개요
MSA 관련 리서치를 맡게 돼서 공부하는 도중 김영한 강사님이 발표해주신 우아콘 2020 영상을 인상 깊게 봐서 간단하게 요약/정리했습니다.
인프런 강의를 시청할 때도 느꼈지만 김영한 강사님은 어려운 개념을 친절하면서 이해하기 쉽게 설명하시는 능력을 소유하신 것 같습니다.
MSA에 관심 있으신 분들은 풀 영상 시청 추천드립니다.
https://www.youtube.com/watch?v=BnS6343GTkY&ab_channel=%EC%9A%B0%EC%95%84%ED%95%9CTech
1. 마이크로 서비스 전환 전
2015년
- 하루 주문 수 5만 이하
- MS SQL + PHP, ASP
- 대부분 루비 DB(MSSQL) stored procedure 방식 사용
- 루비 DB 장애 시 전체 서비스 장애가 나는 문제 있었음
- 테이블은 700개 이상, stored procedure 4000개 이상으로 구성된 거대한 monolithic system
- 서비스 단위로 나누어 애플리케이션을 별도로 배포했을지라도 모두 하나의 루비 DB를 바라보고 있었기 때문에 루비 DB 장애 시 전체 시스템 장애
- ex) 리뷰 서비스에 장애가 났는데 주문 서비스에도 장애가 발생
- 하루 주문 수가 5만 일 때도 장애가 발생하는데 추후 100만 건이 넘어갔을 때도 현재와 같이 거대한 Monolithic 시스템일 경우 문제가 발생할 것이 자명
- Netflix가 MSA 구축을 잘한 것으로 유명한데 넷플릭스도 순수 리서치를 목적으로 MSA 구축을 한 것이 아니라 장애 대응 즉, 생존을 위해 전환
- 배달의 민족도 마찬가지 케이스
- 지속적으로 트래픽이 늘어남에 따라 대응하고 스케일 하기 위해서는 마이크로 서비스로 넘어갈 수밖에 없는 상황
2. 마이크로서비스로 전환 시작
2016년
- 하루 주문 수 10만 돌파
- PHP -> 자바로 전환
- 대용량 트래픽 대응 가능한 기술을 자바에서 많이 제공
- 자바 개발자 수가 많기 때문에 수급이 원활함
- 마이크로 서비스 아키텍처 도전 시작
- 리뷰 시스템이 죽었는데 결제 시스템이 죽는 케이스가 발생해서는 안됨
- 결제 서비스와 주문 중계 서비스를 마이크로 서비스로 독립 (각각 별도 DB를 가짐)
- IDC에서 AWS 클라우드 인프라로 이전하기 시작
- 첫 자바 마이크로서비스 등장 (결제)
- 완전히 DB가 분리된 것을 마이크로 서비스라고 칭함
- 결제 서비스를 마이크로 서비스로 분리하더라도 결제 서비스에 장애가 나면 문제가 발생하는 것 아닌가요?
- 결제 장애가 발생해도 배달의민족은 전화 주문을 할 수 있기 때문에 고객들은 전화로라도 서비스를 이용할 수 있음
- 당시만 하더라도 결제 관련 서비스를 클라우드에 올릴 수 없는 상황이라 IDC 사용 (법안 관련)
- 주문 중계 Gateway 서비스도 마이크로 서비스로 전환
- 초기에는 Node JS
- 추후 비즈니스 로직이 복잡해지면서 결국 Java 서비스로 전환
- 치킨 디도스 사태 발생
- 선착순 결제 할인 이벤트
- 오후 5시 시작 (트래픽 예상보다 훨씬 웃도는 대량 트래픽 발생)
- 고객은 프론트 서버 -> IDC 내 주문 서비스 -> 결제 마이크로 서비스 순서로 접속
- 첫날 프런트 서버가 대량 트래픽을 못 버티고 바로 죽으면서 장애 발생
- 하루 만에 IDC -> AWS로 프런트 서버 시스템 이전 (abusing을 하여 100대 증설 후 트래픽을 받음)
- 둘 째날 프런트 서버는 생존했는데 주문 서버가 죽음 (마찬가지로 IDC -> AWS로 이전 후 100대 증설)
- 세 번째나 프런트 서버, 주문, 결제 서비스 모두 대량의 트래픽으로부터 생존했는데 외부 PG사, 카드사 서비스가 죽으면서 또 장애
- PG사, 카드사 장비 수급하여 대응하여 네 번째 날 이벤트 성공

2017년
- 하루 주문 수 20만 돌파
- 대 장애의 시대
- B2C 서비스다 보니 장애 나는 순간 전 국민의 역적이 됨
- 이에 따라 생존을 위해 마이크로 서비스 가속화
- 가게 목록 + 검색을 Elasticsearch로 분리 (루비 DB 부하 줄이기 위해)
2018년 상반기
- 전사 1순위 과제를 시스템 안정성으로 선정
- 상징적인 이벤트
- 보통 사업 부서의 경우 시스템 안정성보다는 수익성이 우선임 (기업이 실제 이익을 창출해야 하기 때문)
- 엄청난 수익성을 가져와줄 서비스 개발을 일단 보류하고 장애 대응 TF를 우선 창설하여 주요 장애 포인트였던 가게 상세 서비스 재개발을 우선으로 수행함
- AWS가 죽었을 때 대응해줄 오프라인 서비스도 개발
- 루비 DB에 있는 데이터를 AWS 다이나모 DB에 1~5분 주기로 이관
- 루비 DB의 트래픽을 줄이고 가게 상세 서비스에서는 AWS 다이나모 DB를 바라보도록 수정
- 장점: 루비 DB 트래픽을 줄여 장애 발생 확률 줄임
- 단점: 싱크가 늦는다, 요구사항이 변경되면 수천 라인의 SQL 쿼리를 수정
2018년 하반기 ~
- 배달의민족에는 레거시 3 대장이 존재
- 주문 서비스(데이터 지분 1위, 하루 100만 데이터)
- 가게/업주 서비스(시스템 연관도 1위)
- 광고 서비스(stored procedure 사용 1위)
- 거의 모든 서비스와 연관된 주문 서비스를 마이크로 서비스로 전환
- 배민 주문 로직 + 라이더스 주문 로직이 분리가 되어있었는데 두 서비스의 주문 핵심 도메인을 뽑아내 통합 후 AWSRDS 신주문 테이블을 바라보도록 수정
- 기존에는 주문 LifeCycle 동안 정말 많은 외부 API를 호출했었음 (API 연동)
- 리뷰 시스템 전달
- 레거시 DB와 싱크
- 라이더스 시스템 호출
- 등등
- API를 호출했을 때 상대 서버가 죽어있을 때 데이터가 유실되는 문제 발생
- 위 문제를 해결하기 위해 이벤트 기반 데이터 전달로 변경
- AWS-SNS, AWS-SQS 도입
- 주문 시스템에서는 이벤트를 발행하고 타 시스템에서는 이벤트를 consume 해서 처리하는 방식
- 이벤트 기반 시스템의 장점은 시스템이 죽었다 살아나는 순간 SQS에 쌓여있는 이벤트를 consume 할 수 있음 (회복력, 데이터 유실이 없는 것이 장점)
- 새로운 시스템을 구축했을 때 주문 시스템에서 변경할 필요 없이 해당 시스템에서 필요한 SQS를 구축한 뒤 consume 하면 됨 (확장성 측면에서 유리)
- 장애가 줄어들기 시작
- 기존에는 주문 LifeCycle 동안 정말 많은 외부 API를 호출했었음 (API 연동)
- 남은 레거시 이대장 (가게/업주 서비스, 광고 서비스)
- 이 둘은 역사가 오래된 레거시 코드
- 모든 시스템이 루비 DB를 바라보는 구조
- 광고, 가게/업주 시스템을 마이크로 서비스로 전환해서 서비스하면 그만 아닌가?
- 장애 대응이 어려운 문제가 있음
- ex) 광고 시스템 장애 -> 광고 시스템을 api로 호출하는 모든 서비스가 연쇄적으로 장애 발생
- ex) 고성능 조회 장애 -> 대량의 트래픽이 순간적으로 확 몰려왔을 때 api 호출 방식을 사용할 때 모든 서비스에 다 트래픽이 퍼지는 문제
- 프로젝트 먼데이 시작(월요일에 시작되었다고 해서 프로젝트 먼데이)
- 먼데이 아키텍처 고려사항 3 가지
- 성능
- 대용량 트래픽 대응
- 메인, 가게 리스트, 가게 상세 API는 15,000 TPS
- 모든 시스템이 대용량 트래픽을 감당하기 어려움
- 장애 격리
- 가게, 광고 같은 내부 서비스나 DB에 장애가 발생해도 고객 서비스를 유지하고 주문도 가능해야 함
- 데이터 동기화
- 마이크로 서비스를 하기 때문에 데이터를 동기화해야 함
- 성능
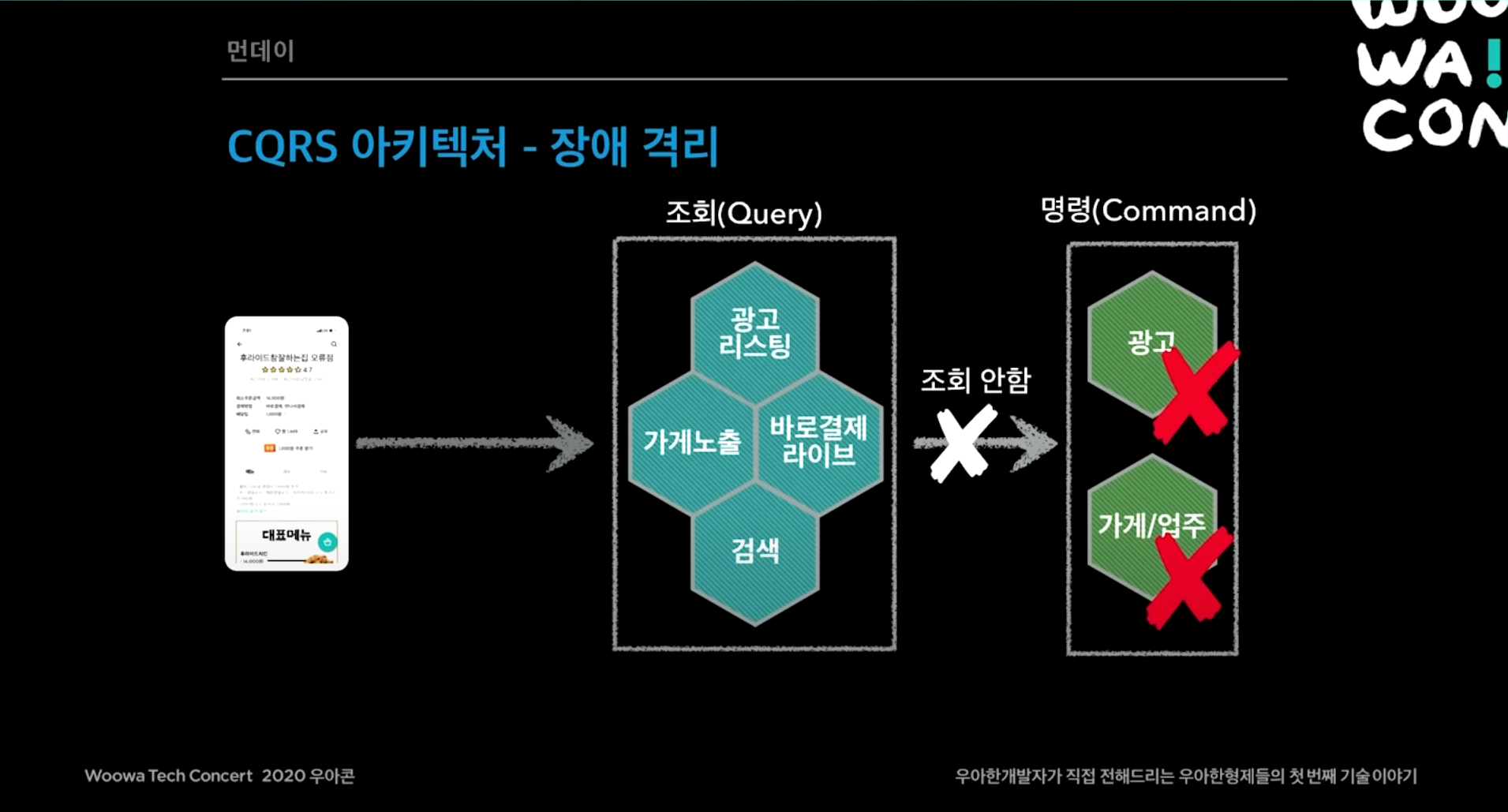
- 이에 따라 배달의민족 전체 서비스를 CQRS 아키텍처 도입 (Command and Query Responsibility Segregation)
- 핵심 비즈니스 명령(Command) 시스템
- ex) 광고 등록, 가게/업주 등록 및 변경 이벤트 발행
- 조회(Query) 중심의 사용자 서비스
- ex) 광고 리스팅, 가게 노출, 검색 서비스에서 SQS에서 consume 방식
- 위 두 서비스를 철저하게 분리
- 이벤트 전파와 동기화
- Eventually Consistency (이벤트 기반 시스템을 도입하면 언젠가는 데이터 싱크가 맞춰진다.)
- 데이터 싱크 맞추는데 소요되는 시간: 1초 ~ 3초
- 문제 발생 시 해당 시스템이 이벤트만 재발행
- 대부분 Zero-Payload 방식 사용
- 이벤트에 식별자(ex 가게 ID)와 최소한의 정보만 발행
- 이벤트를 받은 시점에 조회 API로 필요한 데이터를 조회해서 저장
- 각 시스템마다 원하는 데이터가 다르므로 다른 API를 사용
- 동일 이벤트, 다른 API
- 최소 데이터 보관 원칙
- 각 서비스는 자신에게 필요한 최소 데이터만 보관하는 원칙 준수
- 물리적인 dependency는 없지만 데이터를 가지고 있으면서 논리적인 dependency가 발생할 수 있으므로 최소한만 보관
- 각 시스템들은 각 서비스가 최대한 최적화할 수 있는 DB를 사용
- 성능이 중요한 조회 쪽은 Redis나 DynamoDB, MongoDB 쓰고
- ex) 광고 리스팅은 Elasticsearch
- Command성은 오로라 DB
- 성능이 중요한 조회 쪽은 Redis나 DynamoDB, MongoDB 쓰고
- 가게 목록 조회 - 통합, CQRS Query Model (Data를 플랫하게 관리)
- 광고 리스팅, 검색, 그리고 찜 시스템 같은 애들은 가게 ID만 반환하면 빠르게 key-value로 조회해서 반환하는 방식
- 가게 상세 조회할 때 비동기 Non-blocking 방식으로 조회해서 성능을 높임
- CQRS의 장점은 트래픽이 증가하더라도 뒷단은 호출하지 않아 조회용 서비스만 트래픽 받음
- 광고나 가게 상세 서비스가 죽더라도 주문 서비스로 넘어갈 수 있음
주문 서비스가 죽으면 무용지물이긴 하지만
- 장애 격리
- 각 시스템이 내부에 필요한 데이터 보관
- 내부 서비스(광고, 검색)의 모든 변경 내역이 이벤트로 전달
- 장애 시 데이터 싱크가 늦어져도 고객 서비스 가능
- 데이터 싱크 장애 대응
- 이벤트 재발행
- SQS SNS 자체 장애 발생 시?
- 전체 IMPORT API 제공
- 부분 IMPORT API 제공
- 최근 업데이트 데이터를 분 단위로 부분 제공
- 배치를 돌려 sync를 맞춤
- 기타
- 적극적인 캐시 사용
- 서킷 브레이커 (Resiliance4J)
- 비동기 Non-blocking 시스템 적용
- 스프링 WebFlux, Reactor
- 가게 노출, 광고 리스팅, 검색
-
- 핵심 비즈니스 명령(Command) 시스템






3. 정리
- 배달의 민족 시스템은 거대한 CQRS 아키텍처
- 성능이 중요한 외부 시스템과 비즈니스 명령이 많은 내부 시스템으로 분리
- 이벤트 발행을 통한 데이터 sync Eventually Consistency
- 각 시스템은 API 또는 이벤트 방식으로 연동
- 모든 통신을 이벤트 방식으로 변경하는 것은 현실적으로 불가능
- API 사용하는 경우 실패 시 Fallback 적절히 구현 필요
- 먼데이 프로젝트 이후 모든 서비스를 마이크로 서비스 아키텍처로 전환하고 Monolithic 한 루비 DB로부터 독립 성공
- 마이크로 서비스를 꼭 해야 하나?
- 규모의 경제가 뒷받침돼야 함 (서비스도 커야 하고, 트래픽도 많아야 하고)
- 기존에는 테이블 조인만 해도 될 일을 마이크로 서비스로 전환 시 데이터 싱크 맞춰야 하는 번거로움이 생김
- 이러한 비용을 다 상쇄할 만큼 규모의 경제가 뒷받침된다면 마이크로 서비스로 전환 추천
- Netflix는 MSA로 전환하는데 7년, 11번가는 18개월, 그리고 배달의민족도 상당히 오래 걸렸던 것으로 보아 많은 공수가 투입되는 작업이므로 MSA로 전환 시도 시 다양한 관점을 고려한 후 진행할 필요가 있음
4. 비고
Stored Procedure
https://devkingdom.tistory.com/323
[MSSQL] 저장 프로시저 (Stored Procedure) 란?
실무에서는 프로그램에서 만들어 놓은 SQL문을 저장해 놓고, 필요할 때마다 호출해서 사용하는 방식으로 프로그램을 만든다. 저장 프로시저 (Stroed Procedure) 저장 프로시저는 이러한 방식이 가능
devkingdom.tistory.com
이벤트 기반 아키텍처
https://techblog.woowahan.com/7835/
회원시스템 이벤트기반 아키텍처 구축하기 | 우아한형제들 기술블로그
{{item.name}} 최초의 배달의민족은 하나의 프로젝트로 만들어졌습니다. 배달의민족의 주문수는 J 커브를 그리는 빠른 속도로 성장했고, 주문수가 커지면서 자연스럽게 트래픽 또한 매우 커졌습니
techblog.woowahan.com
CQRS 패턴
나만 모르고 있던 CQRS & EventSourcing | Popit
CQRS는 네이밍에서 알 수 있듯이 명령과 쿼리의 역할을 구분 한다는 것이다. 즉 커맨드 ( Create – Insert, Update, Delete : 데이터를 변경) 와 쿼리 ( Select – Read : 데이터를 조회)의 책임을 분리한다는
www.popit.kr
Zero Payload 방식
MSA 구성시 이벤트 방식에서 zero-payload 적용
시스템이 너무 복잡해져서 ROI 등을 따져서 적절하게 MSA로 전환하는데, 이벤트 방식으로 데이터 변경 사항을 전파시(loose 커플링, 장애 복구성 등의 장점 때문에) 순서에 대한 보장의 문제 등을
blog.eomsh.com
'리서치' 카테고리의 다른 글
| [Springboot] 멀티 데이터소스 (MyBatis, JPA) (11) | 2023.03.25 |
|---|---|
| [MSA] CQRS 패턴과 실제 적용 사례 (4) | 2022.10.31 |
| [MSA] 11번가 Spring Cloud 기반 MSA로의 전환 정리 (2) | 2022.10.29 |
| [tus protocol] 재개 가능한 파일 업로드를 위한 오픈 프로토콜 (8) | 2022.10.06 |
| [SpringBoot + Fastexcel] 대용량 엑셀 생성 및 다운로드 (14) | 2022.09.14 |