개요
친구가 자료수집을 위해 크롤링을 해달라고 요청해서 사전지식이 없는 상태에서 진행해봤습니다.
대부분의 내용은 yoonpunk.tistory.com/6 블로그에서 참고했으므로 도움이 되었다면 해당 블로그에 가서 좋아요를 눌러주시면 될 것 같습니다!
진행 과정
1. 우선, yoonpunk님이 작성하신 동아일보 신문기사 크롤링하기 코드를 확인해봅시다.
* 여기서 핵심은 상단에 정의된 URL 관련 상수와 get_link_from_news_title, get_text 메서드입니다.
2. 친구가 요청한 업무는 경향신문 크롤링이므로 경향신문 홈페이지에 들어간 후 아무 키워드를 작성해봅니다.
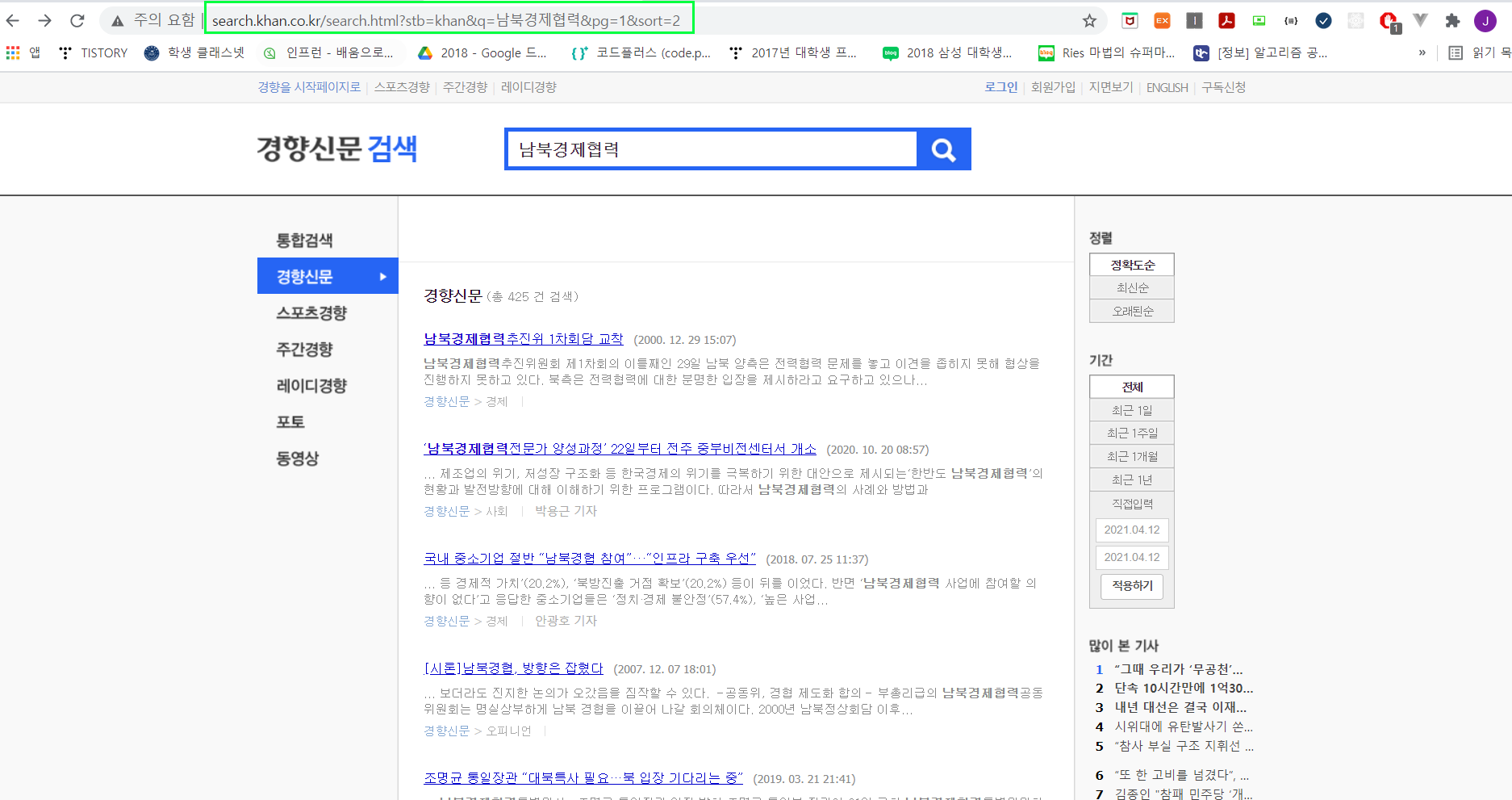
URL을 확인해보면 아래와 같습니다.
search.khan.co.kr/search.html?stb=khan&q=남북경제협력&pg=1&sort=2
URL을 하나하나 뜯어봅시다.
검색창에 해당하는 URL: search.khan.co.kr/search.html?stb=khan
검색어에 해당하는 URL: &q=[검색어]
페이지에 해당하는 URL: &pg=[원하는 페이지]
정렬 기준에 해당하는 URL: &sort=[원하는 정렬 타입]
* 최신순: 1, 정확도순: 2, 오래된순: 3
저 같은 경우에는 친구 논문에 필요한 자료이므로 정확도순이 좋을 것 같네요.
추가 적으로 동아일보와 달리 경향신문은 페이지가 순차적으로 1씩 증가하는 것을 확인할 수 있었습니다.
(ex. pg=1, pg=2, pg=3, ...)
이제 기존 코드 URL 상수를 아래와 같이 변경해봅시다.
3. 이제 검색한 페이지에서 각 뉴스 기사 링크를 찾아줘야 합니다.
개발자 도구 F12를 누르고 뉴스 링크들이 어떤 태그 내에 있는지 확인을 해줍니다.

* 확인해본 결과, phArtc 클래스를 가지는 dl 태그 내에 링크가 위치한 것을 확인할 수 있었습니다.
이제 기존 코드의 get_link_from_news_title 메서드를 아래와 같이 수정해봅시다.
4. 마지막으로 뉴스 기사 내 제목, 기자님 성함, 그리고 기사 원문이 어디 태그 내에 위치하는지를 확인해야 합니다.
마찬가지로 개발자 도구 F12를 눌러 확인을 해봅시다.

* 우선, 제목과 기자님 성함 및 이메일은 subject 클래스를 가지는 div 태그 내에 위치한 것을 확인할 수 있었습니다.
이어서, 기사 원문이 어디 태그 내에 위치하는지를 확인해봅시다.

* 확인해본 결과, art_body 클래스를 가지는 div 태그 내 context_text 클래스를 가지는 p 태그들을 모두 모으면 기사 원문을 발췌할 수 있는 것을 확인할 수 있습니다.
따라서, get_text 메서드를 아래와 같이 수정해줍니다.
* 주의: 기존 코드대로 urllib.request.urlopen(URL)를 통해 링크를 열면 HTTP 403 에러가 발생합니다.
따라서, stackoverflow.com/questions/16627227/http-error-403-in-python-3-web-scraping 링크 답변처럼 HTTP 요청에 헤더를 추가해줘야 합니다.
해당 부분 코드는 아래와 같습니다.
전체 코드
실행 방법
저 같은 경우 간단한 코드이므로 주피터 노트북에서 실행했습니다.
쥬피터 노트북에서 실행하신다면 아래와 같이 실행해주시면 됩니다.

sys.argv 매개변수에 대해 설명하자면
모듈: python3
검색어: 남북경제협력
가져올 페이지 숫자: 43 (총 425건 검색이므로 43)
결과 파일명: final_test.txt
결과물

태그들이 모두 존재하기 때문에 썩 마음에 드는 결과물은 아니지만, 친구가 이 정도면 괜찮다고 해서 여기서 끝냈습니다.
정규 문법을 사용한다면 불필요한 태그들과 특수문자들도 충분히 지울 수 있을 것이라고 봅니다!
출처
stackoverflow.com/questions/16627227/http-error-403-in-python-3-web-scraping
'[DEV] 기록' 카테고리의 다른 글
| [SpringBoot] 세션이 만료될 때 세션 값 가져오는 방법 (0) | 2021.04.24 |
|---|---|
| [c++] 문자열 내 특정 부분문자열 위치 찾기 (1) | 2021.04.24 |
| [Spring] Maven 정리 (0) | 2021.03.03 |
| Intellij IDEA(인텔리제이) 단축키 정리 (1) | 2021.03.02 |
| [Java] json을 Java Object로 변환하는 방법 (0) | 2021.02.27 |