1. JPA와 커넥션 관리의 기본 구조
- Java Persistence API(JPA)는 Java EE 환경에서 데이터베이스 연결을 어떻게 관리할지에 대한 표준 제시
- 초기 JPA 1.0은 엔터프라이즈 애플리케이션 서버와 밀접하게 결합되어, 데이터베이스 커넥션을 애플리케이션 서버가 통제·관리하도록 설계되었으며 주요 포인트는 다음과 같음
- Java EE 환경: 데이터 소스는 JNDI(Java Naming and Directory Interface)를 통해 애플리케이션에 주입되며 커넥션 풀링, 모니터링, JTA(분산 트랜잭션 관리) 등은 모두 서버가 책임짐
- persistence.xml 설정: 개발자는 JNDI 이름을 통해 RESOURCE_LOCAL(로컬 트랜잭션) 또는 JTA(분산 트랜잭션) 데이터 소스를 지정해야 하며, transaction-type 속성 역시 일치하게 맞춰야 함
- JPA 2.0 이후: 드라이버 기반 커넥션 관리(직접 JDBC URL, 드라이버, 사용자명, 비밀번호 설정)가 도입되었지만, 대다수 실무 환경에서는 커넥션 풀링 및 모니터링이 필수이기 때문에 JPA 표준만으로는 한계가 있었고 결국 각 JPA 구현체가 자체적인 커넥션 관리 전략을 제공
2. JDBC 커넥션 라이프사이클과 성능
- JDBC 커넥션은 생성, 사용, 반환의 라이프사이클을 가지며, 물리적 커넥션을 매번 새로 설정할 때는 TCP 연결, 스레드 할당, 버퍼 할당 등 자원 집약적 작업이 필요하므로 응답 시간이 길어질 수 있음
- 커넥션 획득 시간은 DBMS 및 환경에 따라 큰 편차가 있을 수 있으며 이로 인해 연결 획득 자체가 트랜잭션 처리량의 병목이 될 수 있음
- i.g. p99 기준으로 물리적 커넥션은 수십~수백 ms가 소요될 수 있음

2.1 커넥션 풀링의 이점
- 커넥션 풀을 이용하면, 이미 생성된 커넥션을 재사용하므로 연결 획득 시간이 마이크로초 단위로 줄어듦
- 즉각적인 커넥션 재사용, 풀 확장/축소, 풀 최대치 도달 시 대기 및 타임아웃 전략 등 다양한 상황에 대한 유연한 대응이 가능해짐
- 트래픽 스파이크 및 보호
- 커넥션 풀은 노드별로 사용 가능한 커넥션 수를 제한하여, 갑작스러운 트래픽 급증이나 서비스 거부 공격(DoS)으로부터 데이터베이스를 보호함
3. Hibernate ConnectionProvider의 역할과 종류
- Hibernate는 Java EE, 독립 실행(standalone) 환경 모두에서 유연하게 동작할 수 있도록 자체적으로 ConnectionProvider 추상화하여 제공
- ConnectionProvider 인터페이스의 메서드는 다음과 같으며 Hibernate 코어와 실제 커넥션 관리 API(커넥션 풀 등) 사이의 계약 역할을 수행
- getConnection(): 커넥션 획득
- closeConnection(Connection): 커넥션 반납
- supportsAggressiveRelease(): 적극적 커넥션 해제 지원 여부
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public interface ConnectionProvider extends Service, Wrapped { | |
| Connection getConnection() throws SQLException; | |
| void closeConnection(Connection var1) throws SQLException; | |
| boolean supportsAggressiveRelease(); | |
| default DatabaseConnectionInfo getDatabaseConnectionInfo(Dialect dialect) { | |
| return new DatabaseConnectionInfoImpl(dialect); | |
| } | |
| } |
3.1 Hibernate의 대표 커넥션 공급자
- DriverManagerConnectionProvider
- 기본 JDBC 드라이버 매니저로 직접 커넥션을 획득
- 아주 단순한 커넥션 풀 구현 (실제 프로덕션에는 적합하지 않음)
- 테스트용 또는 별도 의존성 없는 환경에서만 권장
- C3P0ConnectionProvider
- 오픈소스 커넥션 풀인 C3P0를 활용
- Hibernate 의존성 (hybernate-c3p0)과 c3p0 접두사 설정이 필요
- 다양한 커넥션 풀 옵션 지원 (최대/최소 커넥션, 타임아웃 등)
- HikariConnectionProvider
- HikariCP는 현재 가장 빠르고 널리 쓰이는 오픈소스 커넥션 풀
- 별도의 hibernate-hikaricp 의존성이 필요하며, HikariCP 고유 설정 속성 사용
- 초고성능 환경 및 짧은 응답 시간이 요구되는 서비스에 적합
- DatasourceConnectionProvider
- JTA 트랜잭션 (분산 트랜잭션) 환경과 완벽히 호환
- Spring, Bitronix, Atomikos 등 다양한 외부 트랜잭션 매니저 및 커넥션 풀과 연동 가능
- DataSourceProxy, FlexyPool 등과 체인 연결하여 커넥션 로깅, 모니터링도 용이
- 가장 유연하고 실무에서 권장되는 방식
3.2 실전 적용 가이드
- 테스트 환경에서는 DriverManagerConnectionProvider도 무방하지만, 프로덕션 환경에서는 반드시 HikariCP, C3P0, 또는 DatasourceConnectionProvider와 같은 풀 기반 연결 공급자를 사용하는 것을 권장
- 대규모 트래픽, 분산 트랜잭션, 커넥션 모니터링 등이 필요하다면 DatasourceConnectionProvider에 외부 풀과 프록시, 모니터링 도구 등을 결합하는 것이 가장 바람직함
4. Hibernate 커넥션 관리의 진화와 설정 방식
- Hibernate는 데이터베이스 커넥션의 획득과 해제 전략을 세밀하게 제어할 수 있는 프레임워크
- Hibernate 5.2 이전에는 획득 모드 (hibernate.connection.acquisition_mode)와 해제 모드 (hibernate.connection.release_mode)를 별도의 설정으로 관리했음
- Hibernate 5.2 이후에는 hibernate.connection.handling_mode 하나로 통합되어, 커넥션의 획득과 해제 시점을 보다 직관적으로 설정할 수 있음
5. 트랜잭션 유형별 커넥션 획득과 해제 전략
- Hibernate는 트랜잭션의 유형 (RESOURCE_LOCAL, JTA)에 따라 커넥션 획득과 해제 방식을 다르게 적용
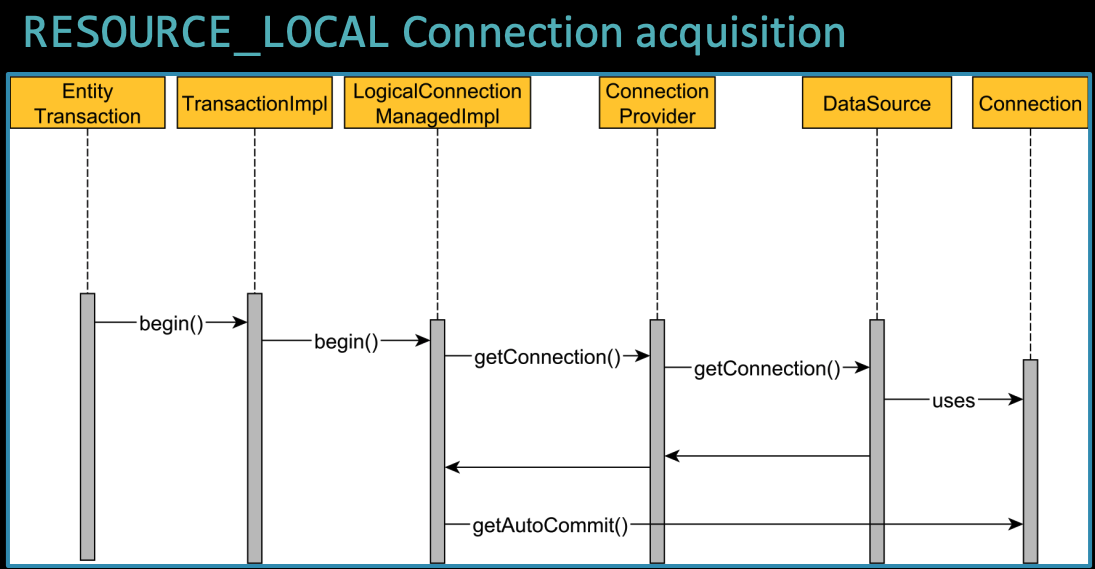
5.1 RESOURCE_LOCAL 트랜잭션
- 일반적으로 트랜잭션이 시작되면 커넥션을 즉시 획득하여, 트랜잭션이 커밋 또는 롤백될 때까지 유지됨
- Hibernate 5.2.10부터는 '커넥션 획득 지연 (delayed acquisition)' 기능이 도입되어, 실제 SQL statement 실행이나 auto-commit 확인이 필요할 때까지 커넥션 획득을 미루는 것이 가능해짐
- 단, 이 기능을 활용하려면 데이터 소스의 auto-commit을 명시적으로 비활성화하도록 아래와 같이 설정해야 함
<property name="hibernate.connection.provider_disables_autocommit" value="true"/>
5.2 JTA 트랜잭션
- 기본적으로 statement마다 커넥션을 획득하고 실행 후 즉시 해제하는 after_statement 모드를 사용
- 이는 과거 Java EE 서버에서 JTA 경계 간 커넥션 누수 문제를 방지하기 위해 도입된 전략
- 하지만, JTA 트랜잭션 관리자가 커넥션 누수 경고를 발생시키지 않는 환경에서는 트랜잭션 종료 시 커넥션 해제하는 after_transaction 모드로 전환하는 것이 성능상 더 유리함
6. Hibernate Connection Handling Mode와 Release Mode 비교
6.1 after_transaction
- 트랜잭션이 끝날 때까지 커넥션을 유지
- 트랜잭션 동안 여러 statement를 실행해도 커넥션을 반복적으로 풀에서 획득/해제하지 않으므로 오버헤드가 줄어듦
- 커넥션 획득 시점을 지연시키고 after_transaction 해제 모드를 사용하면,
실제로 커넥션의 점유 시간이 대폭 줄어들고, 동시에 더 많은 트랜잭션을 처리할 수 있음
- 커넥션 획득 시점을 지연시키고 after_transaction 해제 모드를 사용하면,
- Hibernate 5.2 이상에서 설정하는 방법은 아래와 같음
<property name="hibernate.connection.handling_mode"
value="delayed_acquisition_and_release_after_transaction" />
- Hibernate 5.1 이하에서는 release_mode 속성을 after_transaction으로 설정
6.2 after_statement (JTA default mode)
- statement 실행 후 커넥션을 반납, 다음 statement 실행 전 다시 획득
- 커넥션 풀을 자주 들락날락하게 되어 미세하지만 누적 오버헤드 발생
- 트랜잭션이 길고 statement 수가 많을수록 비효율적임
- after_statement 모드에서는 statement마다 커넥션을 획득/해제하므로, 수만 ~ 수백만 트랜잭션을 처리하는 환경에서는 누적된 오버헤드가 수십~수백 초에 달할 수 있음
6.3 실무 적용 가이드
- 데이터베이스 커넥션은 한정된 리소스이므로, 커넥션 점유 시간을 최소화하는 것이 고성능의 핵심
- Hibernate 5.2 이상에서는 handling_mode 속성을 적극 활용해, delayed acquisition 및 after_transaction 해제 모드를 사용하는 것을 권장
- JTA 환경에서도 특별한 누수 경고가 없다면 after_transaction 모드가 훨씬 효율적
- 데이터 소스의 auto-commit을 미리 비활성화하고, Hibernate에 provider_disables_autocommit을 true로 지정해야 연결 획득 지연이 효과적으로 동작함
- 커넥션 획득/해제 전략을 올바르게 선택하면, 트랜잭션 처리량을 극대화하고 시스템 전체의 확장성, 안정성, 성능을 모두 높일 수 있음
7. 커넥션 풀 사이징의 중요성
- 현대 엔터프라이즈 시스템은 여러 프론트엔드, 백엔드, 배치 노드 등 다양한 컴포넌트가 동시에 데이터베이스에 접속하므로 데이터베이스 커넥션 풀의 크기를 적절히 설정하지 않으면, 일부 노드는 커넥션을 과도하게 보유하고 다른 노드는 부족 현상을 겪을 수 있음
- 이로 인해 전체 시스템의 응답성이 저하되고, 데이터베이스 리소스가 낭비될 뿐 아니라, SLA (Service Level Agreement)를 만족하지 못할 위험이 커짐
7.1 커넥션 풀 사이징의 기본 원리와 한계
- 커넥션 풀 사이징의 기본 원리는 대기이론 (Queuing Theory)의 Little’s Law에 기반함
- 하지만 이론상 계산만으로 최적의 커넥션 풀 크기를 정하는 것은 거의 불가능
- 실제 애플리케이션은 다음과 같은 복잡한 변수로 인해 예측이 어려움
- 서비스 시간의 변동 (캐시 미스, 리소스 포화, GC 등)
- 트래픽 급증, 네트워크 지연 등 예측 불가한 외부 요인
- 분산 환경에서 각 노드별로 상이한 부하
- 따라서, 모니터링을 통한 동적 튜닝 필수
8. FlexyPool: 커넥션 풀 모니터링과 관리의 표준 도구
- FlexyPool은 데이터베이스 커넥션 풀의 실시간 모니터링, 자동 확장, 상세 메트릭 제공을 위한 오픈소스 프레임워크

- FlexyPool이 지원하는 주요 커넥션 풀은 다음과 같음
- HikariCP
- C3P0
- DBCP
- Tomcat CP
- Atomikos
- Bitronix
- FlexyPool이 모니터링하는 주요 항목은 다음과 같음
- 동시 사용 커넥션/커넥션 요청 수
- 커넥션 획득 및 임대 (사용) 시간
- 풀 크기 동적 변화
- 획득 타임아웃 및 재시도 횟수
- 전체 커넥션 획득 시간 분포 (백분위수 포함)
- FlexyPool은 풀 크기를 매우 낮게 시작해, 커넥션 획득 타임아웃이 발생하면 자동으로 풀 크기를 늘릴 수 있으며 이때 오버플로 버퍼를 통해 트래픽 스파이크에 안전하게 대응할 수도 있음
- FlexyPool은 Dropwizard Metrics와 연동하여 수집된 메트릭을 로그, JMX, Graphite 등 다양한 채널로 내보낼 수 있음
8.1 메트릭 분석 및 실전 적용 예시
- 백분위수의 중요성: 평균값만으로는 트래픽 급증 상황을 설명할 수 없음
- i.g. p99가 6~8개 커넥션임을 보여주면, 해당 부하를 감당하기 위해 최소 그만큼의 커넥션이 필요하다는 것을 알 수 있음
- 커넥션 획득/임대 시간: 대부분의 요청은 빠르게 커넥션을 얻지만, 풀 크기 한계나 타임아웃이 발생하면 획득 시간이 급격히 늘어날 수 있음
- 임대 시간이 길어지는 경우, 장기 실행 트랜잭션을 더 짧게 쪼개거나, 여러 스레드로 부하를 분산하는 등의 조치 필요
9. Hibernate 통합 및 고급 모니터링
- Hibernate의 generate_statistics 옵션을 활성화하면, SQL 실행, 커넥션 획득/해제, statement 준비 등 다양한 내부 메트릭을 확인할 수 있음
- Dropwizard Metrics, FlexyPool 등 외부 프레임워크와 결합하면, 메트릭 수집, 시각화, 자동 경고/알림이 모두 가능해짐
9.1 핵심 적용 가이드
- 커넥션 풀 크기는 반드시 실시간 모니터링, p99 분석, 자동 확장을 바탕으로 튜닝해야 함
- FlexyPool은 실전 환경에서 즉시 적용 가능한 표준 도구
- 커넥션 획득/임대 시간을 정기적으로 점검하고, 장기 트랜잭션은 쪼개거나 리팩토링 필요
- 평균값이 아닌 백분위수 (p95, p99 등)를 기준으로 풀 크기와 SLA를 결정해야 함
10. Hibernate Statistics
- Hibernate Statistics는 애플리케이션의 퍼시스턴스 계층에서 발생하는 다양한 내부 동작 (연결/트랜잭션 사용, 엔티티 및 컬렉션 로드/수정/삭제, 2차 캐시 활용, SQL 실행 등)에 대한 실시간 모니터링 및 메트릭 수집 기능 제공
- 해당 통계 기능은 성능 병목 진단, 캐시 효율성 분석, 쿼리 최적화, 커넥션 사용 실태 파악 등 다양한 목적에 매우 유용함
10.1 기본 Hibernate Statistics 활성화 및 한계
- Hibernate는 오버헤드 최소화를 위해 기본적으로 통계 수집을 비활성화시키며 통계를 사용하기 위해서는 설정에 아래와 같이 추가해야 함
<property name="hibernate.generate_statistics" value="true"/>
- 기본 구현체는 ConcurrentStatisticsImpl이며, 주요 Hibernate 이벤트마다 카운터를 증가시키는 방식
- 로그 메시지를 보려면 아래와 같이 Logger 레벨을 info로 설정해야 함
<logger level="info" name="org.hibernate.engine.internal.StatisticalLoggingSessionEventListener"/>
- 단, 기본 통계는 단순 카운터 및 누적 시간만 기록하며, 복잡한 분포 (예: 백분위수, 히스토그램)나 고급 시간 분석은 제공하지 않음
10.2 Hibernate Statistics로 측정 가능한 항목
아래의 모든 콜백은 StatisticsImplementor 인터페이스에 정의되어 있으며, 원하는 대로 커스터마이징 할 수 있음
- 데이터베이스 커넥션 획득/해제 시간
- 트랜잭션 처리 시간
- SQL statement 준비 및 실행 시간
- 엔티티 및 컬렉션의 로드/삽입/업데이트/삭제 횟수
- 2차 캐시 히트/미스/풋/이빅션 카운트
- 쿼리 캐시 활용 통계 등
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public interface StatisticsImplementor extends Statistics, Service { | |
| void openSession(); | |
| void closeSession(); | |
| void flush(); | |
| void connect(); | |
| void prepareStatement(); | |
| void closeStatement(); | |
| void endTransaction(@UnknownKeyFor @NonNull @Initialized boolean var1); | |
| void loadEntity(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void fetchEntity(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void updateEntity(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void insertEntity(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void deleteEntity(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void optimisticFailure(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void loadCollection(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void fetchCollection(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void updateCollection(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void recreateCollection(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void removeCollection(@UnknownKeyFor @NonNull @Initialized String var1); | |
| void entityCachePut(@UnknownKeyFor @NonNull @Initialized NavigableRole var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void entityCacheHit(@UnknownKeyFor @NonNull @Initialized NavigableRole var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void entityCacheMiss(@UnknownKeyFor @NonNull @Initialized NavigableRole var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void collectionCachePut(@UnknownKeyFor @NonNull @Initialized NavigableRole var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void collectionCacheHit(@UnknownKeyFor @NonNull @Initialized NavigableRole var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void collectionCacheMiss(@UnknownKeyFor @NonNull @Initialized NavigableRole var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void naturalIdCachePut(@UnknownKeyFor @NonNull @Initialized NavigableRole var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void naturalIdCacheHit(@UnknownKeyFor @NonNull @Initialized NavigableRole var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void naturalIdCacheMiss(@UnknownKeyFor @NonNull @Initialized NavigableRole var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void naturalIdQueryExecuted(@UnknownKeyFor @NonNull @Initialized String var1, @UnknownKeyFor @NonNull @Initialized long var2); | |
| void queryCachePut(@UnknownKeyFor @NonNull @Initialized String var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void queryCacheHit(@UnknownKeyFor @NonNull @Initialized String var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void queryCacheMiss(@UnknownKeyFor @NonNull @Initialized String var1, @UnknownKeyFor @NonNull @Initialized String var2); | |
| void queryExecuted(@UnknownKeyFor @NonNull @Initialized String var1, @UnknownKeyFor @NonNull @Initialized int var2, @UnknownKeyFor @NonNull @Initialized long var3); | |
| void updateTimestampsCacheHit(); | |
| void updateTimestampsCacheMiss(); | |
| void updateTimestampsCachePut(); | |
| default void queryPlanCacheHit(@UnknownKeyFor @NonNull @Initialized String query) { | |
| } | |
| default void queryPlanCacheMiss(@UnknownKeyFor @NonNull @Initialized String query) { | |
| } | |
| default void queryCompiled(@UnknownKeyFor @NonNull @Initialized String hql, @UnknownKeyFor @NonNull @Initialized long microseconds) { | |
| } | |
| default void slowQuery(@UnknownKeyFor @NonNull @Initialized String sql, @UnknownKeyFor @NonNull @Initialized long executionTime) { | |
| } | |
| default @UnknownKeyFor @NonNull @Initialized Map<@UnknownKeyFor @NonNull @Initialized String, @UnknownKeyFor @NonNull @Initialized Long> getSlowQueries() { | |
| return Collections.emptyMap(); | |
| } | |
| } |
10.3 Hibernate Statistics 커스터마이징과 확장
- 더 정밀하고 실무적인 메트릭 분석 (i.g. 트랜잭션별 연결 획득 횟수, 연결 보유 시간 분포 등)을 원한다면 StatisticsImplementor 인터페이스를 직접 구현하거나, 아래와 같이 커스텀 팩토리 (StatisticsFactory)를 설정할 수 있음
<property name="hibernate.stats.factory" value="com.vladmihalcea.hibernate.statistics.TransactionStatisticsFactory"/>
- 커스텀 Statistics 구현체는 콜백 오버라이드, 히스토그램/타이머 생성, 분포/백분위수 집계 등 다양한 기능을 추가할 수 있음
- i.g. 트랜잭션별 커넥션 획득 횟수, 커넥션 보유 시간, SQL 실행 상세 분포 등을 수집하고, Dropwizard Metrics와 연결해 실시간 모니터링 및 대시보드로 내보낼 수 있음
10.4 Dropwizard Metrics와의 통합
- 대규모 트랜잭션 시스템에서는 모든 메트릭 샘플을 메모리에 저장할 수 없으므로, Dropwizard Metrics의 reservoir sampling을 활용해 메모리 소모를 최소화할 수 있음
- 타이머, 히스토그램, 게이지 등 다양한 메트릭 유형을 지원하며, SLF4J, JMX, Ganglia, Graphite 등 여러 채널로 실시간 데이터를 내보낼 수 있음
- 직접 커스터마이징 할 필요가 없으며, Dropwizard Metrics의 성숙한 API와 인프라를 활용하는 것이 가장 실용적
10.5 핵심 요약 및 실무 가이드
- Hibernate Statistics는 퍼시스턴스 성능 진단, 커넥션 관리, 캐시 효율 분석에 필수적인 도구
- 기본 통계만으로 한계가 있다면 커스텀 Statistics 구현 및 Dropwizard Metrics 연동을 적극 활용하는 것을 권장
- 메트릭 수집 시 평균값 대신 백분위수, 히스토그램 등 분포 기반 지표로 병목 및 이상 상황을 조기에 탐지하는 것이 중요
- 통계/모니터링 코드의 재사용성과 확장성을 높이기 위해 반드시 표준 프레임워크 (Dropwizard Metrics 등)와 통합하는 것을 권장
참고
인프런 - 고성능 JPA & Hibernate (High-Performance Java Persistence)
반응형
'DB > JPA' 카테고리의 다른 글
| [Hibernate/JPA] 식별자 생성 최적화 전략 (0) | 2025.05.30 |
|---|---|
| [Hibernate/JPA] 타입 (0) | 2025.05.29 |
| [JPA] Hibernate MultipleBagFetchException (0) | 2023.06.28 |
| [JPA] 준영속(Detached) 상태 엔티티 수정하는 방법 (0) | 2023.05.07 |
| [JPA] JPQL 추가 정리 (0) | 2021.10.18 |