1. 데이터베이스 Primary Key의 종류와 설계 원칙
- 자연 키 (Natural Key): 주민등록번호, ISBN, 차량 식별 번호 등 자연스럽게 정의된 고유값
- 장점: 비즈니스적으로 의미가 있어 직관적
- 단점: 일반적으로 길이가 길어 인덱스·외래키·저장 공간이 비효율적이고, 변경 가능성도 존재
- 대체 키 (Surrogate Key): 시스템적으로 부여하는 IDENTITY, SEQUENCE, UUID 등
- 장점: 크기가 작고(숫자), 인덱스·외래키·조인·클러스터드 인덱스 등에서 성능상 유리
- UUID는 128 비트라 역시 공간 비효율, 일반적으로는 숫자형 auto-increment/sequence가 선호됨
- 공간 효율성: PK가 클수록 모든 보조 인덱스와 외래키에도 그 크기만큼 부담
- PK가 작을수록 데이터베이스 IO, 인덱스 탐색, 메모리 효율 등에서 유리
2. JPA 식별자 매핑 방식
- 수동 할당 (Assigned): 개발자가 직접 PK 값을 할당
- i.g. 자연 키를 PK로 쓸 때, 외부 시스템 연동 등
@Id
private Long isbn; // Book ISBN
- 자동 생성 (Generated): JPA/Hibernate가 자동으로 PK를 생성하며 네 가지 전략이 존재함
- IDENTITY: DB의 auto-increment 컬럼 사용
- SEQUENCE: DB 시퀀스 객체 사용
- TABLE: 별도 테이블로 시퀀스 역할을 에뮬레이션
- AUTO: 데이터베이스 종류에 따라 위 전략 중 하나를 자동 선택
2.1 IDENTITY 전략
- MySQL(AUTO_INCREMENT), Oracle 12c, SQLServer 등에서 지원
- 특징은 다음과 같음
- INSERT 직후에만 PK 값을 알 수 있음 (SQL 실행 후 DB에서 반환)
- 영속성 컨텍스트의 write-behind batching 캐싱이 깨짐 → 배치 insert 불가
- 일반적으로 단일 insert에만 적합, 대량 insert에는 효율 저하
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;2.2 SEQUENCE 전략
- Oracle, PostgreSQL 등 시퀀스 객체 지원 DB에서 사용
- 특징은 다음과 같음
- INSERT 이전에 미리 PK 값을 얻을 수 있음
- 배치 insert, 플러시 최적화 등에서 매우 효율적
- 동시성 문제를 lightweight non-transactional lock으로 해결
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;2.3 TABLE 전략
- 시퀀스 객체가 없는 DB에서도 사용 가능한 대체 방식
- 별도 테이블에 시퀀스 값을 저장/갱신하며 row-level lock 활용
- 해당 전략은 단점이 많음
- 락이 트랜잭션 단위로 유지되어 커넥션 풀 등 인프라에 부담됨
- 성능상 SEQUENCE/IDENTITY 대비 현저히 떨어짐
- RESOURCE_LOCAL/JTA 환경에서 트랜잭션 분리 등 복잡한 처리 필요
2.4 AUTO 전략
- Hibernate 5부터는 SequenceStyleGenerator를 통해
- SEQUENCE 지원 DB: SEQUENCE 사용
- 미지원 DB: TABLE 사용
- MySQL 등에서는 명시적으로 네이티브 generator를 지정해 IDENTITY를 사용해야 함
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;성능을 최우선으로 할 때 팁
- 대부분의 OLTP 시스템은 숫자형 auto-increment/sequence surrogate key 권장
- 대량 insert, batching, keyset pagination 등에서는 SEQUENCE가 가장 효율적
- IDENTITY는 단일 insert 위주, TABLE은 성능상 비추천

3. Hibernate Identifier Generator와 Optimizer의 분류
- Hibernate에서 엔티티 식별자(Primary Key) 자동 생성에는 다양한 전략과 최적화 기법이 있음
- 특히 SEQUENCE나 TABLE 기반의 식별자 생성기는 성능 향상과 데이터베이스 왕복 최소화를 위해 여러 종류의 Optimizer를 제공
legacy 구현체 (현재 deprecated)
- SequenceGenerator
- SequenceHiLoGenerator
- MultipleHiLoPerTableGenerator
최신 및 더 효율적인 구현체
- SequenceStyleGenerator
- TableGenerator (Hibernate 5부터 기본)
- Hibernate 5 이전에는 hibernate.id.new_generator_mappings=true 설정이 필요했으나, 5부터는 기본 활성화됨
4. 대표적인 Optimizer 알고리즘
4.1 Hi/Lo 알고리즘
- Hi/Lo는 데이터베이스 시퀀스 (또는 테이블)에서 한 번에 하나의 “큰 단위”(hi) 값을 가져오고, 애플리케이션에서 여러 개의 “작은 단위”(lo) 값을 조합해 다수의 식별자(ID)를 생성하는 전략
- 목적은 데이터베이스 왕복 횟수를 줄여서 대량 데이터 처리, 배치 삽입 등에서 성능을 높이는 데 있음
- 기본 개념은 다음과 같음
- n: 한 번에 할당받을 수 있는 lo 값의 개수 (여기서는 n = 3)
- hi: 데이터베이스 시퀀스에서 받아오는 값 (큰 단위, 배치의 시작점)
- lo: 애플리케이션이 hi값을 기준으로 생성하는 작은 단위 (0 ~ n-1)
- ID 공식: n * hi + lo
- 장점: DB 시퀀스/테이블 호출이 획기적으로 줄어들기 때문에 대량 데이터 처리 및 배치 성능이 매우 뛰어남
- 문제점: 모든 DB 클라이언트/사용자가 이 알고리즘을 인지하고 동일하게 사용해야 안전, 외부 시스템(DBA, Batch 등)이 DB에 직접 insert 시 충돌 위험
- 엔터프라이즈 환경에 부적합
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| @Entity(name = "Post") | |
| @Table(name = "post") | |
| public static class Post { | |
| @Id | |
| @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "post_sequence") | |
| @GenericGenerator( | |
| name = "post_sequence", | |
| strategy = "sequence", | |
| parameters = { | |
| @Parameter(name = "sequence_name", value = "post_sequence"), | |
| @Parameter(name = "initial_value", value = "1"), | |
| @Parameter(name = "increment_size", value = "3"), | |
| @Parameter(name = "optimizer", value = "hilo") | |
| } | |
| ) | |
| private Long id; | |
| private String title; | |
| public Long getId() { | |
| return id; | |
| } | |
| public void setId(Long id) { | |
| this.id = id; | |
| } | |
| public String getTitle() { | |
| return title; | |
| } | |
| public void setTitle(String title) { | |
| this.title = title; | |
| } | |
| } |

Alice의 ID 생성
- 첫 번째 hi 값 요청
- Alice는 DB에 hi 값을 요청하고 hi = 3을 할당받음
- 이제 lo는 0부터 2까지 사용 가능
- ID 생성
- Id를 구하는 주요 공식은 n * hi + lo
- 이미지에서 구하는 식별자 공식은 [(n×(hi−1)+1), (n×hi)]이므로 7 ~ 9
- lo를 모두 소모하면 다음 hi 값 요청
- lo = 2까지 사용 후, Alice는 다시 DB에 hi 값을 요청 (hi = 5)
- 13, 14, 15와 같은 ID를 새로 생성할 수 있음
Bob의 ID 생성
- 동일하게 n=3을 사용
- Bob도 hi 값을 DB에서 받아오며, Alice와 독립적으로 동작
- ID 생성
- hi = 4를 받아오면 lo= 0 ~ 2로 10, 11, 12 생성
4.2 Pooled Optimizer
- Hi/Lo의 단점을 해결하기 위해 만들어진, Hibernate의 기본 시퀀스 Optimizer로 여러 애플리케이션, 외부 클라이언트와도 안전하게 동작하도록 설계됨
- 원리: DB 시퀀스의 값을 한 번에 여러 개 미리 할당 (allocationSize=3이면 1, 4, 7, 10...)
- 할당 범위 내에서는 애플리케이션에서 자유롭게 PK 생성
- 외부 시스템이 시퀀스 값을 직접 사용해도 충돌 없음
- 장점
- 데이터베이스 왕복 횟수 감소 (Hi/Lo Optimizer와 유사한 배치이점)
- 외부 시스템과의 충돌 위험 없음 (상호 운용성 높음)
- 표준 JPA @SequenceGenerator에서 allocationSize만 지정하면 간단히 적용 가능
- 엔터프라이즈, 마이크로서비스, 외부 시스템과 DB 시퀀스를 공유하는 환경에 가장 적합
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| @Entity(name = "Post") | |
| @Table(name = "post") | |
| public static class Post { | |
| @Id | |
| @GenericGenerator(name = "table", strategy = "enhanced-table", parameters = { | |
| @org.hibernate.annotations.Parameter(name = "table_name", value = "sequence_table"), | |
| @org.hibernate.annotations.Parameter(name = "increment_size", value = "50"), | |
| @org.hibernate.annotations.Parameter(name = "optimizer", value = "pooled"), | |
| }) | |
| @GeneratedValue(generator = "table", strategy=GenerationType.TABLE) | |
| private Long id; | |
| } |
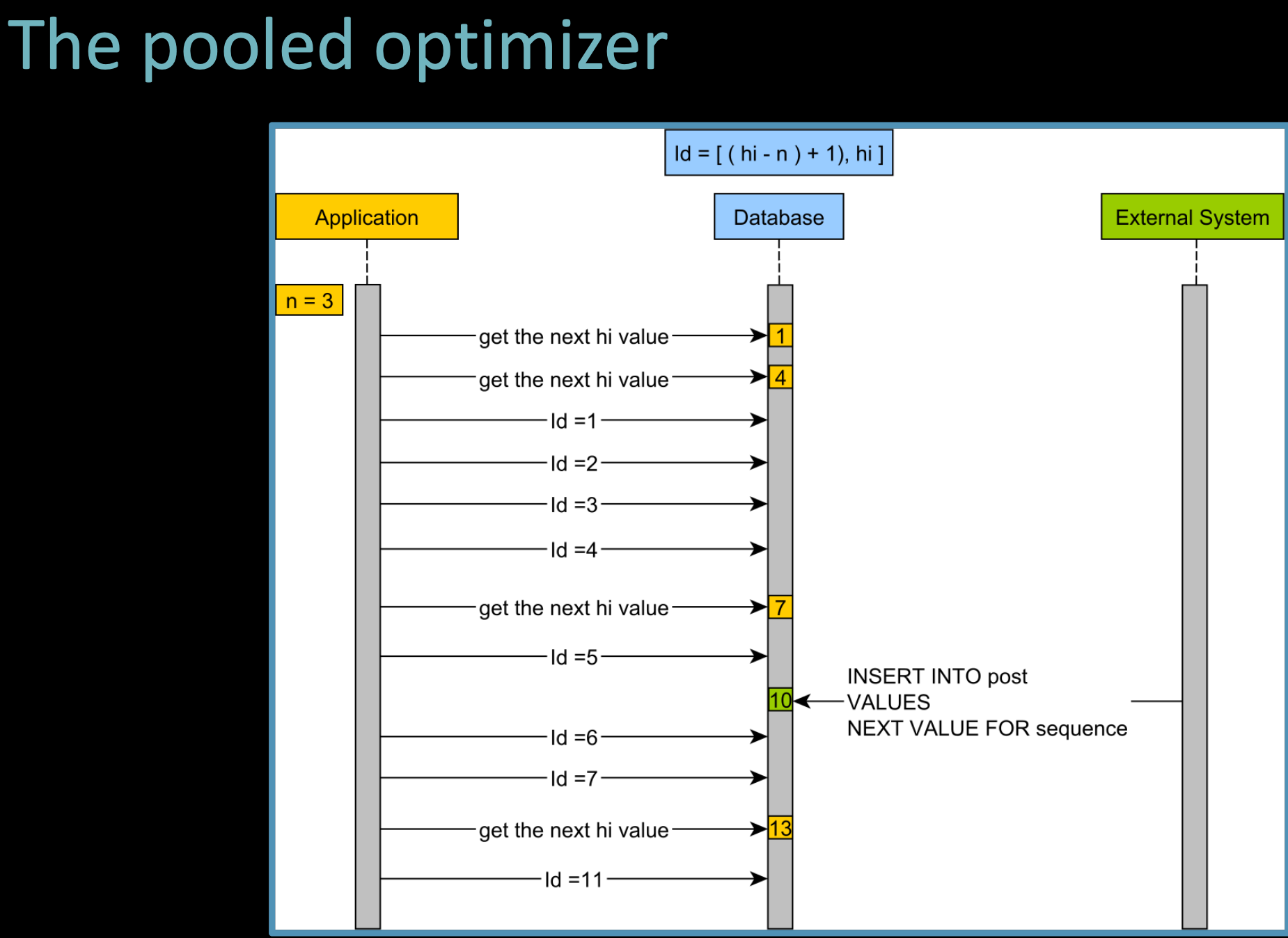
동작 과정
- 첫 번째 hi 값 요청
- 애플리케이션은 DB에 hi 값 요청
- DB 시퀀스에서 1을 반환
- 애플리케이션은 1 ~ 1 (n=1)이므로 Id=1 할당
- 두 번째 hi 값 요청
- 다음 hi 값을 요청하면 4가 반환됨 (hi=4, 시퀀스 값이 n씩 증가)
- 애플리케이션은 Id=2, 3, 4까지 메모리에서 순차적으로 할당 (hi - n + 1 ~ hi)
- 할당값 모두 소진 시
- 2, 3, 4까지 모두 사용하면 다음 hi 값을 요청
- 7이 반환되면 Id=5, 6, 7 할당 가능.
- 반복
- 같은 방식으로 다음 hi값 10이 반환되면 Id = 8, 9, 10
- 다시 hi값이 13이 반환되면 Id = 11, 12, 13 할당 가능
4.3 Pooled-Lo Optimizer
- Pooled Optimizer와 유사하지만, 시퀀스에서 받아온 값이 “구간의 시작점(low)”임을 보장
- 일부 DB/비즈니스 요구에서 “다음 시퀀스 값”이 항상 구간의 첫 번째 값이어야 할 때 사용
- 원리: Pooled Optimizer와 유사하지만, 시퀀스에서 가져온 값이 할당 범위 중 가장 낮은 값임
- allocationSize=3일 때, 1~3, 4~6, 7~9 등으로 구간 할당
- 장점
- Pooled와 동일하게 배치 성능, DB 왕복 최소화, 외부 시스템과의 충돌 없음
- 시퀀스의 값이 실제로 사용된 식별자 구간의 첫 값이므로, 추적/디버깅이 용이
- 단점
- 특별한 비즈니스 요구가 없다면 일반 Pooled와 실질적 차이 없음
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| @Entity(name = "Post") | |
| @Table(name = "post") | |
| public static class Post { | |
| @Id | |
| @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "pooled-lo") | |
| @GenericGenerator( | |
| name = "pooled-lo", | |
| strategy = "sequence", | |
| parameters = { | |
| @Parameter(name = "sequence_name", value = "post_sequence"), | |
| @Parameter(name = "initial_value", value = "1"), | |
| @Parameter(name = "increment_size", value = "3"), | |
| @Parameter(name = "optimizer", value = "pooled-lo") | |
| } | |
| ) | |
| private Long id; | |
| private String title; | |
| public Long getId() { | |
| return id; | |
| } | |
| public void setId(Long id) { | |
| this.id = id; | |
| } | |
| public String getTitle() { | |
| return title; | |
| } | |
| public void setTitle(String title) { | |
| this.title = title; | |
| } | |
| } |

동작 과정
- 첫 번째 lo 값 할당
- 애플리케이션이 DB에 hi 값 요청
- DB 시퀀스가 1을 반환
- 애플리케이션은 Id=1, 2, 3을 차례로 할당
- 할당값 소진 후, 다음 lo 값 할당
- Id=3까지 모두 사용하면, 다시 DB에 lo 값을 요청
- DB 시퀀스가 4를 반환 (lo=4)
- 애플리케이션은 Id=4, 5, 6 할당
- 반복
- Id=6까지 사용하면, 다음 lo 값 (7) 요청 → Id=7, 8, 9
- 계속해서 lo=10이 오면, Id=10, 11, 12…
참고
인프런 - 고성능 JPA & Hibernate (High-Performance Java Persistence)
반응형
'DB > JPA' 카테고리의 다른 글
| [Hibernate/JPA] 상속 (0) | 2025.06.02 |
|---|---|
| [Hibernate/JPA] 관계 (0) | 2025.06.02 |
| [Hibernate/JPA] 타입 (0) | 2025.05.29 |
| [Hibernate/JPA] Connection (0) | 2025.05.29 |
| [JPA] Hibernate MultipleBagFetchException (0) | 2023.06.28 |