앞서 아이템 10에서도 언급했다시피 equals를 오버라이딩했다면 hashCode 메서드도 같이 재정의해야 합니다.
hashCode 메서드를 재정의하지 않을 경우 아래에 명시할 hashCode 일반 규약을 어기게 되어 해당 클래스의 인스턴스를 HashMap 혹은 HashSet 같은 컬렉션의 원소로 사용할 때 문제를 일으킬 것입니다.
- 두 객체에 대한 equals가 같다면, hashCode의 값도 동일해야 함
- equals 비교에 사용하는 정보가 변경되지 않았다면 hashCode는 매번 같은 값을 반환
- 단, 정보가 변경되었거나 애플리케이션을 재기동했을 경우 변경될 수 있음
- 두 객체에 대한 equals가 다르더라도 hashCode의 값은 같을 수 있지만 해시 테이블 성능을 고려해 다른 값을 리턴하는 것이 좋음
이번 게시글에서는 왜 앞서 언급한 hashCode 규약을 따라야 하는지와 hashCode 구현 방법에 대해서 간단히 알아보겠습니다.
hashCode 규약
1. 두 객체에 대한 equals가 같다면, hashCode의 값도 동일해야 함
해당 규약을 따라야 하는 이유는 간단한 예제 코드를 통해 확인이 가능합니다.
전화번호를 key, 사용자를 value로 HashMap에 넣었을 때 전화번호는 고유하기 때문에 전화번호로 조회 시 항상 같은 사람이 값으로 출력되어야 합니다.
하지만 equals 메서드만 재정의하고 hashCode 메서드는 별도로 재정의하지 않아 매번 다른 값이 나올 경우 위 원칙이 깨지는 것을 확인할 수 있습니다.
| public final class PhoneNumber { | |
| private final short areaCode, prefix, lineNum; | |
| public PhoneNumber(int areaCode, int prefix, int lineNum) { | |
| this.areaCode = rangeCheck(areaCode, 999, "area code"); | |
| this.prefix = rangeCheck(prefix, 999, "prefix"); | |
| this.lineNum = rangeCheck(lineNum, 9999, "line num"); | |
| } | |
| private static short rangeCheck(int val, int max, String arg) { | |
| if (val < 0 || val > max) { | |
| throw new IllegalArgumentException(arg + ": " + val); | |
| } | |
| return (short)val; | |
| } | |
| @Override | |
| public boolean equals(Object o) { | |
| if (o == this) { | |
| return true; | |
| } | |
| if (!(o instanceof PhoneNumber)) { | |
| return false; | |
| } | |
| PhoneNumber pn = (PhoneNumber)o; | |
| return pn.lineNum == lineNum | |
| && pn.prefix == prefix | |
| && pn.areaCode == areaCode; | |
| } | |
| } | |
| public class HashMapTest { | |
| public static void main(String[] args) { | |
| Map<PhoneNumber, String> map = new HashMap<>(); | |
| PhoneNumber number1 = new PhoneNumber(123, 456, 7890); | |
| // 같은 인스턴스인데 다른 hashCode | |
| System.out.println(number1.hashCode()); | |
| System.out.println(new PhoneNumber(123, 456, 7890).hashCode()); | |
| map.put(number1, "jaimemin"); | |
| /** | |
| * equals가 같은데 hashcode가 매번 다를 경우 | |
| * | |
| * get을 할 때 hashmap에 넣는 과정과 꺼내는 과정을 이해해야 함 | |
| * key에 대한 hashcode를 먼저 가져와서 hash에 해당하는 bucket에 넣고 뺀다 | |
| * hashcode가 매번 다를 경우 hashmap에는 이런 hash가 없는데?하면서 null이 나오는 것 | |
| */ | |
| String s = map.get(new PhoneNumber(123, 456, 7890)); // null | |
| System.out.println(s); | |
| } | |
| } |

재정의한 equals 메서드에 의해 두 객체는 논리적으로 동치이지만 hashCode 메서드가 반환하는 값이 달라 HashMap에서 매핑을 못하는 것을 확인할 수 있습니다.
2. equals 비교에 사용하는 정보가 변경되지 않았다면 hashCode는 매번 같은 값을 반환
위 규약의 대우는 " 만약 hashCode가 항상 동일한 값을 반환하지 않는다면, equals 비교에 사용된 정보가 변경되었다는 것 "이기 때문에 1번 규약과 똑같은 내용입니다.
2번 규약을 지키기 위해서는 아래 코드처럼 equals 비교에 사용되는 핵심적인 필드는 hashCode에도 모두 사용되어야 합니다.
- equals 메서드에 사용되지 않은 필드는 hashCode에서도 배제해야 함
| public final class PhoneNumber { | |
| private final short areaCode, prefix, lineNum; | |
| public PhoneNumber(int areaCode, int prefix, int lineNum) { | |
| this.areaCode = rangeCheck(areaCode, 999, "area code"); | |
| this.prefix = rangeCheck(prefix, 999, "prefix"); | |
| this.lineNum = rangeCheck(lineNum, 9999, "line num"); | |
| } | |
| private static short rangeCheck(int val, int max, String arg) { | |
| if (val < 0 || val > max) { | |
| throw new IllegalArgumentException(arg + ": " + val); | |
| } | |
| return (short)val; | |
| } | |
| @Override | |
| public boolean equals(Object o) { | |
| if (o == this) { | |
| return true; | |
| } | |
| if (!(o instanceof PhoneNumber)) { | |
| return false; | |
| } | |
| PhoneNumber pn = (PhoneNumber)o; | |
| return pn.lineNum == lineNum | |
| && pn.prefix == prefix | |
| && pn.areaCode == areaCode; | |
| } | |
| @Override | |
| public int hashCode() { | |
| return Objects.hash(lineNum, prefix, areaCode); | |
| } | |
| } |
3. 두 객체에 대한 equals가 다르더라도 hashCode의 값은 같을 수 있지만 해시 테이블 성능을 고려해 다른 값을 리턴하는 것이 좋음
위 내용은 hash 충돌 즉, hash collision과 관련된 내용입니다.
hashCode 반환 값이 같다고 해서 HashMap 혹은 HashSet 값이 덮어씌워지는 것은 아니기 때문에 동작하는데 문제는 없지만 해시 충돌이 발생하여 같은 버켓에 대해 링크드 리스트가 형성되므로 시간 복잡도가 O(1)에서 O(N)으로 증가하는 성능 저하가 발생합니다.
Java 8+ 버전부터는 같은 버킷에 대해 해시 충돌이 8번 이상 발생될 경우 성능 향상을 위해 링크드 리스트에서 red-black 트리를 사용하도록 변경되어 시간복잡도가 O(N)에서 O(logN)으로 개선되지만 근본적으로 2^32 - 1 정수 범위 내에서 8번이나 해시 충돌이 나는 것은 적합하지 않은 hashCode 메서드를 썼다는 것을 반증합니다.
아래 코드는 hashCode가 같을 때와 다를 때 HashMap에 넣고 빼는 과정에서 시간 차이가 발생하는 것을 확인할 수 있습니다.
비록 예제 코드에서는 item을 1000개 밖에 넣지 않았지만 시간 복잡도에 의해 item이 증가할수록 실행 시간 격차는 더 벌어질 것이 자명합니다.
객체의 논리적 동치성이 다르더라도 hashCode가 같을 때
| public final class PhoneNumber { | |
| private final short areaCode, prefix, lineNum; | |
| public PhoneNumber(int areaCode, int prefix, int lineNum) { | |
| this.areaCode = rangeCheck(areaCode, 999, "area code"); | |
| this.prefix = rangeCheck(prefix, 999, "prefix"); | |
| this.lineNum = rangeCheck(lineNum, 9999, "line num"); | |
| } | |
| private static short rangeCheck(int val, int max, String arg) { | |
| if (val < 0 || val > max) { | |
| throw new IllegalArgumentException(arg + ": " + val); | |
| } | |
| return (short)val; | |
| } | |
| @Override | |
| public boolean equals(Object o) { | |
| if (o == this) { | |
| return true; | |
| } | |
| if (!(o instanceof PhoneNumber)) { | |
| return false; | |
| } | |
| PhoneNumber pn = (PhoneNumber)o; | |
| return pn.lineNum == lineNum | |
| && pn.prefix == prefix | |
| && pn.areaCode == areaCode; | |
| } | |
| /** | |
| * 두 객체에 대한 equals가 다르더라도 hashcode가 다를 경우 | |
| * hash collision | |
| * hash bucket 오브젝트를 linked list로 만들어줌 | |
| * O(1) -> O(N)으로 시간복잡도가 아쉬워짐 | |
| */ | |
| @Override | |
| public int hashCode() { | |
| return 13; | |
| } | |
| public static void main(String[] args) { | |
| Map<PhoneNumber, String> m = new HashMap<>(); | |
| List<PhoneNumber> phoneNumbers = new ArrayList<>(); | |
| int middleDigits = 0; | |
| int lastDigits = 0; | |
| long start = System.nanoTime(); | |
| for (int i = 0; i < 1000; i++) { | |
| PhoneNumber phoneNumber | |
| = new PhoneNumber(123, middleDigits++, lastDigits++); | |
| phoneNumbers.add(phoneNumber); | |
| m.put(phoneNumber, UUID.randomUUID().toString()); | |
| } | |
| for (PhoneNumber phoneNumber : phoneNumbers) { | |
| System.out.println(m.get(phoneNumber)); | |
| } | |
| long end = System.nanoTime(); | |
| System.out.println(String.format("소요시간 %d", end - start)); | |
| } | |
| } |
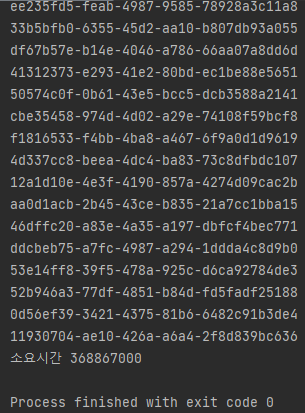
객체의 논리적 동치성이 다를 경우 hashCode도 다를 때
| public final class PhoneNumber { | |
| private final short areaCode, prefix, lineNum; | |
| public PhoneNumber(int areaCode, int prefix, int lineNum) { | |
| this.areaCode = rangeCheck(areaCode, 999, "area code"); | |
| this.prefix = rangeCheck(prefix, 999, "prefix"); | |
| this.lineNum = rangeCheck(lineNum, 9999, "line num"); | |
| } | |
| private static short rangeCheck(int val, int max, String arg) { | |
| if (val < 0 || val > max) { | |
| throw new IllegalArgumentException(arg + ": " + val); | |
| } | |
| return (short)val; | |
| } | |
| @Override | |
| public boolean equals(Object o) { | |
| if (o == this) { | |
| return true; | |
| } | |
| if (!(o instanceof PhoneNumber)) { | |
| return false; | |
| } | |
| PhoneNumber pn = (PhoneNumber)o; | |
| return pn.lineNum == lineNum | |
| && pn.prefix == prefix | |
| && pn.areaCode == areaCode; | |
| } | |
| @Override | |
| public int hashCode() { | |
| return Objects.hash(lineNum, prefix, areaCode); | |
| } | |
| public static void main(String[] args) { | |
| Map<PhoneNumber, String> m = new HashMap<>(); | |
| List<PhoneNumber> phoneNumbers = new ArrayList<>(); | |
| int middleDigits = 0; | |
| int lastDigits = 0; | |
| long start = System.nanoTime(); | |
| for (int i = 0; i < 1000; i++) { | |
| PhoneNumber phoneNumber | |
| = new PhoneNumber(123, middleDigits++, lastDigits++); | |
| phoneNumbers.add(phoneNumber); | |
| m.put(phoneNumber, UUID.randomUUID().toString()); | |
| } | |
| for (PhoneNumber phoneNumber : phoneNumbers) { | |
| System.out.println(m.get(phoneNumber)); | |
| } | |
| long end = System.nanoTime(); | |
| System.out.println(String.format("소요시간 %d", end - start)); | |
| } | |
| } |

hashCode 구현 방법
hashCode 구현 방법은 아래와 같습니다.
- equals 메서드에 사용된 핵심 필드 중 하나의 값의 hash 값을 계산해서 result 값을 초기화
- 위에 사용되지 않은 각 핵심 필드에 대해 result를 31 * result + 해당 필드의 hashCode 계산값으로 업데이트
- 기본 타입은 Type.hashCode 값 사용
- 참조 타입은 해당 필드의 hashCode 값 사용
- 배열의 경우 Arrays.hashCode 값 사용
- 위에서 계산한 result 값 반환
실제로 Arrays의 hashCode 소스를 보면 비슷하게 구현한 것을 확인할 수 있습니다.
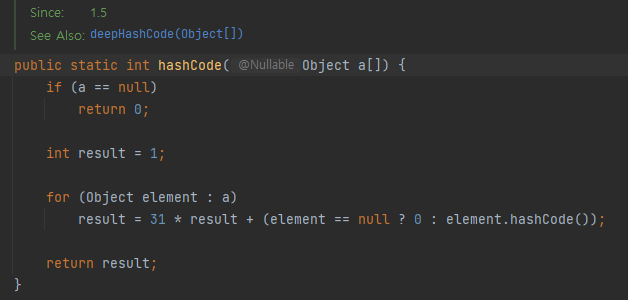
hashCode 값을 계산할 때 굳이 숫자 "31"을 사용하는 이유는 아래와 같습니다.
- 곱셈 연산의 효율성: 31을 곱하는 것은 컴파일러에서 좋은 최적화를 수행하기 쉽습니다. 31을 곱하는 것은 shift 연산과 뺄셈 연산을 사용하여 빠르게 수행될 수 있습니다. (2^5 - 1)
- 해시 충돌 최소화: 31을 사용하면 해시 충돌의 가능성이 낮아집니다. 소수를 사용함으로써 일정한 간격으로 해시 값이 변경되기 때문에 다양한 키들에 대해 해시 충돌이 적게 발생하게 됩니다.
위처럼 hashCode를 직접 재정의하는 것보다는 라이브러리의 도움을 받는 것을 추천합니다.
저자는 구글의 guava 라이브러리를 추천하지만 CafeinneCache를 사용하지 않는 이상 굳이 equals, hashCode 재정의를 위해 라이브러리를 추가하는 것은 권장하지 않는 방법입니다.
대신 대중적으로 사용하는 Lombok의 @EqualsAndHashCode 어노테이션 사용을 추천합니다.
해시 코드 구현 시 주의 사항
해시 코드 구현 시 주의 사항은 아래와 같습니다.
- 지연 초기화 기법을 사용할 때 쓰레드 안전성 고려
- 성능 때문에 핵심 필드를 해시코드 계산할 때 빼면 안 됨
- 해시코드 계산 규칙을 API에 노출하지 않는 것이 좋음
1. 지연 초기화 기법을 사용할 때 쓰레드 안전성 고려
저자는 멀티 쓰레드 환경에서도 논리적 동치성을 가지는 객체들에 대해 hashCode 메서드가 항상 같은 값을 반환해야 한다고 강조합니다.
불변 객체의 경우 hashCode를 필드로 정의하여 해시코드를 지연 초기화하는 기법을 많이 사용하는데 이때 다수의 쓰레드가 동시에 hashCode 메서드에 들어오면 엇갈리면서 계산해서 간혹 다른 값이 반환될 수도 있습니다.
- 사실 그럴 일은 거의 없다고 보지만 혹시 모르니...
따라서 쓰레드 안전성을 고려하여 volatile과 synchronized 키워드를 사용해야 합니다.
volatile 키워드가 붙은 필드의 경우 캐시가 아닌 메인 메모리에서 참조하기 때문에 가장 최근에 업데이트된 값이 반환되며 synchronized는 한 쓰레드가 점유했을 때 다른 쓰레드가 접근 못하도록 lock을 거는 역할입니다.
| public final class PhoneNumber { | |
| private final short areaCode, prefix, lineNum; | |
| public PhoneNumber(int areaCode, int prefix, int lineNum) { | |
| this.areaCode = rangeCheck(areaCode, 999, "area code"); | |
| this.prefix = rangeCheck(prefix, 999, "prefix"); | |
| this.lineNum = rangeCheck(lineNum, 9999, "line num"); | |
| } | |
| private static short rangeCheck(int val, int max, String arg) { | |
| if (val < 0 || val > max) { | |
| throw new IllegalArgumentException(arg + ": " + val); | |
| } | |
| return (short)val; | |
| } | |
| @Override | |
| public boolean equals(Object o) { | |
| if (o == this) { | |
| return true; | |
| } | |
| if (!(o instanceof PhoneNumber)) { | |
| return false; | |
| } | |
| PhoneNumber pn = (PhoneNumber)o; | |
| return pn.lineNum == lineNum | |
| && pn.prefix == prefix | |
| && pn.areaCode == areaCode; | |
| } | |
| private volatile int hashCode; // 자동으로 0으로 초기화된다. | |
| @Override | |
| public int hashCode() { | |
| // 공유 필드가 이미 세팅되었다면 바로 반환 | |
| if (this.hashCode != 0) { | |
| return hashCode; | |
| } | |
| // lock을 걸어 동기화 (한 쓰레드만 들어갈 수 있도록) | |
| // double checking lock | |
| synchronized (this) { | |
| int result = hashCode; | |
| if (result == 0) { | |
| result = Short.hashCode(areaCode); | |
| result = 31 * result + Short.hashCode(prefix); | |
| result = 31 * result + Short.hashCode(lineNum); | |
| this.hashCode = result; | |
| } | |
| return result; | |
| } | |
| } | |
| } |
2. 성능 때문에 핵심 필드를 해시코드 계산할 때 빼면 안 됨
해당 주의사항에 관해서는 앞서 hashCode 규약에서 언급한 바가 있습니다.
3. 해시코드 계산 규칙을 API에 노출하지 않는 것이 좋음
해시코드 계산 규칙을 API에 노출하면 클라이언트 코드가 이 규칙을 의존하게 되며, 이는 추후에 내부 구현 변경이 어려워질 수 있습니다.
하지만 앞서 살펴본 Arrays의 hashCode 메서드와 같이 자바 라이브러리의 많은 클래스에서 hashCode 메서드가 반환하는 정확한 값을 알려줍니다.
이 글을 읽은 몇 없는 독자만이라도 해당 주의사항을 고려하길 바랍니다.
참고
이펙티브 자바
이펙티브 자바 완벽 공략 1부 - 백기선 강사님
'JAVA > Effective Java' 카테고리의 다른 글
| [아이템 13] clone 재정의는 주의해서 진행하라 (0) | 2024.01.29 |
|---|---|
| [아이템 12] toString을 항상 재정의하라 (0) | 2024.01.27 |
| [아이템 10] equals는 일반 규약을 지켜 재정의하라 (0) | 2024.01.26 |
| [아이템 9] try-finally보다는 try-with-resources를 사용하라 (1) | 2024.01.24 |
| [아이템 8] finalizer와 cleaner 사용을 피하라 (1) | 2024.01.23 |