딥러닝/테디노트의 RAG 비법노트
RAG 프로세스 이해하기
꾸준함.
2025. 3. 4. 10:39
RAG (Retrieval Augmented Generation)
- 질문이나 요청을 처리할 때, 기존의 LLM 결과에 추가적으로 검색한 문서 정보인 context를 결합해 보다 정확하고 구체적인 답변을 생성하는 기법
- 최신 정보를 효과적으로 활용하기 위해 정보를 참조하는 방식으로, 단순히 기존 모델의 사전 학습된 데이터에 의존하지 않고 정보를 실시간으로 적용
- RAG는 외부 DB에서 최신 자료를 검색해 도메인별 최신 문서 및 연구 자료 등을 답변 근거로 삼음으로써, 대규모 언어 모델이 사전 학습 지식에만 의존할 때 발생할 수 있는 할루시네이션 문제를 효과적으로 줄여줌
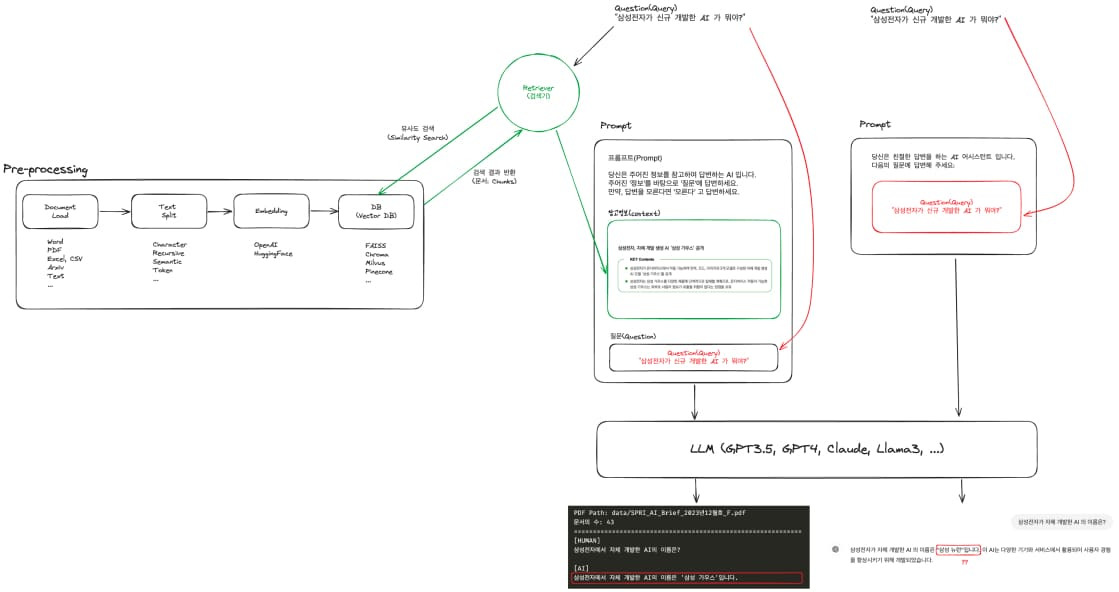
1. Pre-processing 단계
전처리 과정은 원본 문서를 LLM이 활용할 수 있도록 형태를 가공하는 작업입니다.
- Document Load: Word, PDF, Excel이나 CSV 같은 파일을 읽어 들인 후 텍스트 형식으로 변환하는 과정 (이미지는 OCR 등을 통해 텍스트화)
- Text Split: 문서 전체를 토큰 단위로 분할하여 작은 청크로 나누는 과정, 이렇게 하면 검색 정확도를 높이고, LLM에게 필요한 텍스트를 쉽게 제공 가능
- Embedding: 분할된 텍스트 청크를 벡터화하는 과정, OpenAI의 임베딩 API나 다른 임베딩 모델을 사용해 각 청크를 일정 길이의 벡터로 변환하며 해당 벡터는 텍스트 의미 (Semantic)를 수치적으로 표현
- Vector DB: 임베딩된 벡터를 FAISS, Chroma, Pinecone 등과 같은 벡터 데이터베이스에 저장, 추후 질의가 들어왔을 때 해당 DB에서 질문과 의미적으로 가까운 청크들을 조회
2. 벡터 DB를 활용한 검색 (Retrieval) 단계
사용자가 질의 (Query)를 하면 다음 단계들이 뒤따릅니다.
- Query Embedding: 사용자가 입력한 질의도 동일한 임베딩 모델로 벡터화 진행
- Similarity Search: 질의의 벡터와 DB 내의 텍스트 청크 벡터들을 비교, 코사인 유사도나 맥스 마지널 릴러번스와 같은 거리 측정 방식을 통해 질문과 가장 의미가 유사한 청크들을 검색
- Reference Context: 가장 유사도가 높은 청크 몇 개가 선택되어, 최종 답변을 생성하는 데 필요한 context로 사용
3. Prompt 구성 단계
실제 RAG 시스템에서 중요한 점은 검색된 문맥 (Context)이 최종적으로 LLM에게 전달되는 Prompt에 결합된다는 것입니다.
- 시스템 프롬프트나 지시 사항 먼저 설정
- 이후 검색으로 얻어진 텍스트 청크 (context)가 LLM에 전달할 토큰으로 추가
- 마지막으로 사용자의 원 질문 (Query)을 함께 결합하여 LLM에 넘김
이처럼 "문맥 + 사용자 질의" 형태의 프롬프트를 구성함으로써, LLM이 일반 모델 답변보다 훨씬 정확하고 문맥에 맞는 답변을 생성하도록 지원합니다.
4. LLM 응답 생성 단계
최종적으로 LLM이 Prompt 구성 단계에서 생성한 '프롬프트 (문맥 + 질문)'를 입력받고 답변을 생성합니다.
- RAG 방식에서는 검색된 외부 데이터가 context로 추가 제공되므로, 최신 정보나 특정 전문 자료를 활용한 답변도 가능
- 즉, 모델 자체가 학습된 시점 이후 업데이트가 필요했던 정보도 context를 통해 해결 가능
RAG의 8단계 프로세스
RAG 프로세스는 크게 사전 준비단계와 런타임 단계로 구분할 수 있습니다.
1. 사전 준비단계
- Document Loader: 해당 단계에서는 외부 데이터 소스에서 필요한 문서를 불러오고 초기 처리를 진행
- Text Splitter: 불러온 문서를 처리 가능한 작은 단위로 분할 (텍스트 분할과 chunk overlap을 통해 정보의 효율적 검색과 임베딩을 용이하게 함)
- Embedding: 각 문서 또는 문서의 일부를 벡터 형태로 변환하여, 문서의 의미를 수치화
- Vector DB 저장: 임베딩된 벡터들을 데이터베이스에 저장하여 요약된 키워드를 색인화

2. 런타임 단계
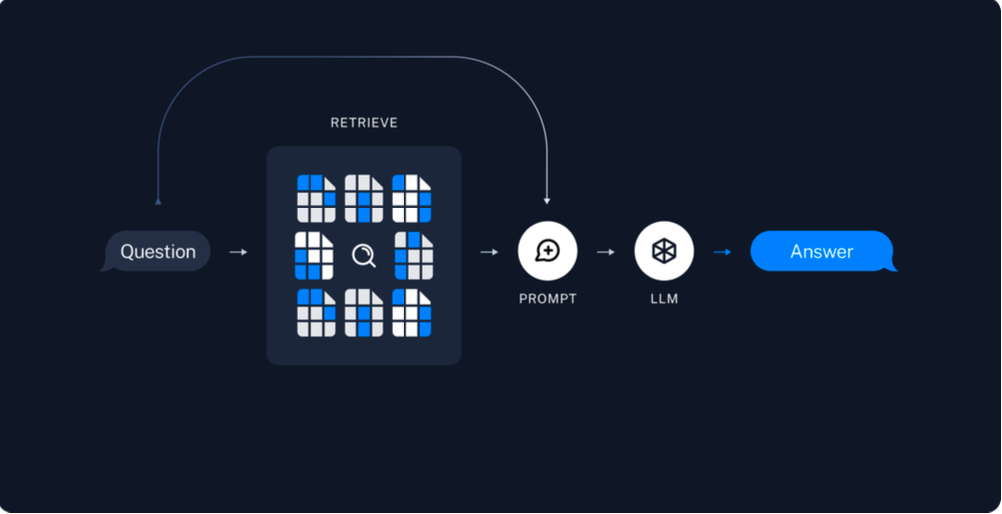
- Retriever: 질의가 주어지면, 관련된 벡터를 벡터 데이터베이스에서 조회
- Prompt: 검색된 정보를 바탕으로 언어 모델을 위한 질문을 구성
- LLM: 구성된 프롬프트를 사용하여 언어 모델이 답변을 생성
- Chain 생성: 이전의 모든 과정을 하나의 파이프라인으로 묶어주는 체인 생성
- 체인 생성은 사용자의 질문을 Retriever로 입력하여 유사한 단락을 반환하고, 이를 프롬프트에 포함하는 과정을 종합하는 것
- 질문 입력 시스템은 두 개의 분기로 나뉘며, 하나는 Retriever로 입력된 질문을 임베딩 표현 으로 변환해 비슷한 단락을 반환받는 역할 수행
- 두 번째 분기는 프롬프트에 직접 질문을 전달하는 역할을 수행하며, 프롬프트는 질문과 검색된 문서 단락으로 구성
- Retriever는 질문에 유사도 높은 단락들을 반환하며, 이들은 context에 묶여 프롬프트를 완성
Sparse Retriever vs Dense Retriever
- Sparse Retriever는 키워드 기반 검색기로, 의학적인 용어 등 특정 키워드를 강조할 때 사용
- Dense Retriever는 벡터 공간에서의 의미를 중시하는 검색기
참고
테디노트의 RAG 비법노트 : 랭체인을 활용한 GPT부터 로컬 모델까지의 RAG 가이드
반응형