URI 쿼리
- URL에 검색할 칼럼과 검색어를 지정하면서 검색 수행
- 단순한 쿼리일 때 유리한 방식
- Request Body 검색에 비해 단순하고 사용하기 편하지만 쿼리가 길어질 경우 가독성 떨어짐
- "key = value" 형태로 전달하는 방식
- ex) GET [인덱스]/_search?q=year:2024
1. URI 쿼리 파라미터
| 파라미터 | default 값 | 설명 |
| q | 검색을 수행할 쿼리 문자열 조회 | |
| df | 기본값으로 검색할 필드 지정 | |
| analyzer | 쿼리 문자열에 대한 형태소 분석기 지정 | |
| analyzer_wildcard | false | 접두어/와일드카드 검색 활성화 여부 지정 |
| default_operator | OR | 두 개 이상의 검색어에 대해 검색 조건 연산자 설정 |
| _source | true | 본문의 필드를 전체 표시할지 여부 지정 |
| sort | 검색 결과의 정렬 기준 지정 | |
| from | 검색한 문서의 시작 문서 지점 | |
| size | 검색 결과로 반환할 개수 지정 | |
| stored_fields | 매핑에 store로 저장된 필드 검색 | |
| allow_partial_search_results | true | 검색 실패 시 부분적으로 검색한 결과를 반환할지 여부 결정 |
| batched_reduce_size | coordinating 노드에서 수집되는 결과 수를 줄여 메모리 용량을 줄일지 여부 확인 | |
| lenient | false | 데이터 유형의 불일치 여부를 무시할지 결정 |
| search_type | query_then_fetch | query_then_fetch: 관련성 점수를 집계하는데 유리 dfs_query_then_fetch: 정확도 측면에 유리 |
| timeout | 무제한 | 검색 작업을 완료하는데 허용되는 시간 |
| terminate_after | 무제한 | 샤드에 수집할 수 있는 문서수를 지정 |
| track_scores | false | 정렬이 활성화 된 경우 점수 추적 |
| track_total_hits | 10000 | 문서의 결과 수 표시 |
| explain | false | 결과의 디테일 정보 표시 |

부연 설명
- q=brand:아우디 AND year:2018: 검색에 대한 쿼리 조건
- from=0: 페이징 시작 값
- size=10: 페이징 사이즈
- sort=id:asc 정렬 필드
- _source_includes=id,manufacturer,model,color,fuel,type,transmission,model,year,area: 검색 결과 노출 필드
- analyzer=search_query_standard: 쿼리 조건의 분석기
- 조건이 복잡해짐에 따라 가독성 저하와 함께 휴먼 에러를 범하기 쉬워짐
QueryDSL
- DSL(Domain Specific Language)로 일치 검색, 범위 검색, 퍼지 검색 등을 수행할 수 있음
- HTTP 요청 시 본문의 JSON 문서를 사용하여 Elasticsearch에 검색 요청
- Filter Context, Query Context로 분류
- Filter Context란 검색 결과의 일치 여부와 관련된 질의, _score 값을 제공하지 않음
- Query Context란 query의 일치 여부에 대한 스코어를 측정하는 것을 기반으로 질의
1. Filter Context
- bool query 내부의 filter 타입에 적용
- score가 계산되지 않고 0.0으로 나오는 것이 특징
- 과거에 Elasticsearch 1.x 버전에서는 term query와 term filter처럼 쿼리 컨텍스트와 필터 컨텍스트가 명확히 구분되어 문법상 쿼리와 필터 컨텍스트를 구분할 수 있었지만
- bool query가 등장하면서 필터 컨텍스트는 모두 bool query에 포함됨
- 필터 컨텍스트를 단독으로 사용하기보다는 쿼리/필터 컨텍스트를 조합해 사용하는 방향으로 가는 추세

2. Query Context
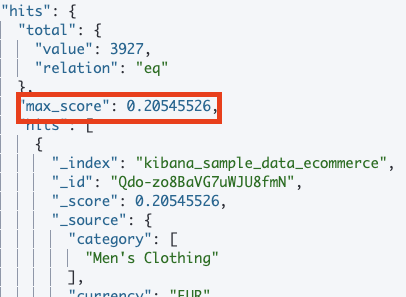
- 유사도 계산 알고리즘에 의해 가장 연관성 높은 도큐먼트를 찾는 API
- _score 값은 요청한 검색과 유사도를 나타내는 지표로, 일반적으로 값이 클수록 찾고자 하는 도큐먼트일 확률이 높음
3. QueryDSL 쿼리 구조
4. QueryDSL의 query 검색 결과 구조
유사도 스코어
- 쿼리 컨텍스트는 Elastic에서 지원하는 다양한 스코어 알고리즘을 사용할 수 있는데 기본적으로 BM25 알고리즘을 이용해 유사도 스코어를 계산
- Elasticsearch 5.x 이전 버전에서는 TF-IDF 알고리즘을 사용했으나 엘라스틱 5.x부터 BM25 알고리즘을 기본으로 사용
- BM25 알고리즘은 검색, 추천에 많이 사용되는 알고리즘으로 TF(Term Frequency), IDF(Inverse Document Frequency) 개념에 문서 길이를 고려한 알고리즘
- 검색어가 문서에서 얼마나 자주 나타나는지, 검색어가 문서 내에서 중요한 용어인지 등을 판단하는 근거를 제공
- 유사도 스코어는 질의문과 도큐먼트의 유사도를 표현하는 값으로, 스코어가 높을수록 찾고자 하는 도큐먼트에 가깝다는 사실을 의미
1. IDF(Inverse Document Frequency) 계산
- 문서 빈도(document frequency)는 특정 용어가 얼마나 자주 등장했는지를 의미하는 지표
- 일반적으로 자주 등장하는 용어는 중요하지 않을 확률이 높음
- '그리고', '그러나' 같이 문장을 이어주는 접속부사는 도큐먼트에 자주 나타나는데 이런 흔한 용어는 실제 큰 의미가 없음
- 따라서 도큐먼트 내에서 발생 빈도가 적을수록 가중치를 높게 주는데 이를 문서 빈도의 역수(IDF)라고 함
- IDF 계산식 = log(1 + (N - n + 0.5) / (n + 0.5))
- 이처럼 변수 N, n 값만 알면 IDF를 구할 수 있으며 변수에 대한 설명과 값도 결과에서 자세히 보여주고 있음

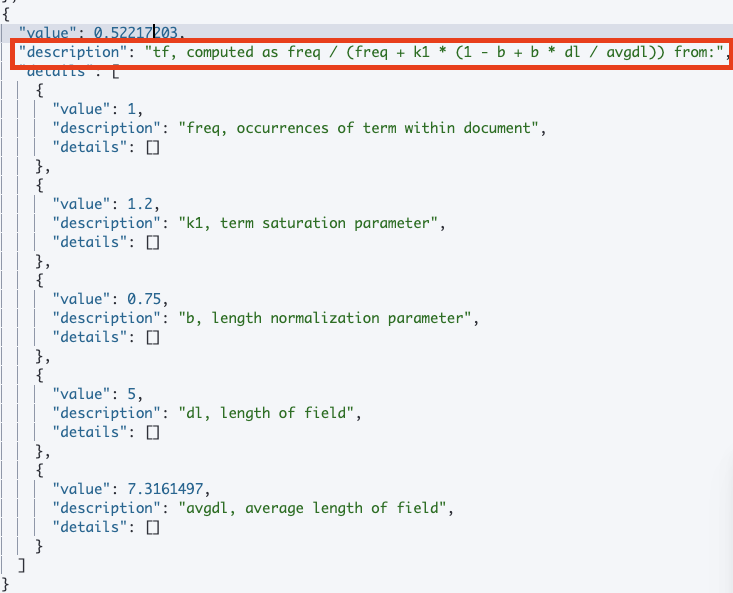
2. TF(Term Frequency) 계산
- 용어 빈도(Term Frequency)는 특정 용어가 하나의 도큐먼트에 얼마나 많이 등장했는지를 의미하는 지표
- 일반적으로 특정 용어가 도큐먼트에서 많이 반복되었다면 그 용어는 도큐먼트의 주제와 연관되어 있을 확률이 높음
- 따라서 하나의 도큐먼트에서 특정 용어가 많이 나오면 중요한 용어로 인식하고 가중치를 높임
- TF 계산식 = freq / (freq + k1 * (1 - b + b * dl / avgdl))
- 변수 freq, k1, b, dl, avgdl 값을 말면 TF 값을 구할 수 있음
- freq는 도큐먼트 내에서 용어가 나온 횟수
- k1과 b는 알고리즘을 정규화하기 위한 가중치로 Elasticsearch가 디폴트로 취하는 상수
- dl은 필드 길이이고, avgdl은 전체 도큐먼트에서 평균 필드 길이로 dl이 작고 avgdl이 클수록 TF 값이 크게 나옴
3. 최종 스코어 계산
- IDF와 TF 그리고 boost 변수를 곱한 값이 최종 스코어
- boost는 Elasticsearch가 지정한 고정값
쿼리
- Elasticsearch는 검색을 위해 쿼리를 지원하는데 크게 리프 쿼리(leaf query)와 복합 쿼리(computed query)로 나눌 수 있음
- 리프 쿼리는 특정 필드에서 용어를 찾는 쿼리로 매치(match), 용어(term), 범위(range) 쿼리 등이 있음
- 복합 쿼리는 쿼리를 조합해 사용되는 쿼리로 대표적으로 bool 쿼리 등이 있음
1. 전문 쿼리와 용어 수준 쿼리
- 전문 쿼리는 전문 검색을 하기 위해 사용되며, 전문 검색을 할 필드는 인덱스 매핑 시 text 타입으로 매핑해야 함
- 용어 수준 쿼리는 정확히 일치하는 용어를 찾기 위해 사용되며 인덱스 매핑 시 필드를 keyword 타입으로 매핑해야 함
- 강제는 아니지만 정확한 결과를 얻기 위한 권장 사항
1.1 전문 쿼리 동작 방식
- text 타입으로 매핑된 문자열은 분석기에 의해 토큰으로 분리됨
- ex) "I Love Elastic Stack" -> [i, love, elastic, stack]으로 토큰화
- 전문 쿼리를 사용하게 되면 검색어인 'elastic world'도 분석기에 의해 토큰으로 분리되어 [elastic, world]로 토큰화
- 그리고 토큰화된 검색어 [elastic, world]와 토큰화된 도큐먼트 용어들 [i, love, elastic, stack]이 매칭되어 스코어를 계산하고 검색할 때 사용
- 전문 쿼리의 종류로는 매치 쿼리(match query), 매치 프레이즈 쿼리(match phrase query), 멀티 매치 쿼리(multi match query), 쿼리 스트링 쿼리(query string query) 등이 있음
1.2 용어 수준 쿼리 동작 방식
- keyword 타입은 인덱싱 고자ㅓㅇ에서 분석기를 사용하지 않음
- 검색은 용어(term) 쿼리를 사용하는데 검색어는 분석기를 거치지 않고 그대로 사용
- 이렇게 분석되지 않은 검색어와 분석되지 않은 도큐먼트 용어를 매칭하는데, 이 경우 대소문자 차이로 매칭에 실패하기도 함
- 일반적으로 숫자, 날짜, 범주형 데이터를 정확하게 검색할 때 사용되며 관계형 데이터베이스의 WHERE 절고 비슷한 역할
- 용어 수준 쿼리에는 용어 쿼리(term query), 용어들 쿼리(terms query), 퍼지 쿼리(fuzzy query) 등이 있음
2. 매치 쿼리(match query)
- 전문 쿼리의 가장 기본이 되는 쿼리로 전체 텍스트 중에서 특정 용어나 용어들을 검색할 때 사용
- 매치 쿼리를 사용하기 위해서는 검색하고 싶은 필드를 알아야 함
부연 설명
- 전문 쿼리의 경우 검색어도 토큰화되기 때문에 검색어 'Mary Bailey'는 [mary, bailey]로 토큰화
- 따라서 customer_full_name 필드에 'mary' 혹은 'bailey'가 포함된 모든 도큐먼트를 검색할 수 있음
- operator는 default 값이 OR이므로 mary bailey가 모두 포함되어야 하는 경우 명시적으로 "operator": "AND"로 선언해야 함
3. 매치 프레이즈 쿼리(match phrase query)
- 구(phrase)를 검색할 때 사용하며 구는 동사가 아닌 두 개 이상의 단어가 연결되어 만들어지는 단어
- ex) '빨간색 바지', '65인치 텔레비전' 같이 여러 단어가 모여서 뜻을 이루는 단어
- 이때 순서가 중요함 (빨간색 바지를 찾는 것이지 바지 빨간색을 찾는 것이 아니기 때문)
부연 설명
- 앞선 매치 쿼리처럼 검색어 'Mary Bailey'는 [mary, bailey]로 토큰화
- 하지만 match_phrase는 match와 달리 순서도 중요시 여기므로 'mary bailey'가 포함된 모든 도큐먼트를 검색
- 반면, match 쿼리 같은 경우 'bailey mary'가 포함된 도큐먼트도 조회됨
4. 용어 쿼리(term query)
- 정확한 검색 혹은 필터링에 자주 수행 됨
- score 값을 계산하지 않기 때문에 필터 되는 속도가 빠름
- SQL에서 "="과 같은 역할
- 용어 수준 쿼리에 속하기 때문에 검색어인 'mary bailey'가 분석기에 의해 토큰화되지 않음
- 즉 'mary bailey'라고 정확한 용어가 있는 경우에만 매칭이 됨
- 분석기를 거치지 않았기 때문에 대소문자도 정확히 맞아야 함
부연 설명
- 앞선 쿼리들과 달리 keyword 타입으로 조회하는 것을 확인 가능
- 이는 text 타입 같은 경우 분석기를 거쳐 [mary, bailey]로 토큰화되기 때문
- term 쿼리는 분석기를 거치지 않기 때문에 "Mary Bailey"라는 검색어를 그대로 조회하기 때문에 text 타입인 customer_full_name 필드를 대상으로 검색하면 아무 결과도 조회 안됨
- 따라서 똑같이 분석기를 거치지 않은 keyword 타입인 customer_full_name.keyword 필드를 대상으로 검색해야 원하는 결과를 얻을 수 있음
5. 용어들 쿼리(terms query)
- 여러 개의 단어 중 하나의 단어만 존재해도 검색 결과를 노출할 수 있는 쿼리
- SQL의 in query에 해당
- 용어 수준 쿼리의 일종이며 여러 용어들을 검색해 줌
- keyword 타입으로 매핑된 필드에서 사용해야 하며, 분석기를 거치지 않았기 때문에 대소문자도 신경 써야 함
- terms의 개수는 최대 65,536개이며 index.max_terms_count의 옵션을 통해 수정 가능

6. 멀티 매치 쿼리(multi match query)
- 검색하고자 하는 용어나 구절이 정확히 어떤 필드에 있는지 모르는 경우가 있음
- 특히 전문 검색 서비스의 경우라면 더욱 자주 직면하는 문제
- ex) '트럼프'를 검색할 때 '트럼프'가 어떤 필드에 저장되어 있는지 정확히 알 수 없음
- 블로그의 제목, 뉴스의 기사 등 다양한 필드에 저장될 수 있음
- 이럴 경우 하나의 필드가 아닌 여러 개의 필드에서 검색을 진행해야 하며 여러 개의 필드에서 검색하기 위한 멀티 매치 쿼리는 전문 쿼리의 일종으로, text 타입으로 매핑된 필드에서 사용하는 것이 좋음
6.1 와일드카드를 이용한 멀티 필드에 쿼리 요청
6.2 부스팅 기법
- 여러 개의 필드 중 특정 필드에 가중치를 두는 방법
- 여러 개의 필드 중 중요한 필드를 알고 있다면 해당 필드에 가중치 부여 가능
- ex) '엘라스틱'을 블로그에서 검색한다고 가정할 때 '엘라스틱'이라는 용어가 본문에 있는 것과 제목에 있는 것은 무게가 다름
- 일반적으로 제목에 '엘라스틱'이라는 용어가 있는 도큐먼트가 더 중요할 가능성이 높으므로 이럴 경우 제목 필드에 가중치를 부여

7. 범위 쿼리
- 특정 날짜나 숫자의 범위를 지정해 범위 안에 포함된 데이터들을 검색할 때 사용
- 날짜/숫자/IP 타입의 데이터는 범위 쿼리가 가능하지만 문자형, keyword 타입의 데이터에는 범위 쿼리를 사용할 수 없음
7.1 검색 범위를 지정하는 파라미터
| 파라미터 | 설명 |
| gte | 이상 ex) gte: 10 -> 10과 같거나 10보다 큰 값 ex) gte: 2024-06-07 -> 2024년 6월 7일이거나 그 이후의 날짜 |
| gt | 초과 ex) gte: 10 -> 10보다 큰 값 ex) gte: 2024-06-07 -> 2024년 6월 7일 이후의 날짜 |
| lte | 이하 ex) lte: 10 -> 10과 같거나 10보다 작은 값 ex) lte: 2024-06-07 -> 2024년 6월 7일이거나 그 이전의 날짜 |
| lt | 미만 ex) lt: 10 -> 10보다 작은 값 ex) lt: 2024-06-07 -> 2024년 6월 7일 이전의 날짜 |
7.2 날짜/시간 데이터 타입
- 날짜/시간 검색은 현재 시간을 기준으로 하는 경우가 많음
- 일주일 전 도큐먼트들이나 하루 전 도큐먼트들을 골라내서 쿼리를 진행하고 싶을 경우 더 편리하게 검색할 수 있는 표현식 존재
부연 설명
- timestamp 필드에서 현재 시간 기준으로 한 달 전까지의 모든 데이터를 가져오는데 현재 시각을 기준으로 날짜/시간 범위를 직관적으로 이해할 수 있음
- 또한 오늘 날짜/시간을 직접 입력하지 않기 때문에 시스템 운영 시 유연하게 대처 가능
| 표현식 | 설명 |
| now | 현재 시각 |
| now+1d | 현재 시각 + 1일 |
| now+1h+30m+10s | 현재 시각 + 1시간 30분 10초 |
| 2024-05-07||+1M | 2024-05-07 + 1달 |
7.3 범위 데이터 타입
- 이전 게시글에서 언급했듯이 범위 데이터 타입은 integer_range, float_range, long_range, double_range, date_range, ip_range 총 여섯 가지 타입을 지원
- 범위 쿼리는 relation이라는 파라미터를 이용해 어떤 범위를 포함할지 결정 가능
| relation 값 | 설명 |
| intersects (default 값) | 쿼리 범위 값이 도큐먼트의 범위 데이터를 일부라도 포함하기만 하면 됨 |
| contains | 도큐먼트의 범위 데이터가 쿼리 범위 값을 모두 포함해야 함 |
| within | 도큐먼트의 범위 데이터가 쿼리 범위 값 내 전부 속해야 함 |

8. 논리 쿼리
- 복합 쿼리(compound query)로 앞서 언급한 쿼리들을 조합할 수 있음
- ex) '2024년 6월 7일'에 생성된 로그 중에서 '상태가 불량'인 것들을 검색하거나, '서울 지역'에서 발생한 데이터이면서 '제주도 지역'에서 발생하지 않은 데이터를 검색해야 한다고 가정
- 위와 같은 경우 앞에서 배웠던 매치 쿼리나 용어 쿼리 단독으로는 검색할 수 없고 쿼리들을 조합해야 함
* 논리 쿼리 타입은 위와 같이 네 가지가 있으며 네 개 타입 아래에서 full text query나 term level query, range query, geo query 등을 사용할 수 있음
| 타입 | 설명 |
| must | 쿼리를 실행하여 참인 도큐먼트를 조회 복수의 쿼리를 실행하면 AND 연산 |
| must_not | 쿼리를 실행하여 거짓인 도큐먼트를 조회 다른 타입과 같이 사용할 경우 도큐먼트에서 제외 |
| should | 단독으로 사용 시 쿼리를 실행하여 참인 도큐먼트를 찾음 복수의 쿼리를 실행하면 OR 연산 다른 타입과 같이 사용할 경우 스코어에만 활용 |
| filter | 쿼리를 실행하여 true/false 형식의 필터 컨텍스트 수행 |
8.1 must 타입
- 쿼리를 실행하고 참인 도큐먼트를 찾음
부연 설명
- AND 조건에 의해 day_of_week가 'Sunday'이면서 customer_full_name에 'mary'가 들어간 도큐먼트들만 검색
- 이처럼 손쉽게 용어 쿼리와 전문 쿼리를 AND 연산으로 조합할 수 있음
8.2 must_not 타입
- 도큐먼트에서 제외할 쿼리를 실행
- 특정 조건의 쿼리를 제외할 수 있음
부연 설명
- customer_first_name에 'mary'가 들어간 도큐먼트를 모두 찾고 이 중에서 customer_last_name에 'bailey'가 들어간 도큐먼트만 제외
8.3 should 타입
- should 타입에 하나의 쿼리를 사용하면 must 타입과 같은 결과를 얻음
- should 타입에서 복수 개의 쿼리를 사용하면 OR 조건이 되면서 더 많은 도큐먼트가 검색됨
- must 타입에서 복수 개의 쿼리를 사용하면 AND 조건
- should 타입이 다른 타입과 함께 사용되는 경우 should 타입에 적은 쿼리는 검색 결과에 영향을 끼치지 않고 스코어에만 영향을 줌
8.3.1 must 타입만 단독으로 사용하는 쿼리

8.3.2 must와 should 타입을 같이 사용하는 쿼리

부연 설명
- 조회된 도큐먼트는 마찬가지로 154건
- 가장 스코어가 높은 도큐먼트가 바뀐 것을 확인할 수 있음
- 이처럼 should를 사용해 도큐먼트의 검색 순위를 최적화할 수 있음
8.4 filter 타입
- must와 같은 동작을 하지만 필터 컨텍스트로 동작하기 때문에 유사도 스코어에 영향을 미치지 않음
- true/false 두 가지 결과만 제공할 뿐 유사도를 고려하지 않음

9. 패턴 검색
- 검색어의 대략적인 키워드나 몇 개의 알파벳만 알고 있다면 패턴을 이용해 검색 가능
- 패턴을 이용한 검색은 와일드카드를 사용하는 와일드 카드 쿼리와 정규 표현식을 사용하는 정규식 쿼리 두 가지 방법 존재
- 두 쿼리 모두 용어 수준 쿼리에 해당하므로 분석기에 의해 분리된 용어를 찾기 위한 쿼리
- SQL의 LIKE 검색처럼 원문에서 특정 문자열을 검색하는 용도로는 적합하지 않음
- 또한 많은 리소스를 사용하기 때문에 자주 사용하는 것을 권장하지 않음
9.1 와일드카드 쿼리
- *와 ?라는 두 가지 기호를 사용할 수 있음
- *는 공백까지 포함하여 글자 수에 상관없이 모든 문자를 매칭할 수 있고
- ?는 오직 한 문자만 매칭할 수 있음
- 검색하려는 용어의 맨 앞에 *와 ?를 사용하면 속도가 매우 느려지기 때문에 검색어 앞에는 사용하지 않는 것을 권장

9.2 정규식 쿼리
- 와일드카드에서 사용한 *, ?기호가 정규식에서는 쓰임이 다름
- 점(.)은 하나의 문자를 의미하고 어떤 문자가 와도 상관없이 매칭되었다고 판단
- + 기호는 + 기호 앞 문자와 같은 문자가 한 번 이상 반복되면 매칭되었다고 판단
- * 기호는 * 기호 앞 문자와 같은 문자가 0번, 혹은 여러 번 반복되면 매칭되었다고 판단
- ? 기호는 ? 기호 앞 문자와 같은 문자가 0번, 혹은 한 번 나타나면 매칭되었다고 판단
- () 기호는 문자를 그룹핑하여 반복되는 문자들을 매칭시키고 독자적으로 사용하기보다는 +, ?, * 같은 기호들과 혼합하여 사용됨
- [] 기호는 문자를 클래스화하여 특정 범위의 문자들을 매칭
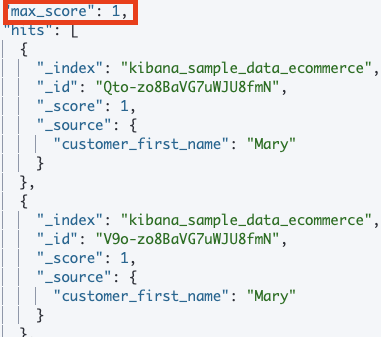
- 정규식으로 일치된 문서는 스코어가 계산되지 않기 때문에 1.0으로 표기
9.3 prefix 쿼리
- 시작 부분을 알고 있거나 검색하고 싶을 때 사용
- 트리 구조로 구성된 데이터 사용에 용이
- 카테고리의 코드로 하위 카테고리 검색 시 사용
- 시작하는 특정 문자열로 검색 시 사용

10. Nested Query
- 중첩된 객체(Array)를 포함하는 문서를 쿼리 하기 위한 용도
- 일반적으로 JSON 객체 배열로 문서 내 포함되어 있으며 독립적으로 색인됨
- Elasticsearch는 기본적으로 문서 필드를 평탄화(flat) 작업을 진행
- 따라서 중첩된 객체의 문서 쿼리 시 객체 간의 모든 필드가 동일레벨에 있는 것처럼 취급됨
- 평탄화 작업을 진행하므로 검색 시 모든 필드가 일치해야 결과 노출
- Nested Query를 많이 사용하게 되면 성능 저하 유발할 수 있음
- 중첩된 객체의 수가 많을수록 쿼리의 실행 시간이 길어짐
- Nested Query 사용 시 path를 선언 후 사용해야 정상 동작
- Nested와 Object 차이는 이전 게시글 참고

11. Function Score Query
- 스코어링 알고리즘을 광범위하게 정의
- function_score 쿼리를 통해 반환된 문서의 점수를 제어
- decay 함수 등을 통해 시간의 움직임에 따른 점수 계산 가능
- 무작위 문서 리스팅 가능
- 필드 기반의 스코어 점수 반영 가능
| 파라미터 | 설명 |
| query/filter | 문서를 찾는 쿼리 작성 |
| boost | 쿼리에 대한 부스팅 값 명시 |
| functions | 쿼리를 사용하여 score 값을 지정 |
| max_boost | boost의 최대 점수 |
| boost_mode | functions의 스코어와 query 스코어에 대한 계산 방법 - multiply: query 부분과 functions의 값을 곱함 - replace: function의 값만 사용 - sum: query와 functions의 합 - avg: query와 functions의 평균 값 - max: query와 functions 중 더 큰 값 - min: query와 functions 중 더 작은 값 |
| score_mode | functions score의 결합 방법 - multiply: 점수의 곱 - sum: 점수의 합 - avg: 평균 점수 - first: 첫 번째 functions에 적용된 값 - max: 최대 점수 - min: 최소 점수 |
| random_score | 문서의 점수를 무작위로 선정 |
| script_score | 스크립트를 통해 점수를 정의 |
| decay function | 날짜의 값을 거리에 따라 감쇄시키는 방법 정의 (linear/gauss/exp 사용) |
11.1 Function 스코어 예제
- SUV 차량 중 silver 색상과 현대, 기아인 차량이 먼저 나오게 하려면?

조회할 필드 선택
- 문서에 저장된 필드 값 중 원하는 값만 선택하여 응답값으로 반환
- 특히 대용량 검색 시 리소스 아끼는 방법
- 문서의 크기가 크거나 필드가 많을 경우 필요한 필드만 노출
- _source 파라미터를 통해 노출할 필드 값을 지정
- 매핑에서 store 옵션을 false로 할 경우 해당 필드는 노출되지 않음
- 필드명 prefix, postfix로 "*", "?"를 통해 특정 필드의 항목 전체를 노출할 수 있음 (와일드카드 쿼리)
"_source": ["c*", "*i"],
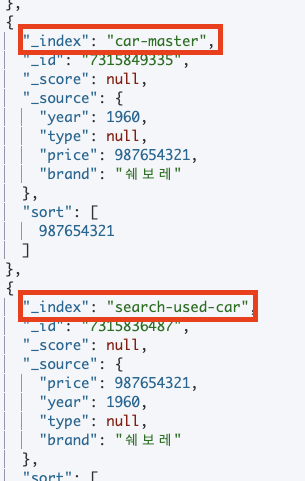
다중 인덱스 검색(multi-tenancy)
- 멀티태넌시(multi-tenancy)라 하며, 여러 개의 인덱스 데이터를 한 번에 조회할 수 있음
- 다른 스키마 구조를 가지고 있어도 검색이 가능하지만, 유사한 매핑 구조를 가지고 있는 검색에서 많이 사용
- 같은 특징을 가진 유형 혹은 통합 검색과 같은 유형의 인덱스에서 많이 사용
결과 페이징 처리
- 검색 결과의 다음 페이지를 보여주기 위해 from, size로 설정
- 페이지가 뒤로 갈수록 속도는 느려짐
- 페이지를 가져올 때 전체 데이터에서 from부터 끊어서 size만큼 결과 반환
- 1페이지에서는 from=0, size=5
- 2페이지에서는 from=5, size=5로 size를 지속적으로 from에 더함
- 페이징 공식 from = (페이지 번호 - 1) * size
정렬 처리
- 기본적으로 문서의 스코어 값으로 정렬
- 필드명, 가격, 날짜 등을 기준으로 정렬할 수 있음
- 오름차순 정렬, 내림차순 정렬로 문서의 순서를 변경할 수 있음

스크롤 API
- DB의 커서와 비슷하게 동작
- 현재 커서 기반으로 다음의 문서를 노출
- 실시간 검색을 위한 API가 아니며, 대량의 문서를 검색할 때 반복해서 가져오는 경우에 사용
- 대용량 데이터를 일관된 스냅샷으로 처리하는데 초점
- 페이징에는 적합하지 않고 페이징 시에는 search_after 사용하는 것을 권장
- 스크롤 API를 사용 후 미종료할 경우 리소스를 계속 점유하여 성능 저하 유발
1. 스크롤 API 사용 방법
- 처음 검색 시 scroll id를 발급받음
- N 번째 검색에서 이전에 발급받은 scroll id를 이용해서 쿼리
예제: 10분간 유효한 스크롤 id 발급

예제: _search/scroll을 사용하여 scroll_id로 다음 문서 조회
- 쿼리 등을 사용하지 않고 페이징 계산을 하지 않아도 됨
예제: 리소스 낭비를 방지하기 위해 사용한 scroll_id 삭제
search_after API
- 대규모 데이터 셋을 효율적으로 페이징 처리할 수 있는 기능
- 스크롤 API와 달리, search_after는 시간이 지남에 따라 데이터에 대한 실시간으로 다음 페이지 제공 가능
- 로그 데이터나 시계열 데이터와 같이 대규모 데이터 셋을 처리할 때 유용
- 데이터가 지속적으로 업데이트되는 환경에서 최신 데이터를 효과적으로 쿼리 할 수 있음
- 실시간 데이터와 동적인 쿼리에 적합
- 정렬된 결과에 대해 유연하고 효율적인 접근 제공
1. 예제
예제: 최초 검색 결과에서 search_after api를 위한 키 조회
- 조회된 마지막 문서의 sort 키에 대한 value

예제: search_after 적용한 쿼리
2. search_after PIT 적용
- 검색이 이루어진 사이에 문서가 refresh가 된다면 페이징 된 결과가 정확히 맞지 않음
- Point in Time(PIT)를 사용하면 현재 검색 상태에 대한 포인트 저장 후 보정
- POST <인덱스>/_pit?keep_alive=1m
- 해당 API를 통해 받아온 id를 pit.id 파라미터에 넘겨 포인트 저장 후 검색
- 검색 작업이 완료되면 PIT를 종료하고 관련 리소스 해제
- DELETE _pit
예제: PIT id 발급

예제: PIT 적용 후 조회
예제: PIT 제거
Elasticsearch SQL로 문서 조회하기
- Elasticsearch 문서와 인덱스에 대한 SQL 기능 확장
- 별도 라이브러리 추가 없이 실행 가능
- 친숙한 SQL 구문을 제공해 Elasticsearch 데이터를 쿼리 할 수 있음
- ANSI SQL과 차이점 존재
- Elasticsearch SQL은 SQL 구문은 준수하지만 중첩 및 반정형 데이터에 대한 Elasticsearch만의 확장 기능을 포함함
- 기존 데이터베이스 테이블, 행, 열을 사용하지만 Elasticsearch는 인덱스, 유형, 문서를 사용
- 분산된 문서의 저장 공간 특성으로 인해 JOIN 지원 X
1. Elasticsearch SQL 작동 방식
- SQL 쿼리를 Elasticsearch native query로 변환
- Elasticsearch 인덱스에 대한 쿼리 실행
- format을 통해 여러 가지 형태로 데이터 출력 가능 (csv, json 등)
* 주의할 점: query 구문에 "-" 하이픈은 지원하지 않기 때문에 인덱스명에 "-" 포함 시 앞뒤로 따옴표 필요

2. Describe 구문
- Elasticsearch 인덱스 구조 제공 (SQL의 테이블과 유사)
- 출력 시 인덱스의 칼럼(필드) 및 데이터 타입 목록을 보여줌

3. SELECT 구문
- ANSI 쿼리에서 작성하듯이 SELECT 구문을 작성하면 됨
- 단, JOIN은 지원 X
- "-"에 대한 escape 문자를 넣기 귀찮아서 car-master 인덱스에 대한 alias를 car_master로 지정

4. SQL 쿼리를 QueryDSL로 변환
- SQL 쿼리를 QueryDSL로 _sql/translate API를 통해 변환할 수 있음

5. Elasticsearch SQL과 관련된 문서
- Elasticsearch SQL과 관련한 더 자세한 내용은 https://www.elastic.co/kr/blog/an-introduction-to-elasticsearch-sql-with-practical-examples-part-1 참고
검색 템플릿
- Elasticsearch에서 반복적으로 사용되는 검색 쿼리를 저장하고 재사용하기 위한 기능
- Mustache 템플릿 언어를 사용하여 쿼리의 동적 부분을 변수로 치환함으로써 구현
- 복잡한 쿼리를 간편하게 재사용할 수 있어 검색 작업의 효율성을 높일 수 있음
- _script API를 통해 Elasticsearch에 저장되며 고유한 ID로 식별됨
- 검색 시 템플릿 ID와 함께 필요한 파라미터를 전달하면, 템플릿을 기반으로 실제 검색 쿼리 생성
- 쿼리 변경 시 템플릿만 업데이트하면 되므로 코드의 유지보수 및 재배포가 필요하지 않음
1. 검색 템플릿 생성 예제
- mustache 스크립트를 사용하여 템플릿 지정
- _scripts API의 옆에 템플릿 ID 입력
- POST _scripts/[템플릿명]
2. 검색 템플릿 사용 예제
- GET _search/template API를 사용하여 파라미터 정의

참고
- 패스트 캠퍼스 - 고성능 검색 엔진 구축으로 한 번에 끝내는 Elasticsearch
- 엘라스틱 개발부터 운영까지 (김준영, 정상운 저)
'Elastic Search' 카테고리의 다른 글
| [Elasticsearch] 자동완성 (0) | 2024.06.12 |
|---|---|
| [Elasticsearch] 집계 (3) | 2024.06.09 |
| [Elasticsearch] 분석기(analyzer) (3) | 2024.06.07 |
| [Elasticsearch] 매핑과 인덱스 alias, template (1) | 2024.06.06 |
| [Elasticsearch] 데이터 모델링 기초 (0) | 2024.06.06 |