[과목 I 1장 1절] 데이터 모델의 이해
1. 모델링의 이해
가. 모델링의 정의
- 사람이 살아가면서 접할 수 있는 다양한 현상들이 사람, 사물, 개념 등에 의해 발생된다고 했을 때, 모델링은 이것을 표기법에 따라 표기하는 것 자체를 의미
- 현실 세계를 추상화, 단순화, 명확화 하기 위해 일정한 표기법에 의해 표현한 기법
나. 모델링의 특징
- 모델링은 추상화, 단순화, 명확화라는 3대 특징으로 요약 가능
- 추상화: 현실세계를 일정한 형식에 맞추어 표현한다는 의미
- 단순화: 복잡한 현실 세계를 약속된 규약에 의해 제한된 표기법이나 언어로 표현하여 쉽게 이해할 수 있도록 하는 개념
- 명확화: 누구나 이해하기 쉽게 하기 위해 대상에 대한 애매모호함을 제거하고 정확하게 현상을 기술하는 것
- 정보시스템 구축에서 모델링은 계획, 분석, 설계 단계에서 업무를 분석하고 설계할 때, 이후 구축, 운영 단계에서 변경과 관리할 때 이용됨
다. 모델링의 세 가지 관점
- 시스템의 대상이 되는 업무를 분석하여 정보 시스템으로 구성하는 과정에서 업무의 내용과 정보 시스템의 모습을 적절한 표기법으로 표현하는 것을 모델링이라고 한다면, 모델링은 다음과 같이 크게 세 가지 관점으로 구분해서 볼 수 있음
- 데이터 관점: 업무가 어떤 데이터와 관련이 있는지 또는 데이터 간의 관계는 무엇인지에 대해서 모델링하는 방법
- 프로세스 관점: 실제하고 있는 업무는 무엇인지 또는 무엇을 해야 하는지를 모델링하는 방법
- 데이터와 프로세스의 상관 관점: 업무가 처리하는 일의 방법에 따라 데이터는 어떻게 영향을 받고 있는지 모델링하는 방법
이 장에서는 데이터베이스를 구축하기 위한 데이터 모델링을 중심으로 설명합니다.
2. 데이터 모델의 기본 개념 이해
가. 데이터 모델링의 정의
- 데이터 모델은 데이터베이스의 골격을 이해하고 그 이해를 바탕으로 SQL 문장을 기능과 성능적인 측면에서 효율적으로 작성하기 위해 꼭 알아야 하는 핵심 요소
- 일반적으로 데이터 모델링은 다음과 같이 다양하게 정의될 수 있음
- 정보 시스템을 구축하기 위해, 해당 업무에 어떤 데이터가 존재하는지 또는 업무가 필요로 하는 정보는 무엇인지를 분석하는 방법
- 기업 업무에 대한 종합적인 이해를 바탕으로 데이터에 존재하는 업무 규칙에 대하여 참 또는 거짓을 판별할 수 있는 사실을 데이터에 접근하는 방법, 사람, 전산화와 별개의 관점에서 이를 명확하게 표현하는 추상화 기법
- 좀 더 실무적으로 해석해 보면, 업무에서 필요로 하는 데이터를 시스템 구축 방법론에 따라 분석하고 설계하여 정보 시스템을 구축하는 과정으로 정의 가능
- 데이터 모델링을 하는 목적은 다음과 같음
- 업무 정보를 구성하는 기초가 되는 정보들을 이리정한 표기법에 따라 표현함으로써 정보 시스템 구축의 대상이 되는 업무 내용을 정확하게 분석하는 것
- 분석한 모델을 토대로 실제 데이터베이스를 생성하여 개발 및 데이터 관리에 사용하기 위함
- 정리하면 데이터 모델링은 단지 데이터베이스만을 구축하기 위한 용도로만 쓰이는 것이 아니라, 데이터 모델링 자체로서 업무를 설명하고 분석하는 부분에도 매우 중요한 의미를 갖고 있음
나. 데이터 모델이 제공하는 기능
- 업무를 분석하는 관점에서 데이터 모델이 제공하는 기능은 다음과 같음
- 시스템을 현재 또는 원하는 모습으로 가시화하도록 지원
- 시스템의 구조와 행동을 명세화할 수 있게 함
- 시스템을 구축하는 구조화한 틀을 제공
- 시스템 구축 과정에서 결정한 것을 문서화
- 다양한 영역에 집중하기 위해 다른 영역의 세부 사항은 숨기는 다양한 관점을 제공
- 특정 목표에 따라 구체화한 상세 수준의 표현 방법을 제공
3. 데이터 모델링의 중요성과 유의점
- 데이터 모델링이 중요한 이유는 파급 효과, 복잡한 정보 요구 사항의 간결한 표현, 그리고 데이터 품질로 정리할 수 있음
가. 파급 효과 (Leverage)
- 시스템 구축이 완성되어 가는 시점에서는 많은 애플리케이션들의 테스트를 수행하고 대규모 데이터 이행을 성공적으로 수행하기 위한 많은 단위 테스트들이 반복되며 각 단위 테스트들이 성공적으로 완료되면 이 전체를 묶어서 병행 테스트와 통합 테스트를 하게 됨
- 데이터 모델의 형태에 따라서 그 영향 정도는 차이가 있겠지만, 이 시기의 데이터 구조의 변경으로 인한 일련의 변경 작업은 전체 시스템 구축 프로젝트에서 큰 위험요소가 아닐 수 없음
- 이를 위해 데이터 구조의 변경에 따른 표준 영향 분석, 응용 변경 영향 분석 등 많은 영향 분석이 일어남
- 이후에 해당 분야의 실제적인 변경 작업이 이루어짐
- 따라서 시스템 구축 작업 중에서 다른 어떤 설계 과정보다 데이터 설계가 중요하다고 볼 수 있음
나. 복잡한 정보 요구 사항의 간결한 표현 (Conciseness)
- 데이터 모델은 구축할 시스템의 정보 요구 사항과 한계를 가장 명확하고 간결하게 표현할 수 있는 도구
- 데이터 모델은 건축물로 비유하자면 설계 도면에 해당하며 많은 사람들이 건축물 설계 도면을 공유하면서 설계자의 생각대로 일사불란하게 움직여 아름다운 건축물을 만들어내는 것에 비유할 수 있음
- 데이터 모델은 시스템을 구축하는 많은 관련자가 설계자의 의도대로 정보 요구 사항을 이해하고 이를 운용할 수 있는 애플리케이션을 개발하고, 데이터 정합성을 유지하는 것
- 이상적으로 역할을 할 수 있는 모델이 갖추어야 할 가장 핵심은 ``정보 요구 사항이 정확하고 간결하게 표현되어야 함`
다. 데이터 품질 (Data Quality)
- 데이터베이스에 담겨 있는 데이터는 기업의 중요한 자산이며 데이터는 기간이 오래되면 될수록 활용가치는 훨씬 올라감
- 오래도록 저장된 데이터가 그저 그런 데이터, 정확성이 떨어지는 데이터일 경우 해당 데이터로 얻을 수 있었던 소중한 비즈니스의 기회 상실로 연결될 수 있으므로 데이터 품질이 중요함
- 데이터 품질의 문제는 데이터 구조가 설계되고 초기에 데이터가 조금 쌓일 때에는 인지하지 못하는 경우가 대부분
- 이러한 데이터의 문제는 오랜 기간 숙성된 데이터를 전략적으로 활용하려고 하는 시점에 대두됨
- 데이터 품질의 문제가 야기되는 중대한 이유 중 하나가 바로 데이터 구조 때문
- 중복 데이터의 미정의
- 데이터 구조에서 비즈니스 정의의 불충분
- 동일한 성격의 데이터를 통합하지 않고 분리함으로써 나타나는 데이터 불일치
- 데이터 모델링을 할 때 유의할 점은 다음과 같음
- 중복: 데이터 모델은 같은 데이터를 사용하는 사람, 시간, 장소를 파악하는데 도움을 주며 이러한 지식 응용은 데이터베이스가 여러 장소에 같은 정보를 저장하는 잘못을 하지 않도록 함
- 비유연성: 데이터 모델을 어떻게 설계했느냐에 따라 사소한 업무 변화에도 데이터 모델이 수시로 변경됨으로써 유지보수의 어려움을 가중시킬 수 있음, 데이터 정의를 데이터의 사용 프로세스와 분리함으로써 데이터 모델링은 데이터 혹은 프로세스의 작은 변화가 애플리케이션과 데이터베이스에 중대한 변화를 일으킬 가능성을 줄일 수 있음
- 비일관성: 데이터의 중복이 없더라도 개발자가 다른 데이터와 모순된다는 고려 없이 일련의 데이터를 수정할 수 있기 때문에 비일관성은 발생할 수 있음, 이에 따라 데이터 모델링을 진행할 때 데이터와 데이터 간 상호 연관 관계에 대한 명확한 정의를 함으로써 이러한 위험을 사전에 예방할 수 있음
4. 데이터 모델링의 3단계 진행
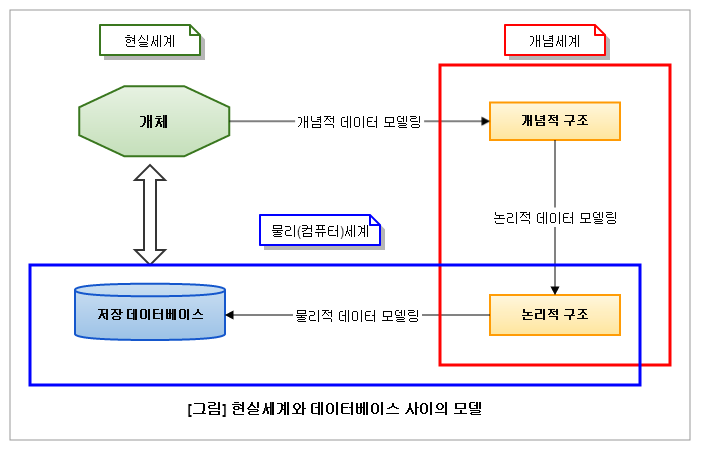
- 현실세계에서 데이터베이스까지 만들어지는 과정은 아래 그림과 같이 시간에 따라 진행되는 과정
- 추상화 수준에 따라 개념적 데이터 모델, 논리적 데이터 모델, 그리고 물리적 데이터 모델로 정의할 수 있음
부연 설명
- 처음 현실 세계에서 추상화 수준이 높은 상위 수준을 형상화하기 위해 개념적 데이터 모델링을 전개함
- 개념적 데이터 모델은 추상화 수준이 높고 업무 중심적이고 포괄적인 수준의 모델링
- EA 기반의 전사적인 데이터 모델링을 전개할 때는 더 상위 수준인 개괄적인 데이터 모델링을 먼저 수행하고, 이후에 업무 영역에 따른 개념적 데이터 모델링을 전개
- 엔티티 중심의 상위 수준의 데이터 모델이 완성되면, 업무의 구체적인 모습과 흐름에 따라 구체화한 업무 중심의 데이터 모델을 만들어내며 이것을 논리적인 데이터 모델링이라고 부름
- 논리적인 데이터 모델링 이후 데이터베이스의 저장 구조에 따른 테이블 스페이스 등을 고려한 방식을 물리적인 데이터 모델링이라고 부름
가. 개념적 데이터 모델링
- 개념적 데이터베이스 설계는 조직, 사용자의 데이터 요구사항을 찾고 분석하는 데서 시작함
- 해당 과정은 어떤 자료가 중요하고 또 어떤 자료가 유지되어야 하는지를 결정하는 것도 포함
- 해당 단계에서 중요한 활동은 핵심 엔티티와 그들 간의 관계를 발견하고, 그것을 표현하기 위해서 엔티티-관계 다이어그램을 생성하는 것
- 개념 데이터 모델을 통해 조직의 데이터 요구를 공식화하는 것은 두 가지의 중요한 기능을 지원
- 개념 데이터 모델은 사용자와 시스템 개발자가 데이터 요구 사항을 발견하는 것을 지원
- 개념 데이터 모델은 현 시스템이 어떻게 변형되어야 하는가를 이해하는데 유용함
나. 논리적 데이터 모델링
- 데이터베이스 설계 프로세스의 Input으로서 비즈니스 정보의 논리적인 구조와 규칙을 명확하게 표현하는 기법
- 물리적 스키마 설계에 앞서 ‘데이터 모델’이 최종적으로 완성된 상태를 의미하며, 시스템 구축 전반에 걸친 초기 업무 조사부터 중요한 설계 의사 결정을 지원하는 도구
- 논리 데이터 모델링의 핵심은 어떻게 데이터에 접근하고, 누가 데이터에 접근하며, 그러한 접근의 전산화와는 독립적으로 다시 말해서 누가, 어떻게, 그리고 전산화와는 별개로 비즈니스 데이터에 존재하는 사실들을 인식하여 기록하는 것
- 논리적 데이터 모델링 단계에서 수행하는 또 한 가지 중요한 활동은 정규화
- 정규화는 논리 데이터 모델 상세화 과정의 대표적인 활동으로 논리 데이터 모델의 일관성을 확보하고 중복을 제거하여 속성들이 가장 적절한 엔티티에 배치되도록 함으로써 보다 더 신뢰성 있는 데이터 구조를 얻는데 목적이 있음
- 논리 데이터 모델의 상세화는 식별자 확정, 정규화, M:M 관계 해소, 참조 무결성 규칙 정의 등을 들 수 있음
다. 물리적 데이터 모델링
- 논리 데이터 모델이 데이터 저장소로서 어떻게 컴퓨터 하드웨어에 표현되리 것인가를 다룸
- 데이터가 물리적으로 컴퓨터에 어떻게 저장될 것인가에 대한 정의를 물리적 스키마라고 부름
- 해당 단계에서 결정되는 것은 테이블, 컬럼 등으로 표현되는 물리적인 저장 구조와 사용될 저장 장치, 자료를 추출하기 위해 사용될 접근 방법 등이 있음
실질적인 현실 프로젝트에서는 개념적 데이터 모델링 > 논리적 데이터 모델링 > 물리적 데이터 모델링으로 수행하는 경우는 드물고 개념적 데이터 모델링과 논리적 데이터 모델을 한꺼번에 수행하여 논리적인 데이터 모델링으로 수행하는 경우가 대부분입니다.
5. 프로젝트 생명주기에서 데이터 모델링
- 폭포수 (Waterfall) 기반에서는 데이터 모델링의 위치가 분석과 설계 단계로 구분하여 명확하게 정의할 수 있음
- 정보 공학이나 구조적 방법론에서는 보통 분석 단계에서 업무 중심의 논리적인 데이터 모델링을 수행하고, 설계 단계에서 하드웨어와 성능을 고려한 물리적 데이터 모델링을 수행
- RUP (Rational Unified Process)와 같은 나선형 모델에서는 업무 크기에 따라 논리 데이터 모델과 물리적 데이터 모델이 분석 및 설계 단계 양쪽에서 수행되며, 일반적으로 분석 단계에서 논리적인 데이터 모델이 더 많이 수행됨

부연 설명
- 데이터 축과 애플리케이션 축으로 구분하여 프로젝트를 진행하면서 각각에 도출한 사항은 상호검증을 지속적으로 수행하면서 단계별 완성도를 높여감
- 객체지향 개념은 데이터와 프로세스를 한꺼번에 바라보면서 모델링을 전개하므로 데이터 모델링과 프로세스 모델링을 구분하지 않고 일체형으로 진행
6. 데이터 모델링에서 데이터 독립성의 이해
가. 데이터 독립성의 필요성
- 어떤 단위에 대해 독립적인 의미를 부여하고 그것을 효과적으로 구현할 경우 자신이 가지는 고유한 특징을 명확하게 할 뿐만 아니라, 다른 기능의 변경으로부터 쉽게 변경되지 않고 자신의 고유한 기능을 가지고 기능을 제공할 수 있는 장점을 갖게 됨
- ex) SOA의 `서비스`라고 하는 단위는 독립적인 비즈니스로 처리 가능한 단위를 서비스로 정의하고, 그것이 다른 서비스에 비해 독립성을 구성하여 개별로도 의미를 갖고, 다른 서비스와 결합하여 BPM과 같이 프로세스로 제공해도 의미가 있는 단위로 제공하는 것
- 데이터 독립성에는 지속적으로 증가하는 유지보수 비용을 절감하고 데이터 복잡도를 낮추며 중복된 데이터를 줄이기 위한 목적이 있음
- 끊임없이 나오는 사용자 요구 사항에 대해 화면과 데이터베이스 간에 서로 독립성을 유지하기 위한 목적으로 데이터 독립성 개념이 출현함
- 데이터 독립성을 확보하면 다음고 같은 효과를 얻을 수 있음
- 각 뷰의 독립성을 유지하고, 계층별 뷰에 영향을 주지 않고 변경 가능
- 단계별 스키마에 따라 데이터 정의어 (DDL)와 데이터 조작어 (DML)가 다름을 제공
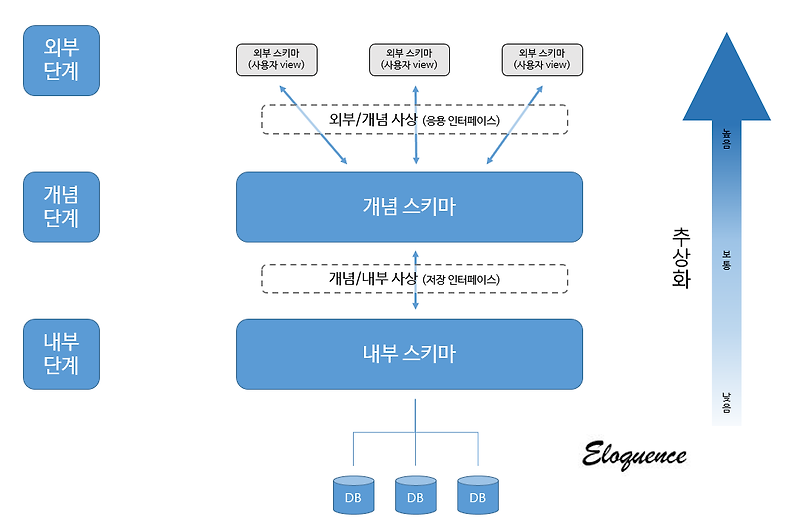
나. 데이터베이스 3단계 구조
- 데이터 독립성의 3단계에서 외부 단계는 사용자가 처리하고자 하는 데이터 유형, 관점, 그리고 방법에 따라 다른 스키마 구조를 가지고 있음
- 개념 단계는 사용자가 처리하는 데이터 유형의 공통적인 사항을 처리하는 통합된 뷰를 스키마 구조로 디자인한 형태
- 우리가 쉽게 이해하는 데이터 모델은 사용자가 처리하는 통합된 뷰를 설계하는 도구로 이해해도 무방
- 내부적 단계는 데이터가 물리적으로 저장된 방법에 대한 스키마 구조
다. 데이터 독립성 요소
| 항목 | 내용 | 비고 |
| 외부 스키마 (External Schema) |
뷰 단계 여러 개의 사용자 관점으로 구성 DB의 개개 사용자나 응용 프로그래머가 접근하는 DB 정의 |
사용자 관점 접근하는 특성에 따른 스키마 구성 |
| 개념 스키마 (Conceptual Schema) |
조직 내의 모든 데이터 요구사항을 하나의 통일된 모델로 표현함으로써 데이터 관리의 효율성을 높이고, 각 사용자 및 응용 시스템이 일관된 데이터를 참조할 수 있도록 하는 핵심적인 역할을 수행 | 통합 관점 |
| 내부 스키마 (Internal Schema) |
내부 단계와 내부 스키마로 구성됨 물리적 장치에서 데이터가 실제적으로 저장된느 방법을 표현한 스키마 |
물리적 저장 구조 |
라. 두 영역의 데이터 독립성
| 독립성 | 내용 | 특징 |
| 논리적 독립성 | 논리적 구조가 변경되어도 응용 프로그램에 영향 없음 | 사용자 특성에 맞는 변경 가능 통합 구조 변경 가능 |
| 물리적 독립성 | 저장 장치의 구조 변경은 응용 프로그램과 개념 스키마에 영향 없음 | 물리적 구조 영향 없이 개념 구조 변경 가능 |
마. 사상
| 사상 | 내용 | 예 |
| 논리적 사상 (외부적, 개념적 사상) |
외부적 뷰와 개념적 뷰의 상호 관련성 정의 | 사용자가 접근하는 형식에 따라 다른 타입의 필드를 가질 수 있음 개념적 뷰의 필드 타입은 변화가 없음 |
| 물리적 사상 (개념적, 내부적 사상) |
개념적 뷰와 저장된 DB의 상호 관련성 정의 | 만약 저장된 DB 구조가 바뀐다면 개념적, 내부적 사상이 바뀌어야 함 그래야 개념적 스키마가 그대로 남아 있게 됨 |
7. 데이터 모델링의 중요한 세 가지 개념
가. 데이터 모델링의 세 가지 요소
- 데이터 모델링을 구성하는 세 가지 중요한 개념은 다음과 같음
- 업무가 관여하는 어떤 것 (Things)
- 어떤 것이 가지는 성격 (Attributes)
- 업무가 관여하는 어떤 것 간의 관계 (Relationships)
- 세상의 모든 사람, 사물, 개념 등은 어떤 것, 어떤 것 같의 관계와 성격을 구분함으로써 분류할 수 있음
- 이러한 원리, 즉 자연계에 존재하는 모든 유형의 정보들을 세 가지 관점의 접근 방법을 통해 모델링을 진행하는 것
나. 단수와 집합 (복수)의 명명
| 개념 | 복수, 집합 개념 | 개별, 단수 개념 |
| 어떤 것 (Thing) |
Entity Type | Entity |
| Entity | Instance Occurrence |
|
| 어떤 것 간의 연관 (Association between Things) |
관계 (Relationship) | Pairing |
| 어떤 것의 성격 (Characteristic of a Thing) |
속성 (Attribute) | 속성값 (Attribute Value) |
8. 데이터 모델링의 이해 관계자
가. 이해 관계자의 데이터 모델링 중요성 인식
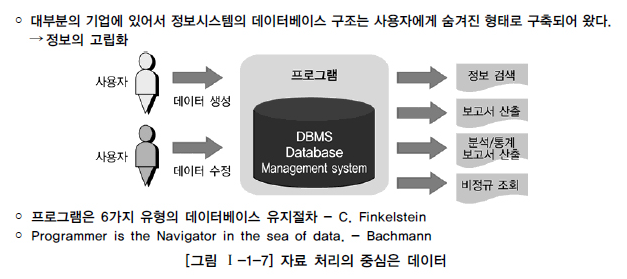
- 실제 업무 시스템을 구축하는 실전 프로젝트에서는 DBA (DataBase Administrator)가 데이터 모델링을 전적으로 하는 케이스는 거의 없고 업무 시스템을 개발하는 응용 시스템 개발자가 데이터 모델링을 진행하는 케이스가 대부분
- 데이터 모델링이라는 과정이 단지 DB를 설계한다는 측면보다 업무를 이해하고 분석하여 표현하는 것이 중요하고, 표현된 내용을 바탕으로 프로젝트 관련자와 의사소통하고 프로그램이나 다른 표기법과 비교 검증하는 일을 수행하는 등 많은 시간을 업무를 분석하고 설게 하는 데 할애하기 때문
- 이에 따라 업무 영역별 개발팀에서 보통 데이터 모델링을 진행하게 됨
- 이와 같이 응용 시스템을 개발하는 모든 시스템 엔지니어가 뎅터 모델을 하거나 할 기회가 있음에도 대부분의 사람들은 데이터 모델에 많은 관심을 가지지 않지만 정보 시스템을 개발할 때 데이터 모델링, DB 구축, 그리고 구축된 데이터의 적절한 활용은 다른 어떤 업무보다 중요함
- Bachmann은 `프로그래머는 데이터 집합의 탐색자`라고 하였고 그만큼 데이터에 대한 중요성을 높게 평가하는 것
나. 데이터 모델링의 이해 관계자
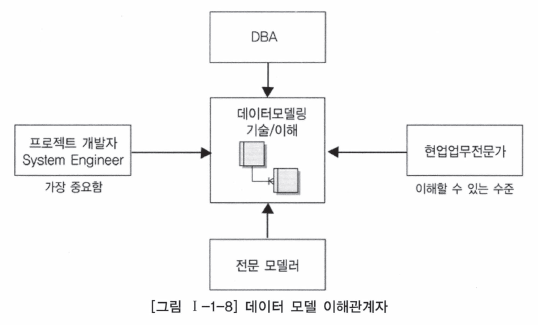
- 정보 시스템을 구축하는 모든 사람은 데이터 모델링도 전문적으로 할 수 있거나 적어도 완성된 모델을 정확하게 해석할 수 있어야 함
- IT 기술에 종사하거나 전공하지 않았더라도 해당 업무에서 정보화를 추진하는 위치에 있는 살마도 데이터 모델링에 대한 개념 및 세부 사항에 대해 어느 정도 지식을 가지고 있어야 함
9. 데이터 모델의 표기법인 ERD 이해
가. 데이터 모델 표기법
- 데이터 모델에 대한 표기법으로 1976년 Peter Chen이 ER 모델 (Entity-relationship model)이라는 표기법을 만듦
- 엔티티를 사각형으로 표현하고 관계를 마름모 속성을 타원형으로 표현하는 이 표기법은 데이터 모델링에 대한 이론을 배울 때 많이 활용됨
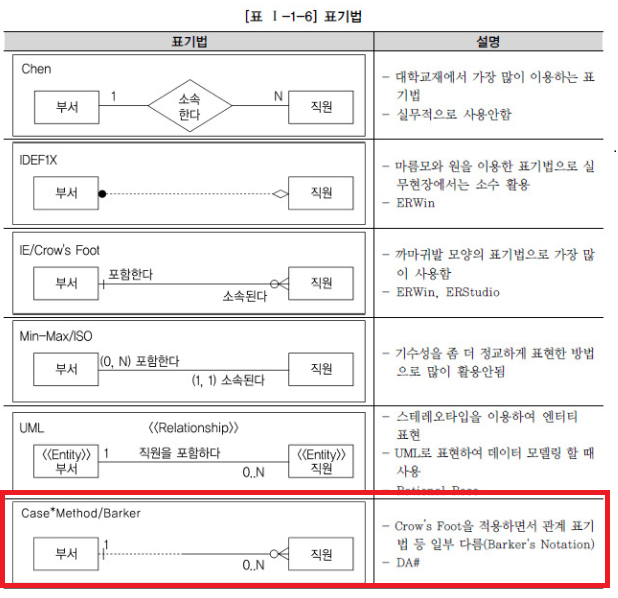
나. ERD 표기법으로 모델링하는 방법
- ERD (Entity Relationship Diagram)는 각 업무 분석에서 도출된 엔티티와 엔티티 간의 관계를 이해하기 쉽게 도식화된 다이어그램으로 표시하는 방법
- 실제 프로젝트에서는 분석된 엔티티와 관계, 속성 정보가 바로 ERD에 표현되며, 내부 프로젝트 인원이나 해당 업무 고객과 대화할 때 핵심 업무 산출물로 항상 이용됨
A. ERD 작업 순서
- ERD는 엔티티와 엔티티 사이의 관계가 있는 정보를 나타내므로 두 개를 이용하여 작성하고, 이에 따라 기본 키와 외래 키를 ERD 규칙에 따라 기술함
- 엔티티는 사각형으로 표기하여 기술
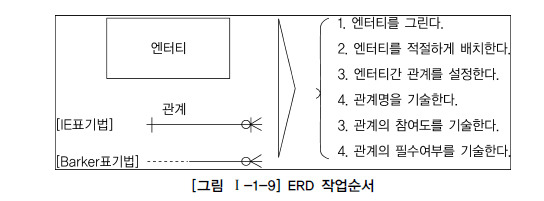
B. 엔티티 배치
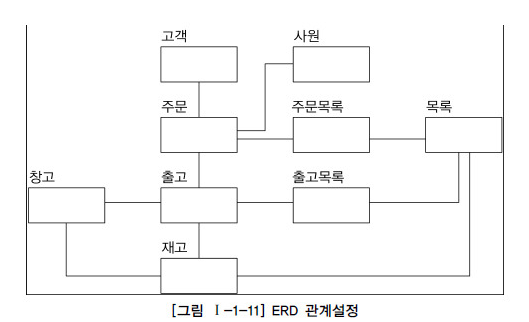
- 일반적으로 사람의 눈은 왼쪽에서 오른쪽, 위쪽에서 아래쪽으로 이동하는 경향이 있으므로 데이터 모델링에서도 가장 중요한 엔티티를 왼쪽 상단에 배치하고, 이 것을 중심으로 다른 엔티티를 나열하면서 전개하면 사람의 눈이 따라가기에 편리한 데이터 모델링을 할 수 있음

부연 설명
- 가장 중요한 엔티티인 고객과 주문을 좌상단에 배치하여 다른 엔티티를 연결하는 방식으로 그림
- 주문에 따라 출고가 이루어졌으므로 주문이 위에 출고가 아래에 위치함
- 주문, 출고, 주문 목록, 출고 목록이 업무의 중심 엔티티에 해당하고 보통 업무 흐름에 있어서 중심이 되는 엔티티는 타 엔티티와 많은 관계를 가지고 있으므로 중앙에 배치
- 창고, 고객, 사원, 재고와 같이 업무를 진행하는 중심 엔티티와 관계를 갖는 엔티티들은 중심에 배치된 엔티티들 주위에 배치
C. ERD 관계의 연결
- 엔티티 배치가 완료되면 관계를 정의한 분석서를 기반으로 서로 관련 있는 엔티티 간에 관계를 설정
- 초기에는 모두 기본 키로 속성이 상속되는 식별자 관계를 설정
- 중복되는 관계와 순환하는 관계가 발생하지 않도록 유의하여 작성
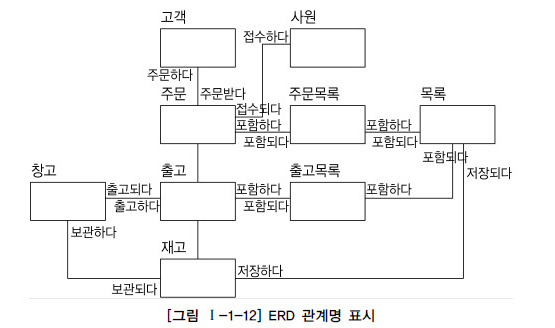
D. ERD 관계명의 표시
- 관계 설정이 완료되면 연결된 관계에 관계명을 부여
- 관계명은 현재형을 사용하고 '에', '이다', '가진다'와 같이 지나치게 포괄적인 용어는 사용하지 않는 것을 권장
- 관계의 명칭이 나타나지 않아도 ERD의 흐름이 명확하게 드러나기 때문에 실제 프로젝트에서는 관계의 명칭을 크게 고려하지 않아도 무방함
E. ERD 관계 관계 차수와 선택성 표시
- 관계에 대한 이름을 모두 지정하였으면 관계가 참여하는 성격 중 엔티티 내 인스턴스들이 얼마나 관계에 참여하는지를 나타내는 관계 차수 (Cardinality)를 표현
- IE 표기법으로는 하나의 관계는 실선으로 표기하고 바커 표기법으로는 점선과 실선을 혼합하여 표기
- Many의 관계는 까마귀 발과 같은 모양으로 그려주며
- 관계의 필수, 선택 표시는 관계선에 원을 표현하여 ERD를 그림 ( IE 표기법에서 보통 원이 선택을, 막대나 선이 필수를 나타냄)
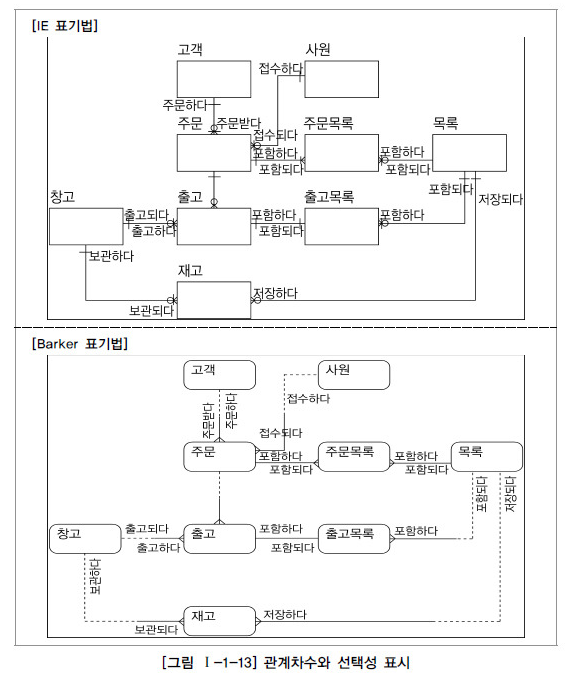
10. 좋은 데이터 모델의 요소
- 특정 데이터 모델이 업무 환경에서 요구하는 사항을 얼마나 잘 시스템적으로 구현할 수 있는가를 객관적으로 평가할 수 있다면, 가장 좋은 평가 방법일 것이지만 현실에는 객관적으로 평가할 수 있는 기준이 존재하지 않음
- 이러한 상황에서 대체적으로 좋은 데이터 모델이라고 말할 수 있는 몇 가지의 요소들은 다음과 같음
가. 완전성
- 업무에서 필요하로 하는 모든 데이터가 데이터 모델에 정의되어 있어야 함 (Completeness)
- 데이터 모델을 검증하기 위해서 가장 먼저 확인해야 할 부분이며 해당 기준이 충족되지 못할 경우 다른 어떤 평가 기준도 의미가 없어짐
나. 중복 배제
- 하나의 데이터베이스 내 동일한 사실은 반드시 한 번만 기록해야 됨 (Non-Redundancy)
- ex) 하나의 테이블에서 `나이` 칼럼과 `생년월일` 칼럼이 동시에 존재하면 데이터 중복
다. 업무 규칙
- 데이터 모델에서 매우 중요한 요소 중 하나가 데이터 모델링 과정에서 도출되고 규명되는 수많은 업무 규칙 (Business Rules)을 데이터 모델에 표현하고 이를 해당 데이터 모델을 활용하는 모든 사용자가 공유할 수 있도록 제공하는 것
- 특히 데이터 아키텍처에서 언급되는 논리 데이터 모델에서 이러한 요소들이 포함되어야 함은 매우 중요
- ex) 보험사의 사원들은 매월 기본급, 상여금, 수당, 수수료 등 다양한 급여 항목을 지급받으며, 이 지급 과정은 사원 구분(예: 내근, 설계사, 계약직, 대리점 등)에 따라 자동 지급되는 규칙에 의해 데이터로 관리됨
라. 데이터 재사용
- 데이터의 재사용성을 향상시키기 위해서는 데이터의 통합성과 독힙성에 대한 충분한 고려가 필요
- 현재 대부분의 회사에서 진행하고 있는 신규 정보 시스템 구축 작업은 회사 전체 관점에서 공통 데이터를 도출하고 이를 전 영역에서 사용하기에 적절한 형태로 설계하여 이루어짐
- 이러한 형태의 데이터 설계에서 가장 중요하게 대두되는 것이 통합 모델이며 통합 모델이어야만 데이터 재사용성을 높일 수 있음
- 데이터가 애플리케이션에 대해 독립적으로 설계되어야만 데이터 재사용성 (Data Reusability)을 높일 수 있음
- 정보 시스템은 비즈니스 변화에 최적으로 적응하도록 끊임없이 변경을 요구받기 때문에 많은 기업이 정보 시스템을 구축하는 과정에서 데이터 구조의 확장성, 유연성에 힘을 기울이고 있음
- 결국 현대의 기업들이 동종의 타 기업으로부터 경쟁 우위를 가지려면 구축하는 데이터 모델은 이러한 외부의 업무 환경 변화에 대해 유연하게 대응할 수 있어야 함
- 확장성을 담보하기위해서는 데이터 관점의 통합이 불가피
- 특히 정보 시스템에서의 `행위의 주체`가 되는 집합의 통합, `행위의 대상`이 되는 집합의 통합, `행위 자체`에 대한 통합 등은 전체 정보 시스템의 안정성 및 확장성을 좌우하는 가장 중요한 요소
- 데이터 모델이 갖추어야 하는 중요한 요소 중에 하나는 기업이 관리하고자 하는 데이터를 합리적으로 균형이 있으면서도 단순하게 분류하는 것
- 간결한 모델의 기본적인 전제는 통합
- 합리적으로 잘 정돈된 방법으로 데이터를 통합하여 데이터의 집합을 정의하고, 이를 데이터 모델로 잘 표현 및 활용한다면 웬만한 업무 변화에도 데이터 모델이 영향을 받지 않고 운용할 수 있음
마. 의사소통
- 데이터 모델은 대상으로 하는 업무를 데이터 관점에서 분석하고 이를 설계하여 나오는 최종 산출물
- 데이터 분석 과정에서 자연스럽게 많은 업무 규칙들이 도출됨
- 이 과정에서 도출되는 많은 업무 규칙들은 데이터 모델에서 엔티티, 서브 타입, 속성, 그리고 관계 등의 형태로 최대한 자세하게 표현되어야 함
- 정보 시스템 운용 및 관리하는 많은 관련자들이 설계자가 정의한 많은 업무 규칙들을 동일한 의미로 받아들이고 활용할 수 있게 하는 역할을 하게 됨
- 데이터 모델이 진정한 의사소통 (Communication)의 도구로서의 역할을 수행
바. 통합성
- 가장 바람직한 데이터 구조의 형태는 동일한 데이터를 조직 전체에서 한 번만 정의되고, 이를 여러 다른 영역에서 참조 및 활용하는 것 (Integration)
- 물론 이 때 성능 등의 부가적인 목적을 위해 의도적으로 데이터를 중복시키는 경우가 존재할 수 있음
- 동일한 성격의 데이터를 한 번만 정의하기 위해서는 공유 데이터에 대한 구조를 여러 업무 영역에서 공동으로 사용하기 용이하게 설계할 수 있어야 함
- 이 때문에 데이터 아키텍처의 중요성이 한층 더 부각되고 있음
참고
SQL 전문가 가이드 2020 개정판 - 한국데이터산업진흥원