Scheduler
- OS에서 사용되는 Scheduler와 의미가 비슷
- OS 레벨에서의 Scheduler는 실행되는 프로그램인 프로세스를 선택하고 실행하는 등 프로세스의 라이프 사이클을 관리해 주는 관리자 역할
- Reactor의 Scheduler는 비동기 프로그래밍을 위해 사용되는 쓰레드를 관리해 주는 역할
- Scheduler를 사용하여 어떤 쓰레드에서 무엇을 처리할지 제어
- Reactor Scheduler를 사용하면 코드 자체가 매우 간결해지고 Scheduler가 쓰레드의 제어를 대신해 주기 때문에 멀티 쓰레드 환경에서의 예상치 못한 오류가 발생할 확률을 최소화시킬 수 있음
Scheduler를 위한 전용 Operator
- Reactor에서 Scheduler는 Scheduler 전용 Operator를 통해 사용할 수 있음
- subscribeOn() Operator와 publishOn() Operator가 대표적인 예시이며 해당 Operator의 파라미터로 적절한 Scheduler를 전달하면 해당 Scheduler의 특성에 맞는 쓰레드가 Reactor Sequence에 할당됨
- parallel()이라는 특별한 Operator도 있음
1. subscribeOn() Operator
- 구독이 발생한 직후 실행될 쓰레드를 지정하는 Operator
- 구독이 발생하면 원본 Publisher가 데이터를 최초로 내보내게 되는데 subscribeOn() Operator는 구독 시점 직후에 실행되기 때문에 원본 Publisher의 동작을 수행하기 위한 쓰레드
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static void main(String[] args) throws InterruptedException { | |
| Flux.fromArray(new Integer[] {1, 3, 5, 7}) | |
| .subscribeOn(Schedulers.boundedElastic()) | |
| .doOnNext(data -> log.info("# doOnNext: {}", data)) | |
| .doOnSubscribe(subscription -> log.info("# doOnSubscribe")) | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| Thread.sleep(500L); | |
| } |

부연 설명
- subscribeOn() Operator를 추가했기 때문에 구독이 발생한 직후 원본 Publisher의 동작을 처리하기 위한 쓰레드를 할당
- doOnNext() Operator를 사용해 원본 Flux에서 emit 되는 데이터를 로그로 출력
- doOnSubscribe() Operator를 사용해 구독이 발생한 시점에 추가적인 어떤 처리가 필요할 경우 해당 처리 동작을 추가할 수 있으며 여기서는 구독이 발생한 시점에 실행되는 쓰레드가 무엇인지 확인
2. publishOn() Operator
- Downstream으로 Signal을 전송할 때 실행되는 쓰레드를 제어하는 역할을 하는 Operator
- publishOn()을 기준으로 아래쪽인 Downstream의 실행 쓰레드를 변경
- subscribeOn()과 마찬가지로 파라미터로 Scheduler를 지정함으로써 해당 Scheduler의 특성을 가진 쓰레드로 변경 가능
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static void main(String[] args) throws InterruptedException { | |
| Flux.fromArray(new Integer[] {1, 3, 5, 7}) | |
| .doOnNext(data -> log.info("# doOnNext: {}", data)) | |
| .doOnSubscribe(subscription -> log.info("# doOnSubscribe")) | |
| .publishOn(Schedulers.parallel()) | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| Thread.sleep(500L); | |
| } |
부연 설명
- publishOn() Operator를 사용했기 때문에 Downstream으로 데이터를 내보내는 쓰레드를 변경하며 나머지 코드는 subscribeOn() Operator 예제 코드와 유사함
- 최초 실행 쓰레드는 main 쓰레드이기 때문에 doOnSubscribe()는 main 쓰레드에서 실행되며 doOnNext()의 경우 subscribeOn() Operator를 사용하지 않았기 때문에 여전히 main 쓰레드에서 실행
- publishOn() Operator를 추가했기 때문에 publishOn()을 기준으로 Downstream의 실행 쓰레드가 변경되어 parallel-1 쓰레드에서 실행
3. parallel() Operator
- subscribeOn() Operator와 publishOn() Operator의 경우 동시성을 가지는 논리적인 쓰레드
- 동시성이란 무수히 많은 논리적이니 쓰레드가 N개의 물리적인 쓰레드를 아주 빠른 속도로 번갈아 가며 사용하면서 마치 동시에 실행되는 것처럼 보이는 효과
- parallel() Operator는 병렬성을 가지는 물리적인 쓰레드
- 병렬성은 물리적인 쓰레드가 실제로 동시에 실행되기 때문에 여러 작업을 동시에 처리함을 의미
- 라운드 로빈 방식으로 CPU 코어 개수만큼의 쓰레드를 병렬로 실행
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static void main(String[] args) throws InterruptedException { | |
| Flux.fromArray(new Integer[]{1, 3, 5, 7, 9, 11, 13, 15, 17, 19}) | |
| .parallel(4) | |
| .runOn(Schedulers.parallel()) | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| Thread.sleep(100L); | |
| } |
부연 설명
- 병렬 작업을 처리하기 위해 4개의 쓰레드를 지정
- 코드 실행 결과를 보면 4개의 쓰레드가 병렬로 실행되는 것을 확인 가능
publishOn()과 subscribeOn()의 동작 이해
1. 두 개의 publishOn() Operator를 사용할 경우, Operator 체인에서 실행되는 스레드의 동작 과정
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static void main(String[] args) throws InterruptedException { | |
| Flux | |
| .fromArray(new Integer[] {1, 3, 5, 7}) | |
| .doOnNext(data -> log.info("# doOnNext fromArray: {}", data)) | |
| .publishOn(Schedulers.parallel()) | |
| .filter(data -> data > 3) | |
| .doOnNext(data -> log.info("# doOnNext filter: {}", data)) | |
| .publishOn(Schedulers.parallel()) | |
| .map(data -> data * 10) | |
| .doOnNext(data -> log.info("# doOnNext map: {}", data)) | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| Thread.sleep(500L); | |
| } |


부연 설명
- 첫 번째 publishOn()을 추가함으로써 filter() Operator는 parallel-2 쓰레드에서 실행
- 두 번째 publishOn()을 추가함으로써 map Operator부터는 parallel-1 쓰레드에서 실행
- 이처럼 Operator 체인상에서 한 개 이상의 publishOn() Operator를 사용하여 실행 쓰레드를 목적에 맞게 적절하게 분리할 수 있음
2. subscribeOn()과 publishOn()을 함께 사용할 경우, Operator 체인에서 실행되는 쓰레드의 동작 과정
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static void main(String[] args) throws InterruptedException { | |
| Flux | |
| .fromArray(new Integer[] {1, 3, 5, 7}) | |
| .subscribeOn(Schedulers.boundedElastic()) | |
| .doOnNext(data -> log.info("# doOnNext fromArray: {}", data)) | |
| .filter(data -> data > 3) | |
| .doOnNext(data -> log.info("# doOnNext filter: {}", data)) | |
| .publishOn(Schedulers.parallel()) | |
| .map(data -> data * 10) | |
| .doOnNext(data -> log.info("# doOnNext map: {}", data)) | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| Thread.sleep(500L); | |
| } |
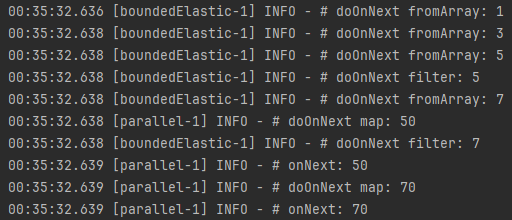
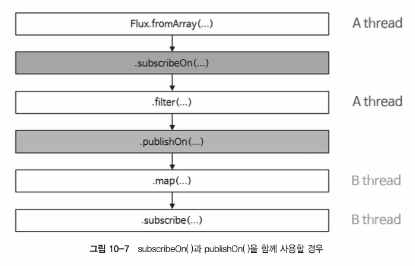
부연 설명
- publishOn() 이전까지의 Operator 체인은 subscribeOn()에서 지정한 boundedElastic-1 쓰레드에서 실행
- publishOn() 이후의 Operator 체인은 parallel-1 쓰레드에서 실행
- 이처럼 subscribe() Operator와 publishOn() Operator를 함께 사용하면 원본 Publisher에서 데이터를 내보내는 쓰레드와 emit 된 데이터를 가공 처리하는 쓰레드를 적절하게 분리할 수 있음
Scheduler 종류
1. Scheduler.immediate()
- 별도의 쓰레드를 추가적으로 생성하지 않고 현재 쓰레드에서 작업을 처리하고자 할 때 사용
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static void main(String[] args) throws InterruptedException { | |
| Flux | |
| .fromArray(new Integer[] {1, 3, 5, 7}) | |
| .publishOn(Schedulers.parallel()) | |
| .filter(data -> data > 3) | |
| .doOnNext(data -> log.info("# doOnNext filter: {}", data)) | |
| .publishOn(Schedulers.immediate()) | |
| .map(data -> data * 10) | |
| .doOnNext(data -> log.info("# doOnNext map: {}", data)) | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| Thread.sleep(200L); | |
| } |

부연 설명
- Schedulers.parallel()을 사용했기 때문에 parallel-1 쓰레드가 현재 쓰레드가 됨
- Schedulers.immediate()는 추가 쓰레드를 생성하지 않으므로 map() Operator에서의 처리 작업과 Subscriber에서의 처리 작업이 별도의 추가 쓰레드가 아닌 parallel-1이라는 현재 쓰레드에서 실행된 것을 확인할 수 있음
2. Scheduler.single()
- 쓰레드 하나만 생성해서 Scheduler가 제거되기 전까지 재사용하는 방식
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static void main(String[] args) throws InterruptedException { | |
| doTask("task1") | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| doTask("task2") | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| Thread.sleep(200L); | |
| } | |
| private static Flux<Integer> doTask(String taskName) { | |
| return Flux.fromArray(new Integer[] {1, 3, 5, 7}) | |
| .publishOn(Schedulers.single()) | |
| .filter(data -> data > 3) | |
| .doOnNext(data -> log.info("# {} doOnNext filter: {}", taskName, data)) | |
| .map(data -> data * 10) | |
| .doOnNext(data -> log.info("# {} doOnNext map: {}", taskName, data)); | |
| } |

부연 설명
- doTask()라는 메서드를 호출해서 각자 다른 작업을 처리한다고 가정
- Schedulers.single()을 사용했기 때문에 doTask()를 두 번 호출하더라도 첫 번째 호출에서 이미 생성된 쓰레드를 재사용
- 이처럼 Schedulers.single()을 통해 하나의 쓰레드를 재사용하면서 다수의 작업을 처리할 수 있는데 하나의 쓰레드로 다수의 작업을 처리해야 되므로 지연 시간이 짧은 작업을 처리하는 것이 효과적
3. Schedulers.newSingle()
- 호출할 때마다 매번 새로운 쓰레드 하나를 생성
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static void main(String[] args) throws InterruptedException { | |
| doTask("task1") | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| doTask("task2") | |
| .subscribe(data -> log.info("# onNext: {}", data)); | |
| Thread.sleep(200L); | |
| } | |
| private static Flux<Integer> doTask(String taskName) { | |
| return Flux.fromArray(new Integer[] {1, 3, 5, 7}) | |
| .publishOn(Schedulers.newSingle("new-single", true)) | |
| .filter(data -> data > 3) | |
| .doOnNext(data -> log.info("# {} doOnNext filter: {}", taskName, data)) | |
| .map(data -> data * 10) | |
| .doOnNext(data -> log.info("# {} doOnNext map: {}", taskName, data)); | |
| } |

부연 설명
- Schedulers.newSingle() 메서드의 첫 번째 파라미터에는 생성할 쓰레드명을 지정하고 두 번째 파라미터는 해당 쓰레드를 데몬 쓰레드로 동작하게 할지 여부를 설정
- 데몬 쓰레드는 보조 쓰레드라고도 불리는데 main 쓰레드가 종료되면 자동으로 종료되는 특성이 있음
- doTask() 메서드를 호출할 때마다 새로운 쓰레드 하나를 생성해서 각각의 작업을 처리하는 것을 확인 가능
4. Schedulers.boundedElastic()
- ExecutorService 기반의 쓰레드 풀을 생성한 후 그 안에서 정해진 수만큼의 쓰레드를 사용하여 작업을 처리하고 작업이 종료된 쓰레드는 반납하여 재사용하는 방식
- 기본적으로 CPU 코어수의 10배만큼의 쓰레드를 생성하여 풀에 속한 모든 쓰레드가 작업을 처리하고 있다면 이용 가능한 쓰레드가 생길 때까지 최대 10만개의 작업이 큐에서 대기할 수 있음
- Schedulers.boundedElastic()은 Blocking I/O 작업을 효과적으로 처리하기 위한 방식
- 실행 시간이 긴 Blocking I/O 작업이 포함된 경우 다른 Non-Blocking 처리에 영향을 주지 않도록 전용 쓰레드를 할당해서 Blocking I/O 작업을 처리
5. Schedulers.parallel()
- Non-Blocking I/O에 최적화되어 있는 Scheduler로써 CPU 코어 수만큼의 쓰레드를 생성
6. Schedulers.fromExecutorService()
- 기존에 이미 사용하고 있는 ExecutorService가 있다면 해당 ExecutorService로부터 Scheduler를 생성하는 방식
- ExecutorService로부터 직접 생성할 수도 있지만 Reactor에서는 해당 방식을 권장하지 않음
7. Schedulers.newXXXX()
- Schedulers.single(), Schedulers.boundedElastic(), Schedulers.parallel()은 Reactor에서 제공하는 디폴트 Scheduler 인스턴스를 사용하지만 필요할 경우 Schedulers.newSingle(), Schedulers.newBoundedElastic(), Schedulers.newParallel() 메서드를 사용해서 새로운 Scheduler 인스턴스를 생성할 수 있음
- 쓰레드명, 생성 가능한 디폴트 쓰레드의 개수, 쓰레드의 유휴 시간, 데몬 쓰레드로의 동작 여부 등을 직접 지정해서 커스텀 쓰레드 풀을 새로 생성할 수 있음
참고
- 스프링으로 시작하는 리액티브 프로그래밍 (황정식 저자)
반응형
'Spring > 스프링으로 시작하는 리액티브 프로그래밍' 카테고리의 다른 글
| [Reactor] Reactor Sequence 디버깅 방법 (0) | 2024.07.31 |
|---|---|
| [Reactor] Context (0) | 2024.07.30 |
| [Reactor] Sinks (0) | 2024.07.23 |
| [Reactor] Backpressure (0) | 2024.07.18 |
| [Reactor] Cold Sequence, Hot Sequence (0) | 2024.07.17 |