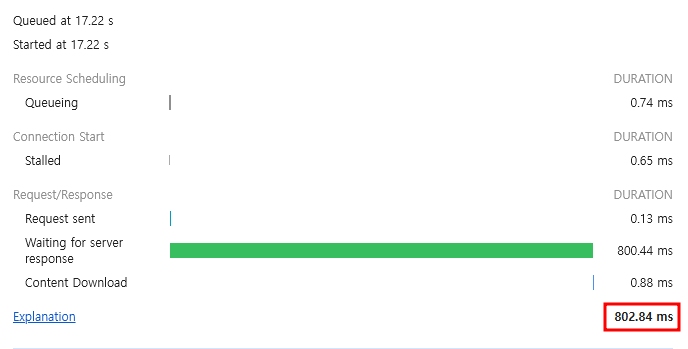
1.3 API Aggregation 패턴의 한계
- 앞서 API Aggregation 패턴의 한계에서 언급했듯이 최악의 경우 강남구에 거주하는 모든 고객 수만큼 잔액 정보를 개별적으로 가져와야 하므로 money-service에 과도한 부하와 높은 Latency 문제가 발생
- 이에 따라 회원 수가 늘어날수록 비례하여 Latency가 발생하는 것을 확인 가능
- 이를 위해 회원 수가 10,000명, 50,000명, 그리고 100,000명일 때 테스트를 진행해 봤고 결과는 다음과 같음


2. CQRS 패턴
2.1 실습 환경
- 회원 정보를 가지고 있는 membership-service
- 잔액 정보를 가지고 있는 money-service
- CQRS 패턴을 구현한 money-query-service
- Axon Framework 사용 (https://jaimemin.tistory.com/2619 참고)
- DynamoDB 사용
2.2 AWS DynamoDB를 사용하는 이유
- 추가 요금을 지불할 경우 복잡한 트랜잭션도 부분적으로 지원하지만 현재 money-query-service에서는 복잡한 트랜잭션이 필요 없으므로 free-tier로도 사용 가능
- 고성능 분산 데이터베이스로 많은 Event들을 받아서 안전하게 저장 가능
- key-value NoSQL의 일종으로, 접근 패턴(이번 실습에서는 지역)에 기반한 key 설계가 이루어질 경우 고성능을 기대할 수 있음
- 스키마가 없기 때문에 명확한 목접/접근 패턴(이번 실습에서는 지역)이 있어야만 효율적인 Key 설계 가능
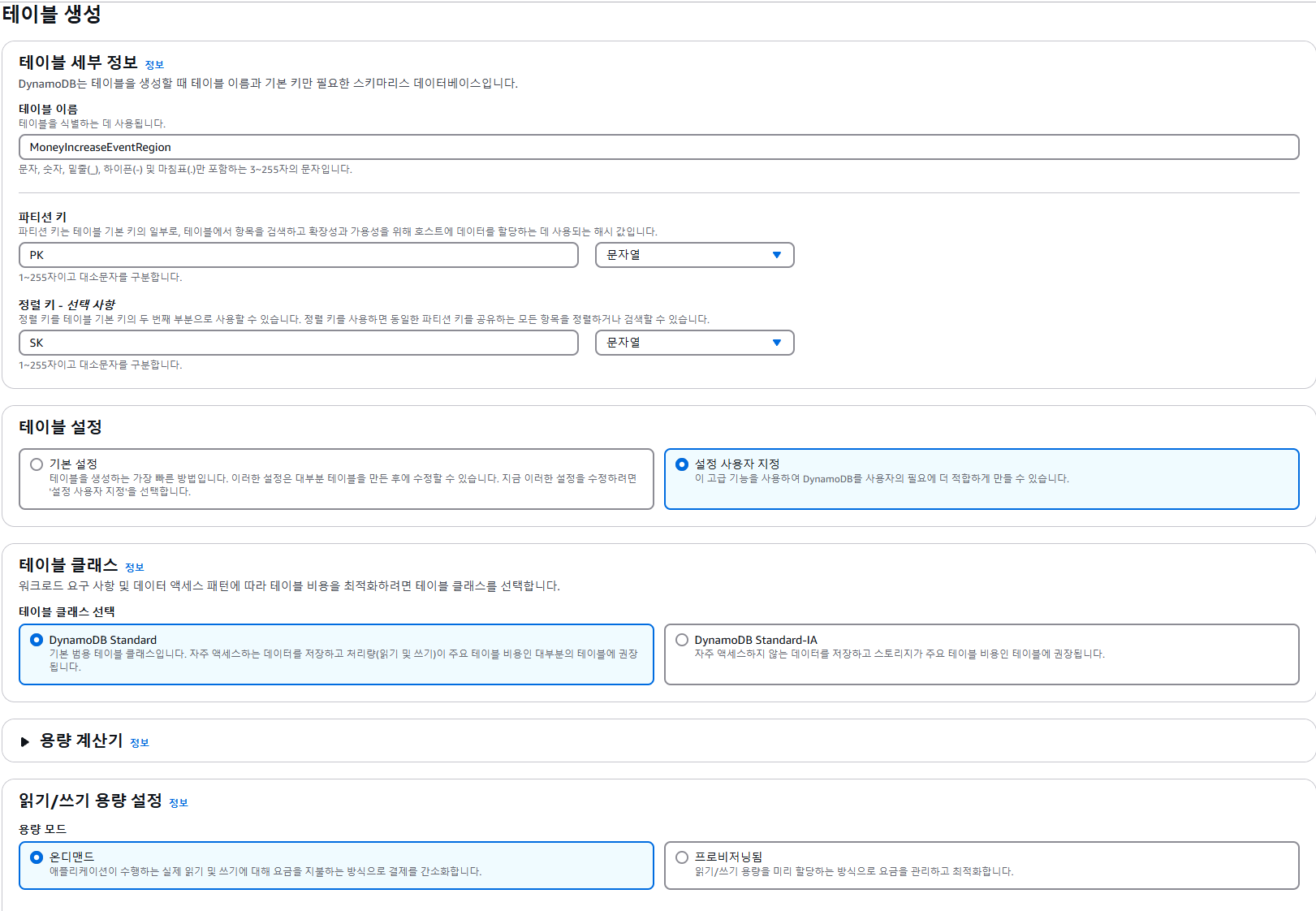
- PK (Partition Key): DynamoDB에 저장되는 데이터를 논리적으로 분리하는 키로 해당 키 값을 기반으로 AWS 내부적으로 데이터를 글로벌하게 분산시켜 파티셔닝 하고 데이터 조회, 데이터가 일정 수준 이상 쌓이면 PK를 기준으로 확장시키며 Equal 조건으로만 쿼리 가능
- SK (Sort Key): DynamoDB에서 Partition Key를 통해서 가져온 데이터들의 순서를 결정하는데 사용하는 키로 해당 키를 사용해서 파티션 내에서 데이터를 정렬하고 Range 쿼리 실행, SK는 독립적으로 사용이 불가능하며 항상 PK와 같이 사용
- ex) 특정 날짜(년, 월, 일)의 지역별(예: 강남구) 총 잔액을 알고 싶을 경우 `지역` 정보와 `특정 날짜` 정보를 기준으로 쿼리를 호출해야 하므로 `지역` 정보와 `특정 날짜` 정보를 PK에 포함시킴
- ex) 특정 날짜(년, 월, 일)의 특정 지역에서 가장 큰 잔액의 변동이 있었던 상위 10개의 잔액 변동 내역을 알고 싶을 경우 `잔액 변동 내역` 이벤트 데이터를 각각 모두 저장한 뒤 `잔액 변동 내역`을 SK로 정의
2.3 money-query-service 로직
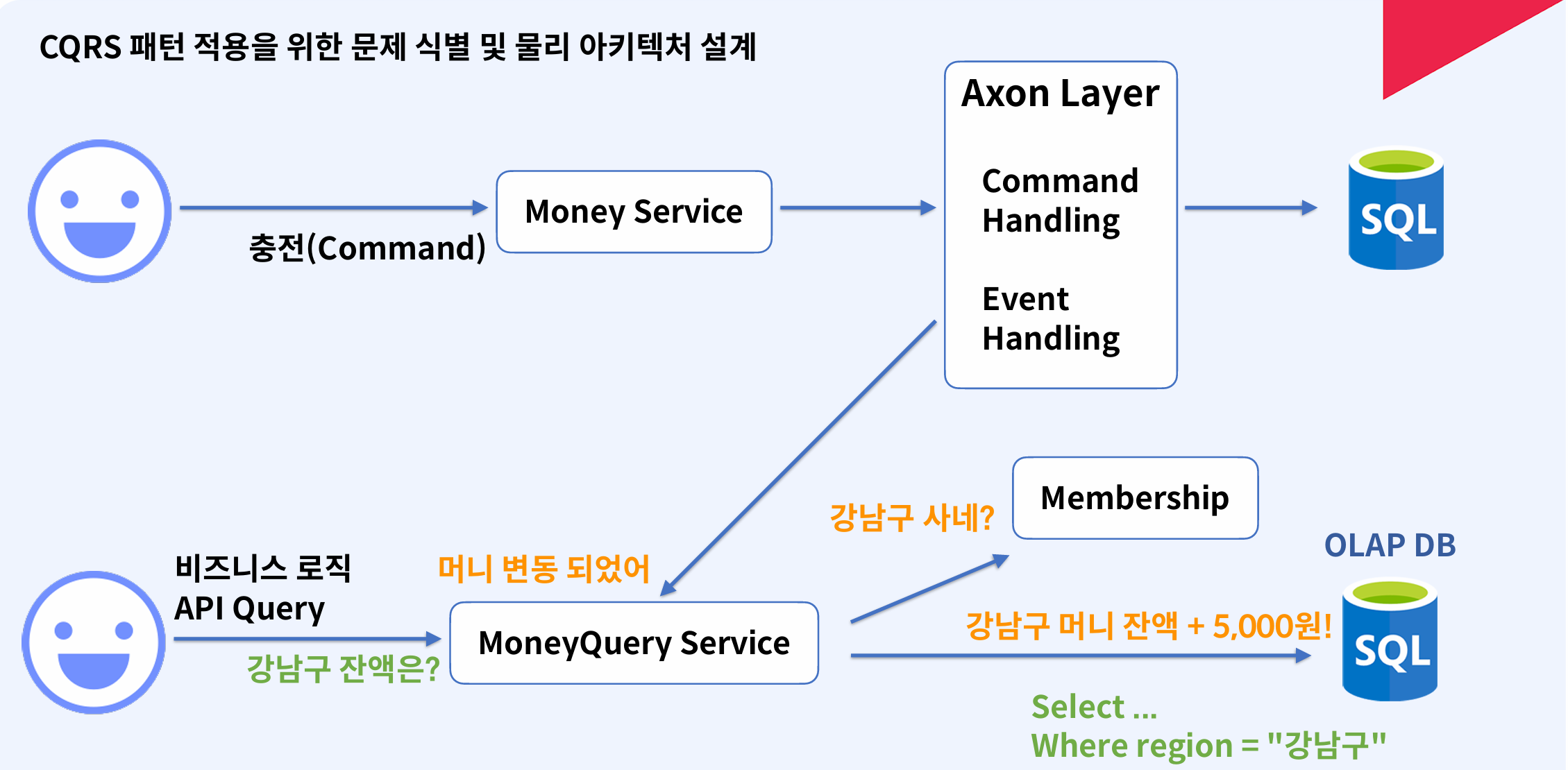
- 이벤트를 수신 받고 수신받은 이벤트의 membershipId를 조회 후 지역 정보 확인
- 확인된 지역 정보를 기준으로 DynamoDB에 데이터 insert (Command)
- DynamoDB로부터 "지역" 기준 총잔액을 얻어오기 위한 API 호출
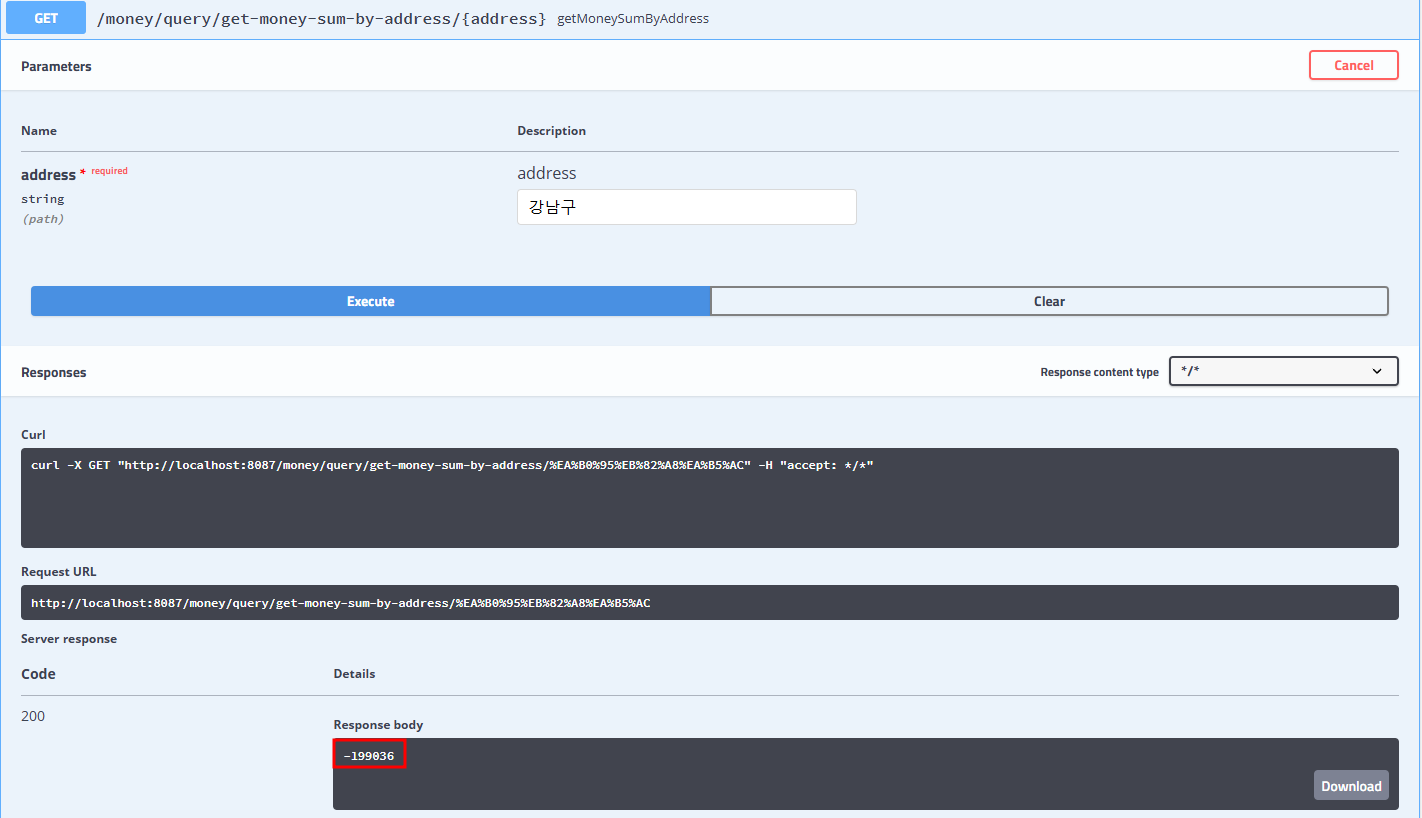
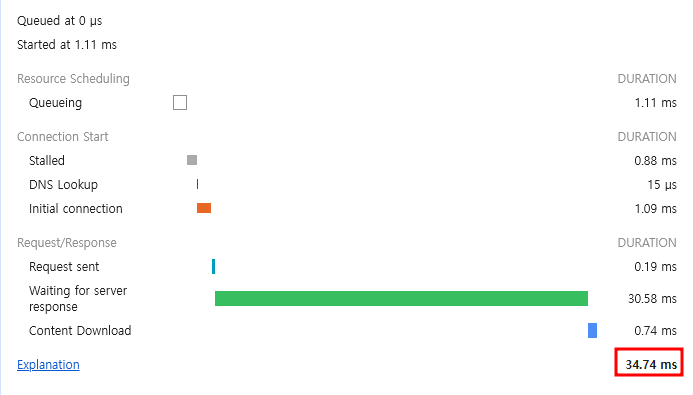
정리
- CQRS 패턴은 API Aggregation 패턴보다 대부분의 케이스에서 훨씬 구현이 복잡했지만
- CQRS 패턴 적용 시 훨씬 좋은 성능을 보이는 것을 확인 가능
- MSA 환경에서 데이터 쿼리를 위해 어떤 패턴이 적절한지 판단 후 도입하는 것을 권장
- 구현 복잡도와 성능 trade-off 관계
참고
패스트 캠퍼스 - 간편 결제 프로젝트로 한 번에 끝내는 실전 MSA 초격차 패키지 Online