개요
이전 게시글 https://jaimemin.tistory.com/2200에 이어서 이번 게시글에서도 인상 깊게 본 MSA 관련 유튜브 영상을 요약/정리해보겠습니다.
[MSA] 우아콘 2020 배달의민족 마이크로서비스 여행기 정리
개요 MSA 관련 리서치를 맡게 돼서 공부하는 도중 김영한 강사님이 발표해주신 우아콘 2020 영상을 인상 깊게 봐서 간단하게 요약/정리했습니다. 인프런 강의를 시청할 때도 느꼈지만 김영한 강사
jaimemin.tistory.com
이번에 내용 정리할 영상은 이벤트 소싱 아키텍처 중 CQRS 패턴에 관련된 영상이고 기존 게시글과 마찬가지로 배달의민족 우아콘 영상을 요약 및 정리했습니다. (우형에는 훌륭한 개발자들이 진짜 많네요.. 넷카라쿠배당토 인정합니다.)
아래의 내용이 궁금하신 분들께 게시글을 읽으시는 것을 추천드리고 풀 영상 시청 강력하게 추천드리겠습니다.
- CQRS 패턴이 아직 생소하신 분
- CQRS를 구성하게 된 이유가 궁금하신 분
- 아키텍처를 어떻게 구성할지 고민 중이신 분
- B마트는 어떻게 했는지 궁금하신 분
https://www.youtube.com/watch?v=fg5xbs59Lro&ab_channel=%EC%9A%B0%EC%95%84%ED%95%9CTech
1. B마트 서비스 개요
- 오프라인에서 이루어지던 장보기 경험을 온라인으로 옮겨와 빠른 시간 내에 배달해주는 퀵 커머스 서비스
- 배달의민족 앱을 통해 이용할 수 있는 서비스 인 서비스 형태로 운영 중
- 거점형 물류창고를 기반으로 해당 물류창고 주변 고객들에게 다양한 상품 제공
- 전국적으로 지점을 늘리며 서비스 확장 중
- 큐레이션 된 각종 세션들과 라면/면과 같이 카탈로그로 부르는 전시 영역을 통해 상품을 고르고 담을 수 있음
- 모든 상품은 한 개 이상의 카탈로그에 매핑되어 고객에게 노출되고 있음
- 카탈로그는 각종 큐레이션 영역과 상품을 군집하여 보여주어야 하는 각종 영역에서 시스템적으로 상품 묶음으로써 활용 중
1.1 B마트 데이터 구조는 어떻게 될까?
- 고객이 접근하게 되면 고객 위치에 따라 가까운 지점 한 곳이 특정되고 해당 지점에서 고객들은 여러 가지 카탈로그를 제공받고 해당 카탈로그에는 다양한 상품들이 매핑되고 상품 안에는 실제 고객이 구매하면 받아볼 수 있는 실물과 1:1 매핑이 되는 아이템이라는 단위를 제공받게 됨 (고객에게 노출되는 정보)
- 실제 상품 결제가 이루어지면 아이템과 매핑된 물류창고에 SKU라고 부르는 실물 재고 중 FIFO 혹은 유통기한 임박 알고리즘 등에 기반해 고객에게 배달
- 고객에게 전달되는 데이터 흐름대로 DB 스키마를 설계하는 일은 많지 않음
- 아주 많은 서비스가 데이터를 관리하는 차원에서 정규화시킨 데이터와 노출 도메인에서의 데이터 구조가 전혀 다름
- 특히나 RDBMS 기반으로 하는 서비스들은 위와 같은 일이 흔함
- B마트도 MySQL을 이용하고 있으며 지점, 카탈로그, 상품에 대한 메타 정보를 각각 입력하고 수정하며 이를 노출하기 위한 매핑 설정을 최종 단계에서 따로 진행하기 때문에 데이터 스키마는 굉장히 정규화되어 있는 상태
- 전시 도메인에서는 이를 노출하기 위해 비정규화하기 위한 작업 필요

2. CQRS 정의와 적용하게 된 배경
- Command and Query Responsibility Segregation (명령과 조회의 책임을 분리한다.)
- B마트 서비스 초기 단순한 아키텍처
- 어드민/배치, 사용자 조회 등과 같은 비즈니스 로직은 분리되어있지만 모델은 대체로 하나의 모델이 명령과 조회를 수행하는 경우가 많음
- 모델은 내부에서만 사용되는 관리용 데이터나 성능상 이슈나 여러 가지 이유로 실제 조회에는 이용되지 않는 여러 데이터들이 생기게 됨 (또한, 그러한 데이터들이 기존 모델에 주입이 되기도 함)
- 또, 노출의 측면에서는 각종 정책사항과 전시를 위해 재고 정보, 배달 수단과 같이 여러 가지 API로부터 주입받는 정보가 생기게 되어 이로 인해 모델이 복잡하게 되는 케이스가 생김
- 자연스럽게 명령 관련 로직과 조회 관련 로직이 하나의 모델을 바라보게 되며 서로 영향을 주게 됨
- 히스토리를 다 알고 있지 않는 경우 의도치 않게 특정 데이터를 사용할 수 있고 리팩토링을 시도할 때 다른 영역에 영향을 줄 수 있는 단점이 존재
- 위 문제를 해결하기 위해 명령 도메인과 조회 도메인을 분리 (CQRS가 바라는 방향)
2.1 CQRS 적용하기
- 명령 관련 로직과 조회 관련 로직을 분리하기 위해 교집합 지점인 모델을 분리하는 작업부터 수행
- 명령 모델은 기존 도메인 모델
- 조회 모델은 전시 광고 등 노출해서 이용되는 비정규화된 데이터를 한번 더 정의한 모델
- 전체 모델 중 노출되는 데이터만 뽑아서 이용하는 구조이다 보니 기존 구조에서 모델을 나누면서 자연스럽게 조회 모델을 생성하는 영역이 생김
- 이때 Entity를 이용할 수도 있지만 선택사항으로 조회 모델 생성 시점에 필요한 것은 Entity 전체가 아니라 일부 데이터인 경우가 대부분이고 조회 목적한다는 점에서 DTO를 정의해서 사용하는 것을 추천
- 조회 모델을 만든다는 것은 최적화시킨 스키마를 비정규화시켜야한다는 것인데 이때 당연히 성능 상의 부담을 갖게 됨
- 이 때문에 중간에 캐시를 추가하는 작업 수행
- 아깐 조회 모델을 생성하는 시점과 조회 모델을 이용하는 시점이 서로 호출하는 구조
- 매번 생성을 새롭게 할 경우 성능 상의 이슈 발생
- 성능과의 trade off가 되는 힙 메모리 사이즈 혹은 cache와의 트래픽 양 증가 등의 이슈가 생기는 상황이 발생될 수밖에 없음
- 이를 근본적으로 해결하기 위해 아주 단순하게 시점을 옮겨 명령 모델을 통해 데이터가 변경되는 시점에 조회 모델을 생성하고 비정규화된 데이터 그 자체를 그대로 저장
- CQRS에서는 조회 모델은 DB로부터 가져오는 과정에서 JOIN이나 기타 연산 작업을 극히 제한해야 한다고 함
- 가능하면 DB의 값을 그대로 가져와 곧바로 이용 가능한 형태로 제공하라고 권장
- 조회를 위한 새로운 테이블 설계 필요
- 바로 가져다 쓸 수 있는 데이터를 생성한다는 것은 곧 비정규화된 데이터를 그대로 저장한다는 말
- JSON Format을 주로 쓰임 (이 때문에 RDB가 아닌 NoSQL DB를 사용하는 케이스가 많음)
- 조회 시에는 데이터를 그대로 읽어 사용 가능하기 때문에 조회에서 Cache를 사용하지 않고도 보다 근본적인 해결책을 가져갈 수 있음
- 반면, 명령 모델 변경 시 생성하기 때문에 적은 횟수로 명령을 수행하고 많은 조회가 이루어지는 도메인에서 큰 이점을 가져갈 수 있음
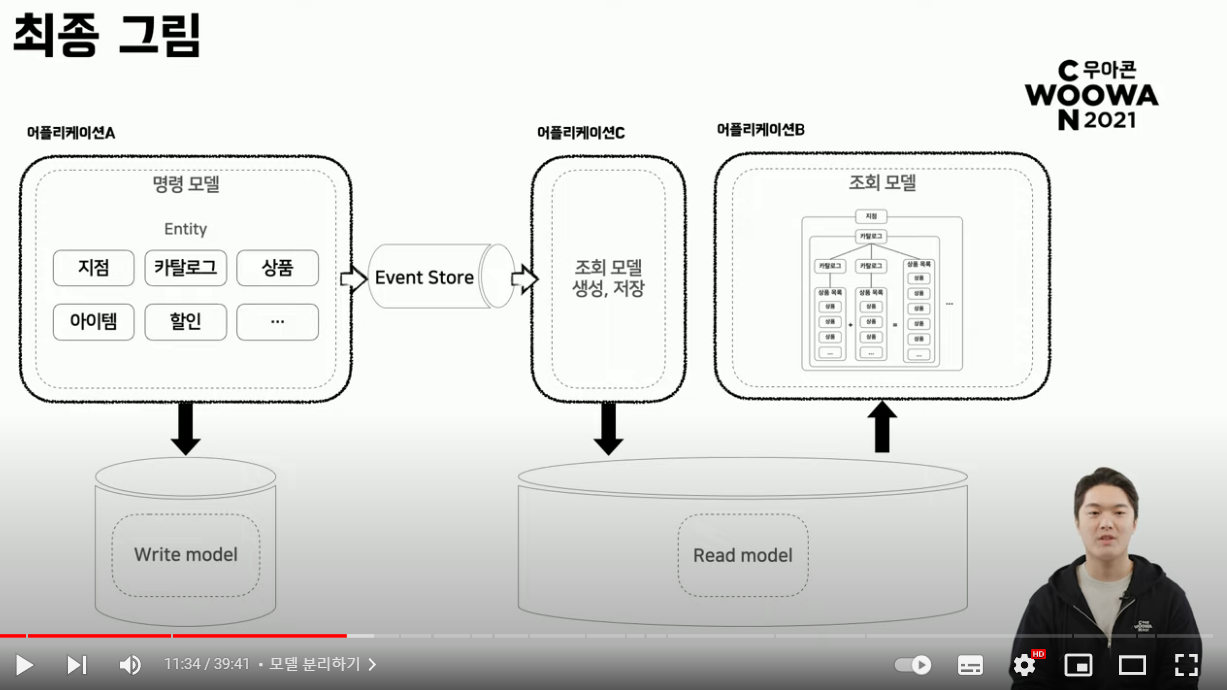
- 전체 그림으로 보면 명령이 수행되는 시점에 필요한 데이터를 생성하고 읽어가는 쪽에서는 이미 만들어지는 최종 결과물만 이용하면 되기 때문에 조회 모델을 생성하는 영역과 이용하는 영역의 context 자체 분리 가능
- UX 변경이 잦고 비즈니스가 자주 변화하는 서비스에서 이렇게 분리되는 영역은 실제 개발하는 입장에서도 구조적으로 실수할 수 있는 여지를 더욱 낮춰주는 장점이 있음
- 데이터가 분리되어 존재한다는 것은 서로 다른 저장소를 이용하도록 수정 가능
- 기존 RDB를 사용하던 시스템이 조회에 최적화된 다른 종류의 데이터베이스 사용 가능
- B마트에서는 조회 성능을 더 끌어올려줄 수 있는 Redis 사용
- 기존 DB에도 Fallback 상황을 대비해 저장하고 있음
- DB를 훨씬 더 최적화된 DB로 변경했기 때문에 쿼리 성능을 높일 수 있고 향후 조회 모델을 사용하는 형태에 따라 레디스가 아니더라도 elasticsearch나 DynamoDB처럼 다양한 데이터 저장소를 선택할 수 있는 확장성에도 큰 장점
- 다만 데이터베이스가 나뉘게 되면 두 저장소 간 데이터 정합성을 보장할 수 있어야 하고 관리 포인트가 늘어나기 때문에 시스템이 안정적으로 안착할 때까지는 시스템 모니터링에 신경 써야 하는 단점이 존재
- 조회 모델을 생성하는 시점이 명령 모델의 변경으로부터 이루어지는 영역
- 조회 모델을 이용하는 도메인의 성능은 매우 개선
- 생성에 책임을 떠안은 쪽은 손해만 보게 된 상황
- 조회 모델 생성 자체에 이용되는 리소스가 매우 많은데 고스란히 떠안음
- 이 책임과 성능에 대한 부담은 해당 영역을 한번 더 분리시킴으로써 해소할 수 있음
- Event Sourcing 패턴
- 이벤트 소싱 패턴은 어떠한 애플리케이션으로부터 발생한 이벤트를 event store에 저장하고 이를 여러 시스템이 구독하여 다룰 수 있는 패턴
- CQRS에 결합된 이벤트 소싱 패턴은 데이터를 관리하는 측면과 조회 모델을 생성하는 두 작업을 나누어주는 역할
- 명령 모델로 변경 감지가 되었을 때 조회 모델을 생성하기 위한 로직을 그곳에서 작성하는 것이 아니라 그저 변경된 상태를 변경하고 전달된 상태가 스트림에 쌓이면 해당 데이터를 consume 해서 조회 모델을 생성
- 이렇게 되면 명령 모델에 쌓이는 부하를 분산할 수 있음

2.2 CQRS는 언제 도입해야 할까?
- UX와 비즈니스 요구사항이 복잡해질 때
- 조회 성능을 보다 높이고 싶을 때
- 데이터를 관리하는 영역과 이를 뷰로 전달하는 영역의 책임이 나뉘어야 할 때
- 서로의 책임이 분명해져야 할 때
- ex) 명령 모델을 주로 이용하는 팀과 조회 모델을 주로 이용하는 팀이 나뉘어있을 때
- 시스템 확장성을 높이고 싶을 때
3. B마트 서비스 CQRS 패턴 적용 사례
3.1 B마트에서 CQRS를 적용한 도메인
- 앱을 통해 고객에게 카탈로그와 상품을 전시한다 (전시 도메인에만 적용)
- 꼭 서비스 전체에 적용하는 것이 아니라 필요한 도메인에만 적용 가능
3.2 B마트 메뉴
- 카탈로그는 자식 카탈로그를 갖는다.
- Leaf 카탈로그에만 상품이 등록된다.
- 카탈로그는 자식 카탈로그에 등록된 상품 전체를 노출한다.
- 판매 가능한 상품이 있는 카탈로그만 노출한다.
- 하위에 매핑된 자식 카탈로그와 그 상품들의 상태를 모두 확인해야 했기 때문에 모든 카탈로그에 대해 전체 트리 모델을 생성하는 로직이 생김
- B마트 서비스의 여러 다른 영역에서 해당 전체 트리의 일부를 이용하면 되는 구조
- 일종의 거대한 조회 모델
- 전체 트리 모델을 통으로 Caching 하게 되면 이후 API로 제공하는 전시 도메인에서 이 모델만을 참조하고 이 모델의 일부만을 이용하여 로직이 수행될 수 있다고 생각했음 (서비스 초기에는 큰 문제없었음)
- 초기에는 카탈로그 전체 트리에서 모든 카탈로그를 보여주는 화면이 있고 거기서 일부 카탈로그를 뽑아서 보여주는 비교적 단순한 로직으로 구성
- 점차 홈 화면에서 고객에게 큐레이션 되는 각종 섹션이 생기고 그 형태도 다양해지고 카탈로그 자체를 추천하기도 하고 영역별로 추가 정책이 들어가기도 함
- 대격변이라고 부를만한 이벤트가 발생하면 이 전체가 순식간에 레거시가 되는 경험
- 발전하는 서비스와 높아지는 복잡도
- 새로운 UX 요소
- 비즈니스 정책
- 개인화 (찜, 장바구니 담았는지 여부, 개인화 추천 구좌)
- 대격변 이후 남아있는 구버전 레거시
- 비대해지는 전체 트리 모델
- 외부 데이터를 주입받아 결과를 반환하는 비즈니스 로직 계속 생성
- 전체 트리 모델을 이용하는 영역이 많아지고 가진 정보가 너무 방대하다 보니 경계를 넘나드는 의존성이 생겨나며 스파게티 코드를 생성하는 사이클을 끊기 어려워짐
- 전체 트리 모델은 지점 수, 카탈로그 수, 상품 수, 사용자 수가 늘면 곱으로 늘어나는 구조 (트래픽 부하 발생)
- 서비스가 성장하며 레디스 부하 심해짐 -> latency 발생하여 서비스 품질 떨어짐
- 특히나 전체 트리 모델이 아무리 커봐야 전체 용량은 얼마 안 됐지만 해당 모델이 많은 트래픽으로 왔다 갔다 하면서 레디스의 전체 사이즈보다는 트래픽량을 초과하는 문제 발생
- 보완하기 위해 사방팔방에 LocalCache와 Cache를 적용
- LocalCache는 Redis로 가는 트래픽을 감소하는 효과는 가지지만 그만큼 서버의 힙 메모리 사용량이 증가하고 여러 인스턴스 Load Balancing 하는 경우 데이터 정합성을 보장 못하는 문제 발생
- 의존성을 정리하고 Cache를 쓰는 영역과 대상 그리고 레이어도 최대한 정리하려고 했지만 전체 트리 모델을 쓰는 영역이 너무 많아져 근본적으로 해결하지 않고서는 하나씩 해결하기에는 힘들어 보임
- B마트는 기본적으로 monolithic 멀티 모듈로 구성되어 있어서 어떠한 요구사항이 왔을 때 admin부터 고객이 받아보는 api 영역까지 하나의 도메인을 한 개발자가 전체 영역을 개발하는 케이스가 많았음
- 서비스가 성장하면서 여러 비즈니스 로직, UX 변경 사항, 또 서비스를 관리하는 측면에서 요구사항이 많아지면서 B마트 플랫폼팀과 B마트 서비스팀으로 나뉘게 됨
- 명령 모델을 주로 이용하는 팀과 조회 모델을 주로 이용하는 팀이 나뉘어 CQRS 패턴을 도입하게 됨
3.3 조회 모델 (Read Model) 설계하기
- 전체 트리 모델이라는 애매한 존재하고 있었고 최소한의 쿼리로 노출 도메인에 전달될 수 있는 조회 모델을 설계하기 위해서는 복잡하게 꼬인 로직을 정리하는 것부터 시작
- 전체 트리 모델 정리
- 비즈니스 로직 곳곳에서 전체 트리 모델을 의존하고 있다 보니 비즈니스 로직이 복잡해지고 스파게티 코드 양성하는 악순환 발생
- 리팩터링은 너무 힘들고 이 구조를 정리하는 것이 시급
- 많은 로직이 얽혀있는 상태라 리팩토링하기 위해 우선 정리해야 할 대상을 한 곳에 모음
- 기존 비즈니스 로직 혹은 각종 도메인 로직에서 갖고 있던 전체 트리 모델 의존성을 모두 한 클래스에 모음
- 모은다고 바로 전체 트리 모델의 전체 의존성을 끊어낼 수는 없었고 비즈니스 로직끼리의 의존성이 더 꼬이는 일도 발생했지만 일단 우직하게 한 곳에 모음
- 한 곳에 클래스를 모으다 보니 꼬여버린 의존성 사이클이 더 생기고 복잡하게 됨
- 전체 트리 모델을 여기저기 사용하다 보니 단방향으로 호출될 수 있는 내용도 꼬여있거나 한 클래스가 책임 이상의 과도한 로직을 내포한 경우도 발생 (책임이 과하면 나눠주고 의존 관계를 분명하게 하여 데이터가 단방향으로 흐를 수 있도록 정리)
- 데이터를 단방향으로 흐를 수 있게 하면 자연스럽게 비즈니스 로직 영역에서 진짜로 필요한 데이터를 걸러낼 수 있음
- 이 전체 트리 모델의 의존성을 갖는 모든 로직에서 결과적으로 저희가 필요한 데이터는 카탈로그 목록, 카탈로그, 상품 이렇게 세 가지
- 노출 비즈니스 영역에서 전체 트리 모델에 대한 의존성이 완전히 제거할 수 있었음
- 이 세 가지 데이터만을 이용하여 이후 비즈니스 로직이 동작하게 만들 수 있었음
- 전체 트리 모델을 포함하고 있던 데이터 중 실질적으로 비즈니스 로직에서 사용되는 형태를 정리하여 뽑아낸 데이터기 때문에 이는 곧 조회 모델로 이용되는 근간이 되는 데이터
- 이 세 가지 데이터를 이용해서 도메인 영역 정의
- 전체 트리 모델에 의존성을 갖는 모든 로직이 모였던 부분이 결국 이 세 가지 데이터만 제공하는 형태로 정리가 되면 전체 트리 모델에 의종성을 갖는 도메인 로직만 남게 됨
- 도메인 로직을 좀 더 세분화시키면 크게 세 가지 형태의 도메인 로직으로 정리 (행위에 맞는 데이터를 활용할 수 있도록 조회 모델을 한번 더 정리해나갈 수 있었음)
- 노출 가능 카탈로그 목록 제공
- 카탈로그, 카탈로그 목록 제공
- 상품, 상품 목록 제공
- 전체 트리 모델을 제거하면서 결과적으로 도메인 로직에 필요로 하는 데이터를 제공하기 위한 조회 모델을 실질적으로 생성하고 설계할 수 있었음
- 조회 모델은 성능의 이점을 살리기 위해 극도로 비정규화된 형태
- 이용하고자 하는 로직에 맞게 그대로 제공해야 하는 것이 CQRS의 권고 사항
- 전체 트리 모델이 이미 모두 갖고 있던 정보이기 때문에 전체 트리를 만들던 로직을 잘게 쪼개 주는 수준으로 정리할 수 있었음
- 조회 모델 추출 전에는 전체 트리 모델에 의존하고 각 로직 별로 캐시에 의존했던 구조가 기존 전체 트리 모델 하나에 의존하던 로직을 적절한 조회 모델로 분리해줌으로써 도메인 로직 그리고 비즈니스 로직으로 전달하는 모델이 보다 깔끔하게 레이어가 나뉘게 됨
- 전체 트리에 필요한 정보만 나누어 조회 모델에만 캐시를 적용하기 때문에 캐시 트래픽에 대한 부담도 줄여줄 수 있었음
- 최종 그림은 명령 모델에서 변경 사항을 이벤트로 전달하는 이벤트 소싱 패턴을 도입
- 팀이 다른 상태에서 명령 모델을 다루는 쪽 코드에 깊게 관여하기 힘듦
- 변경 감지할 데이터를 선별 후 명령 모델을 다루는 쪽에 영향을 최소화하면서 팀 자체적으로 도입하는 것이 목표
- 인프라나 각종 개발 환경도 최대한 기존에 이용하던 기술 위주로 구성
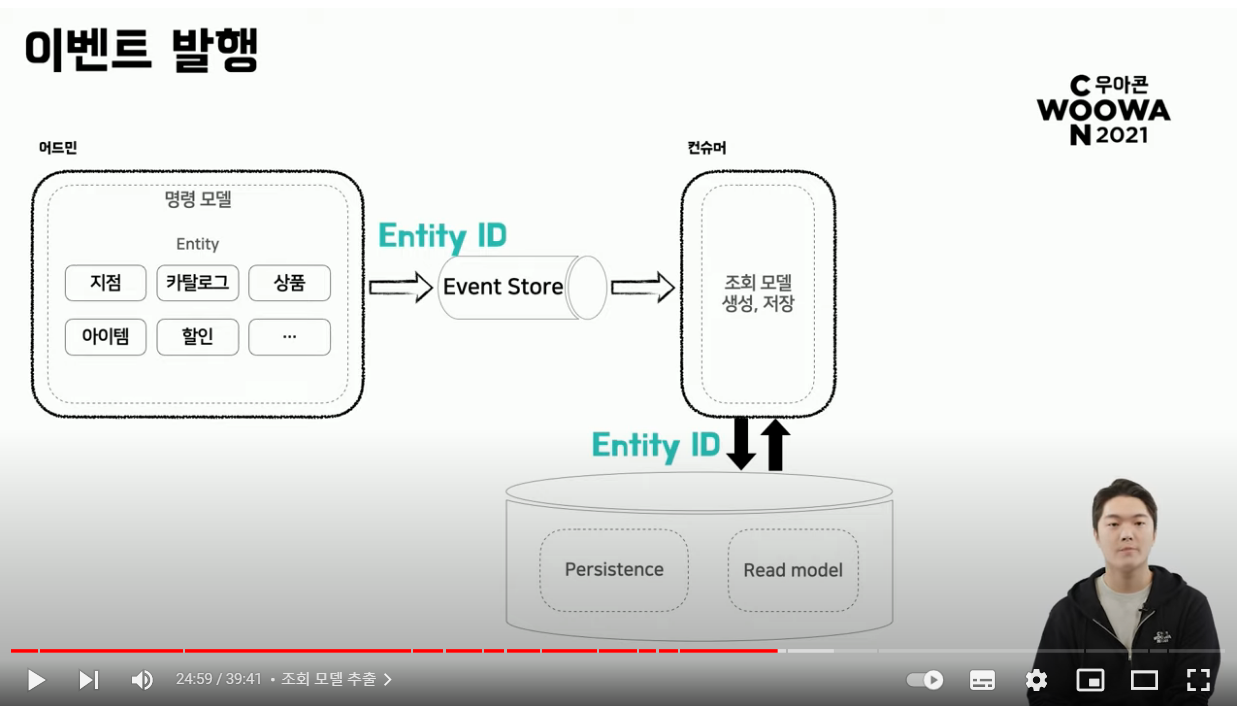
- 이벤트 소싱 패턴을 도입하기 위해서는 어떠한 데이터를 감지하고 어떠한 이벤트를 발행할지 정의하는 것이 필요
- 변경 감지하는 데 사용될 인터페이스 구현
- 해당 인터페이스를 엔티티가 상속받아 다음과 같은 정보들을 optional 하게 전달해야 함
- 엔티티 변경에 따라 갱신해야 할 대상 (카탈로그 or 상품) id
- 해당 엔티티가 변경되었을 때 수정해야 할 대상은 더 상위에 존재할 수 있기 때문에 상품이 변경되었을 때도 카탈로그를 갱신되어야 한다던가와 같은 option 부여 필요
- 변경 감지할 property 지정 - Optional
- 모든 속성을 추적하다 보면 필요치 않음에도 성능에 큰 영향을 주는 경우 존재
- 실행 Method 지정
- 생성 수정 삭제 중 특정 메서드 실행 시에만 동작하는 것이 마찬가지로 성능면에서 이점을 줄 수 있음
- 데이터 변경자명
- 관리 측면에서 어떤 유저 혹은 언제 변경되었는지에 대한 로그성 데이터도 전달받고 있음
- 엔티티 변경에 따라 갱신해야 할 대상 (카탈로그 or 상품) id
- 해당 인터페이스를 엔티티가 상속받아 다음과 같은 정보들을 optional 하게 전달해야 함
- 변경 내역 전체를 전송하게 되면 조회 모델에 반영할 때 로직이 오히려 복잡해질 수 있음
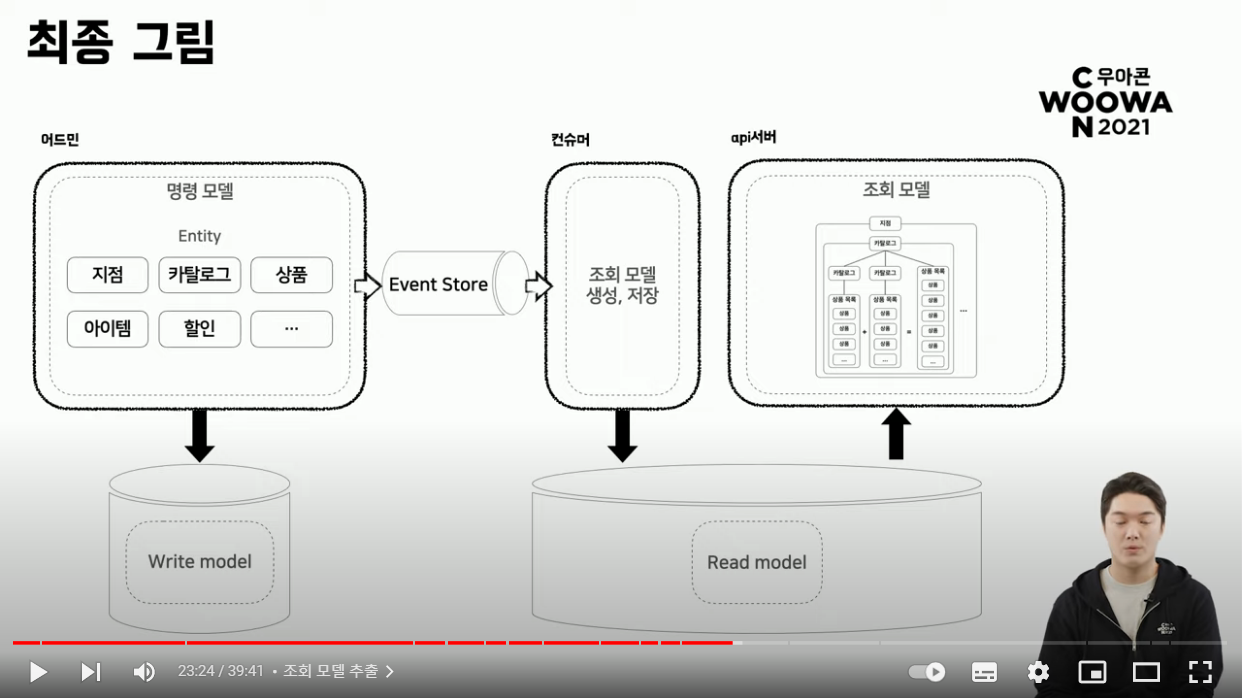
- Entity ID만 전송하는 Zero Payload 방식 도입
- Persistence 데이터에 바로 접근할 수 있고 해당 데이터로부터 데이터를 또다시 뽑아와서 가장 최신의 상태를 조회 모델을 생성할 수 있기 때문에 Entity Id만 전달하는 구조
3.4 데이터 변경 감지하기
변경 감지 방법
- JPA EntityListeners
- Hibernate EventListener
- Hibernate Interceptor
- Spring AOP
- 내려갈수록 추상화 레벨이 낮아짐
3.4.1 JPA EntityListeners
- 가장 추상화되어 있고 가장 사용하기 간편함
- @Entity 혹은 @MappedSuperclass 객체 메소드에 어노테이션 지정으로 사용 가능
- Entity 변경 라이프사이클 발생 시 원하는 시점 Callback 받을 수 있음
- Callback 리스너 클래스를 따로 구현해서 @EventListener 함께 이용하면 Callback 받을 수 있음
- 대신 해당 엔티티만 콜백 인자로 넘겨받기 때문에 Entity가 어떤 데이터로부터 어떤 데이터로 전달받기 때문에 추적하기 힘듦
3.4.2 Hibernate(v5.4) - EventListener (기본으로 이용)
- SessionFactoryImpl -> SessionFactoryServiceRegistry -> EventListenerRegistry
- 26가지 디테일한 상황에 콜백 (앞선 EntityListeners보다 다양한 상황에 콜백 받을 수 있음)
- 받고자 하는 상황에 따른 인터페이스를 구현한 클래스 등록
- 보다 상세한 정보 전달 (변경된 프로퍼티, 이전 상태, 현재 상태 등)
- 모든 엔티티 변경 사항이 전달됨
- 원하는 엔티티 걸러내는 작업 필요
3.4.3 Hibernate Interceptor
- Session 혹은 SessionFactory에 Interceptor 등록 가능
- EventListener에 비해 적은 콜백 종류 (추상화 덜 되어 있음)
- 저장될 데이터를 intercept 시점에 조작할 수 있는 강력하지만 위험한 기능 보유
- B마트에서는 단순한 콜백과 hooking이 필요했기 때문에 사용하지는 않음
3.4.4 Spring AOP (Entity를 다룰 때 성능 상의 이슈로 deleteInBatch와 같이 EntityManager 라이프사이클을 타지 않고 단순 쿼리로 실행되는 경우에만 예외 적용)
- Method에만 설정 가능
- Method 실행 전/후, 반환 후, 예외 사항, 어노테이션 붙은 경우 Pointcut 문법으로 동작
- 하지만, Pointcut 관리가 힘들고 신규로 생기거나 사용될 메서드를 매번 대응할 수 없기 때문에 부득이한 경우에만 사용
3.5 이벤트 발행하기
- 실제로 데이터 변경을 감지했다면 publish 클래스를 소개했듯이 이벤트 발행해야 함
- 이미 전사적으로 쓰고 있던 환경 (Amazon SNS, SQS) 활용
- spring-cloud-starter-aws-messaging 디펜던시만 추가하면 쉽게 사용 가능
- Amazon SNS
- 연결된 여러 시스템에 이벤트를 뿌려주는 역할을 하는 서비스
- 이벤트 발행 시 여러 개의 큐, 람다, api 요청 등으로 전파할 수 있는 영역
- 같은 아마존의 SQS 서비스와 연결 설정이 매우 간편하고 SQS만 사용해도 큐의 이벤트를 발행하고 구독할 수 있는 장점
- 여러 큐를 등록하고 확장성을 위해 SNS를 추가적으로 이용
3.6 이벤트 받기
- 퍼블리싱한 메시지를 수신
- AWS-SQS 사용
- 매우 간단한 큐 서비스
- SNS에 연결이 쉽고 메시지 유지, 누락 방지, dead-live queue 큐 서비스가 갖추어야 할 기본적인 기능 제공
- SQS 설정은 spring-cloud-starter에서 이벤트를 수신할 때 이용하는 클라이언트의 설정이 이미 제공되지만 이를 overriding 가능
- B마트에서는 Custom SQS 메시지 폴링 설정과 Message Converter 등록
3.7 이벤트 처리하기
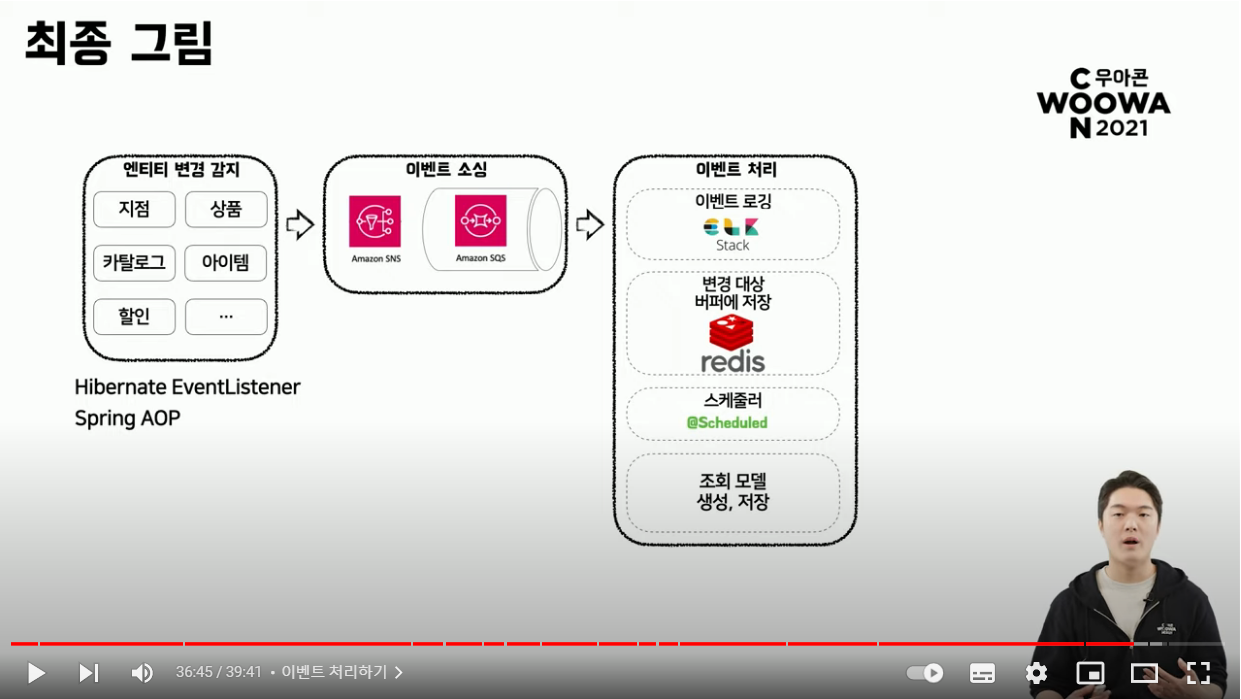
- 이벤트에 실어서 보낸 entity id를 기반으로 원하는 조회 모델을 비정규화하여 저장하고 있음
- 비효율적인 부분이 발생
- 메시지가 안건으로 연속적으로 발생할 때 조회 모델을 갱신하게 되면 DB를 향한 요청 수가 너무 상승하게 됨
- ex) 상품 순서 변경과 같이 드래그로 한 번에 이루어지고 약 백개, 수 백개 한 번에 업데이트하는 경우 이벤트를 개별적으로 처리하는 것은 매우 비효율적
- 해결하기 위해 전송받은 이벤트를 ELK를 통해 로깅하는 절차를 거치고 레디스를 버퍼로 활용하여 이벤트를 저장
- 스프링 스케줄러를 이용해서 10초에 한 번씩 버퍼의 모든 요청을 가져온 다음 조회 모델을 벌크로 생성하고 저장
- 최대한 데이터의 정합성을 보장하기 위해 매시간 Full Batch를 돌아 모든 조회 모델을 생성하고 저장해주고 있음
3.8 전환하는데 걸린 기간
- 과거 코드를 정리하고 전체적인 구조를 CQRS 모습을 띄는 작업을 수행하는데 2개월 정도 소요
- 모니터링에 좀 더 신경 쓰면서 안정화 작업을 이루는데 6개월 정도 소요
- 이미 서비스를 개발하고 다른 조직과의 협업으로 인해 저희가 활용하고 있던 인프라 환경 위에서 개발했기 때문에 비교적 빨리 도입할 수 있었음
4. 아쉬운 점과 앞으로의 CQRS
4.1 엔티티 변경 감지
- Hibernate 의존적
- 쿼리를 직접 실행시키는 로직 예외처리 필요
- 기존 엔티티에 추가 작업 필요
- 이벤트 발행 시 전송할 ID 정보 메서드 정보 등의 작업을 엔티티에 작업하는 것이 필요
- 엔티티 입장에서 필요 없는 로직이 추가됨
4.2 이벤트 소싱
- AWS 계정 당 TPS 제한
- 배달의민족 전체에서 이용하는 계정은 하나이기 때문에 이슈 발생
- 애플리케이션 코드 기반 이벤트 퍼블리싱
- 너무 기본적인 Queue 기능만 제공하기 때문에 보다 확장성 있고 최대한 CQRS를 적용하면서 추가된 도메인 로직들이 다른 곳에 영향을 주지 않도록 또 다른 해결책 검토
- 이를 해결하기 위해 Persistence Data, 즉 데이터베이스의 변경 사항을 소싱할 수 있는 CDC (Change Data Capture) 검토 중
- ex) 데이터 소스와 Kafka 연결을 제공하는 Kafka Connect
- CDC 구현 및 아쉬운 큐 기능도 Kafka가 커버해주면서 두 마리 토끼를 잡을 수 있음
- 기존 구조에서 명령 모델과 관련된 엔티티들을 건드릴 수밖에 없었던 부분을 모두 제거 가능
- 단순히 persistence 데이터에서 Kafka Connect를 통해 데이터 변경 사항을 구독하고 이를 Kafka로 전달하면 이후에는 이미 구현해 놓은 구조로 동작할 수 있을 것으로 판단
- 또, 이후에 전시 도메인은 MSA나 consumer 또한 별도의 프로젝트로 구분 가능할 것으로 기대 중
'리서치' 카테고리의 다른 글
| [Springboot] Jpa 프로젝트에 jOOQ 도입 (6) | 2023.10.03 |
|---|---|
| [Springboot] 멀티 데이터소스 (MyBatis, JPA) (11) | 2023.03.25 |
| [MSA] 11번가 Spring Cloud 기반 MSA로의 전환 정리 (2) | 2022.10.29 |
| [MSA] 우아콘 2020 배달의민족 마이크로서비스 여행기 정리 (4) | 2022.10.27 |
| [tus protocol] 재개 가능한 파일 업로드를 위한 오픈 프로토콜 (8) | 2022.10.06 |