스트림의 패러다임
스트림이 제공하는 표현력, 속도, 병렬성을 얻으려면 API는 말할 것도 없고 해당 패러다임까지 함께 받아들여야 합니다.
- 스트림 패러다임의 핵심은 계산을 일련의 변환으로 재구성하는 것
- 각 변환의 단계는 오직 이전 단계의 결과만이 결과에 영향을 주는 순수한 함수여야 함
- 즉, 다른 가변 상태를 참조하지 않으면서 함수 스스로도 다른 상태를 변경하면 안 됨
1. 스트림 패러다임을 이해하지 못한 채 사용한 예
| public static Map<String, Long> streamSideEffect(final Stream<String> strings) { | |
| Map<String, Long> sideEffect = new HashMap<>(); | |
| strings.forEach(string -> { | |
| sideEffect.merge(string, 1L, Long::sum); | |
| }); | |
| return sideEffect; | |
| } |
위 코드는 텍스트 파일에서 단어별 수를 세어 빈도표로 만드는 일을 수행하지만 문제가 있는 코드입니다.
- 스트림 코드를 가장한 반복적 코드
- 위 스트림 파이프라인은 forEach 종단 연산에서 sideEffect map의 상태를 변경
- forEach를 사용하는 것은 스트림을 사용하는 것이 아닌 단순 반복문 사용에 불과
- 스트림 API의 이점을 살리지 못하여 같은 기능의 반복적 코드보다 간결하지 못해 가독성이 저하되고 유지보수에도 좋지 않음
1.1 forEach문을 권장하지 않는 이유
자바의 스트림에서 forEach문을 권장하지 않는 이유는 다음과 같습니다.
- 병렬 처리에 적합하지 않음
- side effect 발생 가능
- 종료 연산으로 인한 성능 손실
1.1.1 병렬 처리에 적합하지 않음
- forEach는 순차적으로 요소를 처리하기 때문에 병렬 처리에 적합하지 않음
- 대신 parallelStream() 메서드를 사용해 병렬 스트림을 생성하고 forEachOrdered()를 사용하여 안전하게 순서를 보장하는 것을 권장
| list.parallelStream().forEachOrdered(element -> { | |
| // 병렬 스트림에서 안전하게 요소 처리 | |
| }); |
1.1.2 side effect 발생 가능
- forEach를 사용할 때 부작용 문제가 발생할 수 있는데, 이는 주로 외부 객체나 상태를 수정하는 동작에 해당
- 함수형 프로그래밍에서는 부작용을 최소화하고 불변성을 유지하는 것이 중요하며, forEach를 사용할 때는 이를 고려해야 함
1.1.3 종료 연산으로 인한 성능 손실
- forEach는 스트림의 종료 연산 중 하나
- 이에 따라 스트림 파이프라인의 중간 연산에서 forEach를 사용하면 성능 손실 발생
- 따라서 최종적인 종료 연산에서만 forEach를 사용하는 것을 권장
1.2 forEach문을 권장하는 케이스
앞서 설명했다시피 forEach문을 대부분의 케이스에서 권장하지 않지만 간단한 작업을 수행하는 경우에는 forEach 코드가 반복문 코드보다 간결해집니다.
| // forEach | |
| list.stream().forEach(System.out::println); | |
| // 반복문 | |
| for (int num : list) { | |
| System.out.println(num); | |
| } |
책에서는 forEach 연산은 스트림 계산 결과를 보고할 때만 사용하고 계산하는 데는 쓰지 말라고 권장합니다.
2. 스트림 패러다임을 제대로 적용한 예
| Map<String, Long> freq; | |
| try (Stream<String> words = new Scanner(file).tokens()) { | |
| freq = words | |
| .collect(groupingBy(String::toLowerCase, counting())); | |
| } |
주어진 코드는 스트림 API를 적절히 활용하여 코드를 간결하고 명확하게 변경한 예시입니다.
해당 코드는 collector를 사용하는데, 스트림을 사용하려면 꼭 배워야 하는 개념입니다.
- java.util.stream.Collectors 클래스는 메서드를 39개 가지고 있지만 복잡한 세부 내용을 잘 모르더라도 API의 장점을 대부분 활용 가능
- collector가 생성하는 객체는 일반적으로 Collection
- 간단히 요약하자면 Collector 인터페이스는 축소 전략을 캡슐화한 블랙박스 객체
- 여기서 축소는 스트림의 원소들을 객체 하나에 취합한다는 뜻
3. Collectors 메서드
책에서 소개하는 Collectors 메서드들 중 핵심적인 메서드는 다음과 같습니다.
- toList()
- toSet()
- toMap()
- joining()
- groupingBy()
3.1 toList()
- 스트림의 요소를 List에 수집
3.2 toSet()
- 스트림의 요소를 Set에 수집
3.3 toMap()
- 스트림의 요소를 key-value 쌍으로 매핑하여 Map에 수집
3.4 joining()
- 스트림의 요소를 하나의 문자열로 결합
3.5 groupingBy
- 스트림의 요소를 지정된 기준으로 그룹화
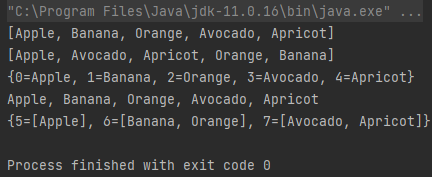
| public class Example { | |
| public static void main(String[] args) { | |
| String[] fruits = {"Apple", "Banana", "Orange", "Avocado", "Apricot"}; | |
| // toList | |
| List<String> list = Arrays.stream(fruits) | |
| .collect(Collectors.toList()); | |
| System.out.println(list); | |
| // toSet | |
| Set<String> set = Arrays.stream(fruits) | |
| .collect(Collectors.toSet()); | |
| System.out.println(set); | |
| // toMap | |
| Map<Integer, String> map = IntStream.range(0, fruits.length) | |
| .boxed() | |
| .collect(Collectors.toMap( | |
| // 키: 배열의 인덱스 | |
| index -> index, | |
| // 값: 배열의 값 (과일 이름) | |
| index -> fruits[index] | |
| )); | |
| System.out.println(map); | |
| // joining | |
| String s = Arrays.stream(fruits) | |
| .collect(Collectors.joining(", ")); | |
| System.out.println(s); | |
| // groupingBy | |
| Map<Integer, List<String>> groupedByLength = Arrays.stream(fruits) | |
| .collect(Collectors.groupingBy(String::length)); | |
| System.out.println(groupedByLength); | |
| } | |
| } |
정리
스트림 파이프라인 프로그래밍의 핵심은 부작용 없는 함수 객체에 있습니다.
종단 연산 중 forEach는 print와 같이 스트림이 수행한 계산 결과를 보고할 때만 사용하는 것을 권장합니다.
마지막으로 스트림을 올바로 사용하려면 Collectors를 잘 알아둬야 하며 핵심 메서드인 toList, toSet, toMap, groupingBy, joining은 반드시 숙지해야 합니다.
참고
이펙티브 자바
'JAVA > Effective Java' 카테고리의 다른 글
| [아이템 48] 스트림 병렬화는 주의해서 적용하라 (1) | 2024.03.06 |
|---|---|
| [아이템 47] 반환 타입으로는 스트림보다 컬렉션이 낫다 (0) | 2024.03.05 |
| [아이템 45] 스트림은 주의해서 사용하라 (0) | 2024.03.02 |
| [아이템 44] 표준 함수형 인터페이스를 사용하라 (0) | 2024.03.02 |
| [아이템 43] 람다보다는 메서드 참조를 사용하라 (0) | 2024.03.02 |