JPA (Java Persistence API)
- JPA는 자바 진영의 ORM 기술 표준
- ORM (Object-Relational Mapping) 프레임워크는 객체와 관계형 데이터베이스 간의 차이를 중간에 해결해 주는 프레임워크
- 스프링 진영에서도 스프링 데이터 JPA라는 기술을 통해 JPA를 적극 지원
- 전자정부 표준 프레임워크의 ORM 기술도 JPA 사용
- JPA는 실행 시점에 자동으로 SQL을 만들어서 실행하기 때문에 JPA를 사용하는 개발자는 SQL을 직접 작성하는 것이 아니라 어떤 SQL이 실행될지 생각만 하면 되며 JPA가 실행하는 SQL은 쉽게 예측 가능
- 경우에 따라 JPQL, native query 혹은 QueryDSL을 직접 작성해야 할 때도 많음
- JPA를 사용하면 SQL 대신 객체 중심의 개발 방식을 채택할 수 있음
- 그 결과 생산성과 유지보수가 크게 향상되며 테스트 작성 또한 용이해짐
- 개발 단계에서는 MySQL 데이터베이스를 사용하더라도, 오픈 시점에 Oracle 데이터베이스로 전환하기로 정책이 변경되면 JPA를 통해 코드 수정 없이 단순히 Dialect만 변경하여 데이터베이스를 손쉽게 전환 가능
SQL을 직접 다룰 때 발생하는 문제점
1. SQL 쿼리를 작성하고 JDBC API로 실행하는 과정은 반복적이고 수작업이 많이 필요한 작업
- 자바 컬렉션에 회원 객체를 저장할 때는 list.add(member);처럼 한 줄의 코드로 처리할 수 있는 반면, 데이터베이스는 객체지향 모델과는 다른 데이터 중심의 구조를 가지기 때문에 객체를 직접 저장하거나 조회하는 것이 불가능함
- 개발자는 객체와 관계형 데이터베이스 간의 변환 작업, 즉 객체의 상태를 데이터베이스의 테이블 컬럼에 맞게 변환하고, 반대로 조회된 데이터베이스 결과를 객체 형태로 매핑하는 작업을 직접 구현해야 함
- 이러한 번거로운 변환 작업은 코드의 중복을 낳고, 유지보수 측면에서도 관리 부담을 증가시킴
- 또한, 객체 모델이나 데이터베이스 스키마가 변경될 때마다 관련 SQL문과 매핑 코드를 수정해야 하는 문제점도 존재
2. SQL에 의존하는 개발 방식은 여러 가지 유지보수상의 문제를 발생시킬 수 있음
- 초기에는 단순한 요구사항에 맞춰 SQL 쿼리와 JDBC API를 사용해 객체와 데이터베이스 간의 매핑 작업을 직접 구현했는데 칼럼을 새로 추가하는 요구사항이 들어올 경우 데이터를 저장하고 조회하는 SQL 구문 및 해당하는 JDBC API 코드를 수정해야 하므로, 작업의 번거로움과 실수 가능성이 증가함
- 회원과 팀 테이블이 모두 존재하는 상황에서, 회원이 반드시 특정 팀에 소속되어야 한다는 요구사항이 생기면, 회원 정보를 조회할 때 Member 테이블과 Team 테이블 간의 JOIN 쿼리를 포함시켜야 하며 이는 SQL 문장을 직접 수정해야 하는 추가 부담을 초래하며, 객체 모델과 데이터베이스 간의 관계를 명시적으로 관리해야 하는 어려움을 동반함
- 결과적으로, Member 객체가 연관된 Team 객체를 사용할 수 있는지 여부는 전적으로 개발자가 작성한 SQL에 달려 있음
- Member나 Team처럼 비즈니스 요구사항을 모델링한 객체를 엔티티라 하는데, 지금처럼 SQL에 모든 것을 의존하는 상황에서는 개발자들이 엔티티를 신뢰하고 사용할 수 없음
- 설사 데이터 접근 계층(DAO)을 만들어 SQL 코드의 캡슐화를 시도하더라도, 실제로 어떤 SQL 쿼리가 실행되는지 확인하기 위해 DAO 내부의 SQL 코드를 열어봐야 하는 상황이 발생하기 때문에 이것은 진정한 의미의 계층 분할이 아님
- 이러한 의존성은 데이터베이스 변경이나 비즈니스 로직 수정 시 유지보수 비용을 높이고, 개발에 불필요한 복잡성을 초래함
3. JPA와 문제 해결
- JPA를 사용하면 객체를 데이터베이스에 저장하고 관리할 때, 개발자가 직접 SQL을 작성하는 것이 아니라 JPA가 제공하는 API를 사용함으로써 앞서 언급한 문제들을 해결함
- JPA가 제공하는 CRUD API는 다음과 같음
- 저장 기능: persist() 메서드는 객체를 데이터베이스 저장하며 해당 메서드를 호출할 경우 JPA가 객체와 매핑정보를 보고 적절한 INSERT SQL을 생성해서 데이터베이스에 전달함
- 조회 기능: find() 메서드는 객체 하나를 데이터베이스에서 조회하며 JPA는 객체와 매핑정보를 보고 적절한 SELECT SQL을 생성해서 데이터베이스에 전달하고 그 결과로 Member 객체를 생성해서 반환시킴
- 수정 기능: JPA는 별도의 수정 메서드를 제공하지 않는 대신 Dirty Checking을 통해 객체를 조회해서 값을 변경만 하면 트랜잭션을 커밋할 때 데이터베이스에 적절한 UPDATE SQL이 전달됨
- 연관된 객체 조회: JPA는 연관된 객체를 사용하는 시점에 적절한 SELECT SQL을 실행하기 때문에 JPA 사용 시 연관된 객체를 마음껏 조회 가능
패러다임의 불일치
- 지속 가능한 애플리케이션을 개발하는 일은 끊임없이 증가하는 복잡성과의 싸움
- 객체지향 프로그래밍은 복잡성을 제어할 수 있는 다양한 장치를 제공
- 추상화, 캡슐화, 정보은닉, 상속, 다형성 등 시스템의 복잡성을 다양한 장치들을 제공하기 때문에 현대의 복잡한 애플리케이션은 대부분 객체지향 언어로 개발
- 비즈니스 요구사항을 정의한 도메인 모델도 객체로 모델링하면 객체지향 언어가 가진 장점들을 활용 가능
- 문제는 객체로 모델링한 도메인 모델을 저장할 때 발생
- 부모 객체를 상속받았거나, 다른 객체를 참조하고 있을 경우 객체의 상태를 데이터베이스에 저장하기 쉽지 않음
- ex) 회원 객체를 저장해야 하는데 회원 객체가 팀 객체를 참조하고 있을 경우 회원 객체를 저장할 때 팀 객체도 함께 저장해야 하므로 단순히 회원 객체만 저장할 경우 참조하는 팀 객체를 잃어버리는 문제 발생
- 객체와 관계형 데이터베이스는 지향하는 목적이 서로 다르므로 둘의 기능과 표현 방법이 다름
- 관계형 데이터베이스는 데이터 중심으로 구조화되어 있고, 집합적인 사고를 요구하기 때문에 객체지향에서 이야기하는 추상화, 상속, 다형성 같은 개념이 없음
- 이것을 객체와 관계형 데이터베이스의 패러다임 불일치 문제라 부르며 ORM 프레임워크가 도입되기 전까지는 개발자가 많은 시간과 코드를 소비하며 중간에서 해결해야 했었음
1. 상속
- 객체는 상속이라는 기능을 가지고 있지만 테이블은 상속이라는 기능이 없음
- 일부 데이터베이스는 상속 기능을 지원하지만 객체의 상속과는 약간 다름
- 그나마 데이터베이스 모델링에서 이야기하는 슈퍼타입 서브타입 관계를 사용할 경우 객체 상속과 가장 유사한 형태로 테이블을 설계할 수 있음

- JDBC API를 사용해서 HourlyEmployee 객체를 저장하려면, 해당 객체를 분해해서 EMPLOYEE 테이블에 저장하는 INSERT문과 HOURLY_EMPLOYEE 테이블에 저장하는 INSERT문을 만들어야 함
- 작성해야 할 코드량이 만만치 않고 자식 타입에 따라 DTYPE도 저장해야 하는 번거로움 존재
- 조회하는 것 또한 HourlyEmployee를 조회할 때 HOURLY_EMPLOYEE와 EMPLOYEE 테이블을 조인해서 조회한 후 그 결과로 HourlyEmployee 객체를 생성해야 하는 번거로움 존재
- 정리하면 패러다임의 불일치를 해결하려고 소모하는 비용이 만만치 않음
- JPA는 상속과 관련된 패러다임의 불일치 문제를 개발자 대신 해결해 줌
- 개발자는 마치 자바 컬렉션에 객체를 저장하듯이 JPA에게 객체를 저장하면 됨
- JPA를 사용해서 Employee를 상속한 HourlyEmployee 객체를 저장할 때 앞서 설명한 persist() 메서드를 사용해서 객체를 저장하면 됨
- JPA는 다음 SQL을 실행해서 객체를 EMPLOYEE, HOURLY_EMPLOYEE 두 테이블에 나누어 저장
- INSERT INTO EMPLOYEE
- INSERT INTO HOURLY_EMPLOYEE
- HourlyEmployee 객체를 조회할 때도 앞서 설명한 find() 메서드를 사용해서 객체를 조회하면 됨
- HourlyEmployee hourlyEmployee = jpa.find(HourlyEmployee.class, hourlyEmployeeId);
- JPA는 EMPLOYEE와 HOURLY_EMPLOYEE 두 테이블을 조인해서 필요한 데이터를 조회하고 그 결과를 반환
2. 연관관계
- 객체는 참조를 사용해서 다른 객체와 연관관계를 가지고 참조에 접근해서 연관된 객체를 조회하는 반면 테이블은 외래 키를 사용해서 다른 테이블과 연관관계를 가지고 조인을 사용해서 연관된 테이블을 조회함
- 객체는 member.getTeam()과 같이 참조가 있는 방향으로만 조회가 가능
- 반면, 테이블은 외래 키 하나로 MEMBER JOIN TEAM도 가능하지만 TEAM JOIN MEMBER도 가능함
- 위처럼 객체를 테이블에 맞추어 모델링할 경우 객체를 테이블에 저장하거나 조회할 때는 편리함
- 하지만 여기서 TEAM_ID 외래 키의 값을 그대로 보관하는 teamId 필드에는 문제가 있음
- 관계형 데이터베이스는 JOIN이라는 기능이 있으므로 외래 키의 값을 그대로 보관해도 되지만
- 객체는 연관된 객체의 참조를 보관해야 `Team team = member.getTeam();`처럼 참조를 통해 연관된 객체를 찾을 수 있음
- Member.teamId 필드처럼 TEAM_ID 외래 키까지 관계형 데이터베이스가 사용하는 방식에 맞추면 Member 객체와 연관된 Team 객체를 참조를 통해서 조회할 수 없게 되고 객체지향의 특징을 잃어버리게 됨
- 객체는 참조를 통해서 관계를 맺기 때문에 위처럼 Member.team 필드를 통해 외래 키의 값을 그대로 보관하지 않고 연관된 Team의 참조를 보관하는 것이 바람직함
- `Team team = member.getTeam();`을 통해 회원과 연관된 팀을 조회 가능
- 그런데 이처럼 객체지향 모델링을 사용할 경우 객체를 테이블에 저장하거나 조회하기 쉽지 않음
- 객체를 데이터베이스에 저장하려면 team 필드를 TEAM_ID 외래 키 값으로 변환해야 하는 번거로움 발생
- 조회할 때 또한 TEAM_ID 외래 키 값을 Member 객체의 team 참조로 변환해서 객체에 보관해야 함
- 정리하면 객체 모델은 외래 키가 필요 없고 단지 참조만 있으면 되는 반면 테이블은 참조가 필요 없고 외래 키만 있으면 되기 때문에 패러다임의 불일치가 발생함
- 위 코드처럼 JPA는 연관관계와 관련된 패러다임의 불일치 문제를 해결해 줌
- 개발자는 회원과 팀의 관계를 설정하고 회원 객체를 저장하면 되며 JPA는 team의 잠조를 외래 키로 변환해서 적절한 INSERT SQL을 데이터베이스에 전달
- 객체를 조회할 때 외래 키를 참조로 변환하는 일도 JPA가 처리
3. 객체 그래프 탐색
- 객체에서 회원이 소속된 팀을 조회할 때는 다음처럼 참조를 사용해서 연관된 팀을 찾으면 되는데, 이것을 객체 그래프 탐색이라고 함
- Team team = member.getTeam();
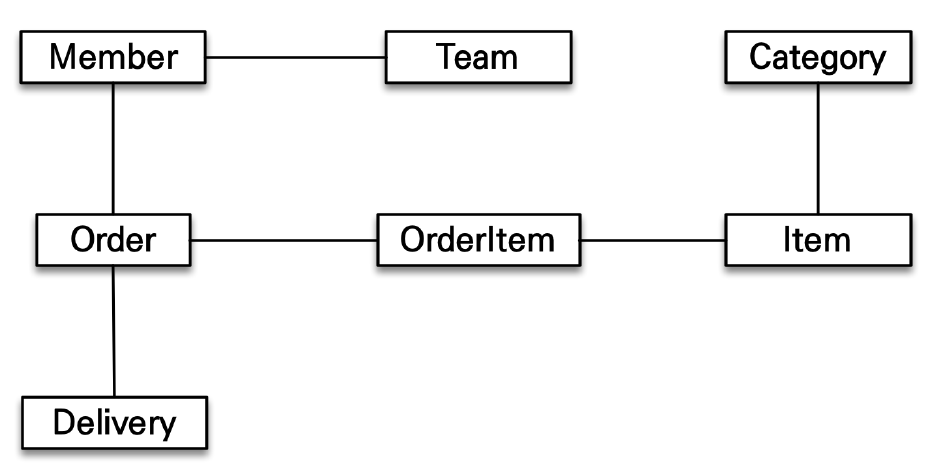
- 객체 연관관계가 위와 같을 때 다음과 같이 자유롭게 객체 그래프를 탐색할 수 있음
- member.getOrder().getOrderItem()...
- 객체는 마음껏 객체 그래프를 탐색할 수 있어야 하지만 SQL을 직접 다룰 경우 처음 실행하는 SQL에 따라 객체 그래프를 어디까지 탐색할 수 있을지 정해짐
- 비즈니스 로직에 따라 사용하는 객체 그래프가 다른데 언제 끊어질지 모를 객체 그래프를 함부로 탐색할 수 없음
- 이것은 객체지향 개발자에겐 너무 큰 제약
- ex) MEMBER와 TEAM 테이블을 JOIN 하여 회원 객체를 조회했을 때 member.getTeam()은 성공하지만 member.getOrder()의 경우 데이터가 없으므로 탐색할 수 없음
- 위와 같이 MemberService가 memberDAO를 통해 member 객체를 조회하는 코드가 있을 때 해당 객체와 연관된 Team, Order, Delivery 방향으로 객체를 탐색할 수 있을지 없을지 판단할 수 없음
- 결국 어디까지 객체 그래프 탐색이 가능한지 알아보려면 데이터 접근 계층인 DAO를 열어서 SQL을 직접 확인해야 함
- member와 연관된 모든 객체 그래프를 DB로부터 조회해서 애플리케이션 메모리에 올려두면 객체 그래프를 탐색할 수 있다는 확신이 서겠지만 현실성이 없으므로 결국 MemberDAO에 회원을 조회하는 메서드를 상황에 따라 여러 번 만들어서 사용하는 것이 최선책
- 엔티티가 SQL에 논리적으로 종속되어 발생하는 문제
- JPA를 사용하면 지연 로딩 (Lazy Loading)을 통해 객체 그래프를 마음껏 탐색할 수 있음
- JPA는 지연 로딩을 투명 (transparent)하게 처리
- 위 코드는 지연 로딩을 사용하는 코드로 처음에는 Member 테이블만 조회하고 마지막 줄의 order.getOrderDate() 같이 실제 Order 객체를 사용하는 시점에 JPA는 데이터베이스에서 ORDER 테이블을 조회함
- Member를 사용할 때마다 Order를 함께 사용할 경우 Member를 조회하는 시점에 SQL 조인을 사용해서 Member와 Order를 함께 조회하는 것이 효과적
- 따라서 JPA는 연관된 객체를 즉시 함께 조회할지 아니면 실제 사용되는 시점에 지연해서 조회할지를 간단한 설정으로 정의할 수 있음
- 현업에서는 웬만하면 지연 로딩을 적용하고 필요할 경우 FETCH JOIN 문을 통해 연관 객체를 같이 불러오는 방식으로 처리
4. 비교
- 테이블의 row를 구분하는 방법과 객체를 구분하는 방법에는 차이가 있습니다.
- 데이터베이스는 기본 키의 값으로 각 row를 구분
- 반면 객체는 동일성 (identity) 비교와 동등성 (equality) 비교라는 두 가지 비교 방법이 있음
- 동일성 비교: == 비교로 객체 인스턴스의 주소 값을 비교
- 동등성 비교: equals() 메서드를 사용해서 객체 내부의 값을 비교
- 이런 패러다임의 불일치 문제를 해결하기 위해 데이터베이스의 같은 row를 조회할 때마다 같은 인스턴스를 반환하도록 해야 하지만 구현하기 쉽지 않음
- JPA는 같은 트랜잭션일 때 같은 객체가 조회되는 것을 보장
JPA란 무엇인가?
- 앞서 설명했다시피 JPA는 자바 진영의 ORM 기술 표준
- ORM 프레임워크는 객체와 테이블을 매핑해서 패러다임의 불일치 문제를 개발자 대신 해결해 줌
- ex) ORM 프레임워크 사용 시 객체를 데이터베이스에 저장할 때 INSERT SQL을 직접 작성하는 것이 아니라 객체를 마치 자바 컬렉션에 저장하듯이 ORM 프레임워크에 저장하면 됨
- ORM 프레임워크는 단순히 SQL을 개발자 대신 생성해서 데이터베이스에 전달해 주는 것뿐만 아니라 앞서 이야기한 다양한 패러다임의 불일치 문제들도 해결해 줌
- 따라서 객체 측면에서는 정교한 객체 모델링을 할 수 있고 관계형 데이터베이스는 데이터베이스에 맞도록 모델링하면 되고 둘을 어떻게 매핑해야 하는지 매핑 방법만 ORM 프레임워크에게 알려주면 됨
- 정리하면 ORM 프레임워크 덕분에 개발자는 데이터 중심인 관계형 데이터베이스를 사용해도 객체지향 애플리케이션 개발에 집중할 수 있음
- 자바 진영에 다양한 ORM 프레임워크들이 있는데 그중에 hibernate 프레임워크가 가장 많이 사용됨
- hibernate는 거의 대부분의 패러다임 불일치 문제를 해결해 주는 성숙한 ORM 프레임워크
1. JPA 소개
- 과거 자바 진영은 EJB라는 기술 표준을 만들었고 그 안에 엔티티 빈이라는 ORM 기술도 포함되어 있었지만 너무 복잡하고 기술 성숙도도 떨어졌으며 자바 엔터프라이즈 애플리케이션 서버에서만 동작했음
- 이때 하이버네이트라는 오픈소스 ORM 프레임워크가 등장했고 해당 프레임워크는 EJB의 ORM 기술과 비교했을 때 가볍고 실용적인 데다 기술 성숙도도 높았음
- 또한, 자바 엔터프라이즈 애플리케이션 서버 없이도 동작해서 많은 개발자가 사용하기 시작했음
- 결국 EJB 3.0에서 하이버네이트를 기반으로 새로운 자바 ORM 기술 표준이 만들어졌고 이것이 바로 JPA
- JPA는 자바 ORM 기술에 대한 API 표준 명세이며 쉽게 이야기해서 인터페이스를 모아둔 것
- 따라서 JPA를 사용하려면 JPA를 구현한 ORM 프레임워크를 선택해야 함
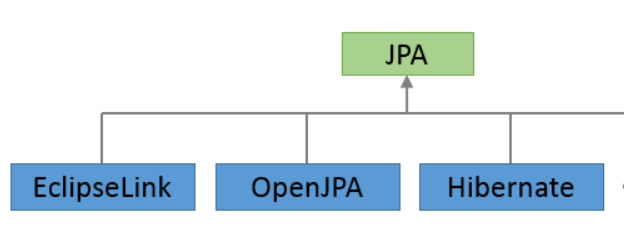
- JPA라는 표준 덕분에 특정 구현 기술에 대한 의존도를 줄일 수 있고 다른 구현 기술로 손쉽게 이동할 수 있는 장점이 있음
2. 왜 JPA를 사용해야 하는가?
2.1 생산성
- JPA를 사용하면 자바 컬렉션에 객체를 저장하듯이 JPA에게 저장할 객체를 전달하면 되고 INSERT SQL을 작성하고, JDBC API를 사용하는 지루하고 반복적인 일은 JPA가 대신 처리해 줌
- 더 나아가 JPA에는 CREATE TABLE 같은 DDL 문을 자동으로 생성해 주는 기능도 있음
- Local 또는 Test 환경에서는 ddl-auto 설정을 create-drop으로 지정하면 애플리케이션 실행 시 자동으로 DDL 문을 생성하고, 종료 시 생성된 테이블을 삭제하는 장점을 누릴 수 있음
- 반면, 개발(Dev) 및 운영(Prod) 환경에서는 ddl-auto를 validate로 설정하는 것이 바람직함, 해당 설정은 DDL 문이 자동으로 수정되지 않고, 애플리케이션 실행 전에 스키마가 올바른지 검증하는 역할을 하여 안정성을 보장
- 이런 기능들을 사용하면 데이터베이스 설계 중심의 패러다임을 객체 설계 중심으로 역전시킬 수 있음
2.2 유지보수
- SQL을 직접 다룰 경우 엔티티에 필드를 하나만 추가해도 관련된 등록, 수정, 조회 SQL과 결과를 매핑하기 위한 JDABC API 코드를 모두 변경해야 함
- 반면, JPA를 사용하면 이런 과정을 JPA가 대신 처리해 주므로 필드를 추가하거나 삭제해도 수정해야 할 코드가 줄어듦
- 따라서 개발자가 작성해야 했던 SQL과 JDBC API 코드를 JPA가 대신 처리해 주므로 유지보수해야 하는 코드 수가 줄어듦
- 또한, JPA가 패러다임의 불일치 문제를 해결해 주므로 객체지향 언어가 가진 장점들을 활용해서 유연하고 유지보수하기 좋은 도메인 모델을 편리하게 설계할 수 있음
2.3 패러다임의 불일치 해결
- JPA는 앞서 언급한 상속, 연관관계, 객체 그래프 탐색, 비교하기와 같은 패러다임의 불일치 문제를 해결해 줌
2.4 성능
- JPA는 애플리케이션과 데이터베이스 사이에서 다양한 성능 최적화 기회를 제공
- JPA는 애플리케이션과 데이터베이스 사이에서 동작하며 이렇게 애플리케이션과 데이터베이스 사이에 계층이 하나 더 있으면 최적화 관점에서 시도해 볼 수 있는 것들이 많음
- 위 코드는 트랜잭션 안에서 같은 회원을 두 번 조회하는 코드의 일부분
- JDBC API를 사용해서 해당 코드를 직접 작성했다면 회원을 조회할 때마다 SELECT SQL을 사용해서 데이터베이스와 두 번 통신했을 것
- JPA를 사용하면 회원을 조회하는 SELECT SQL을 한 번만 데이터베이스에 전달하고 두 번째는 영속성 컨텍스트를 통해 조회한 회원 객체를 재사용
- 다만, JPA를 잘 이해하지 못하고 사용하면 N + 1 같은 문제로 인해 심각한 성능 저하가 발생할 수 있음
- ex) SQL 1번으로 회원 100명을 조회했는데 각 회원마다 주문한 상품을 추가로 조회하기 위해 100번의 SQL을 추가로 실행
2.5 데이터 접근 추상화와 벤더 독립성
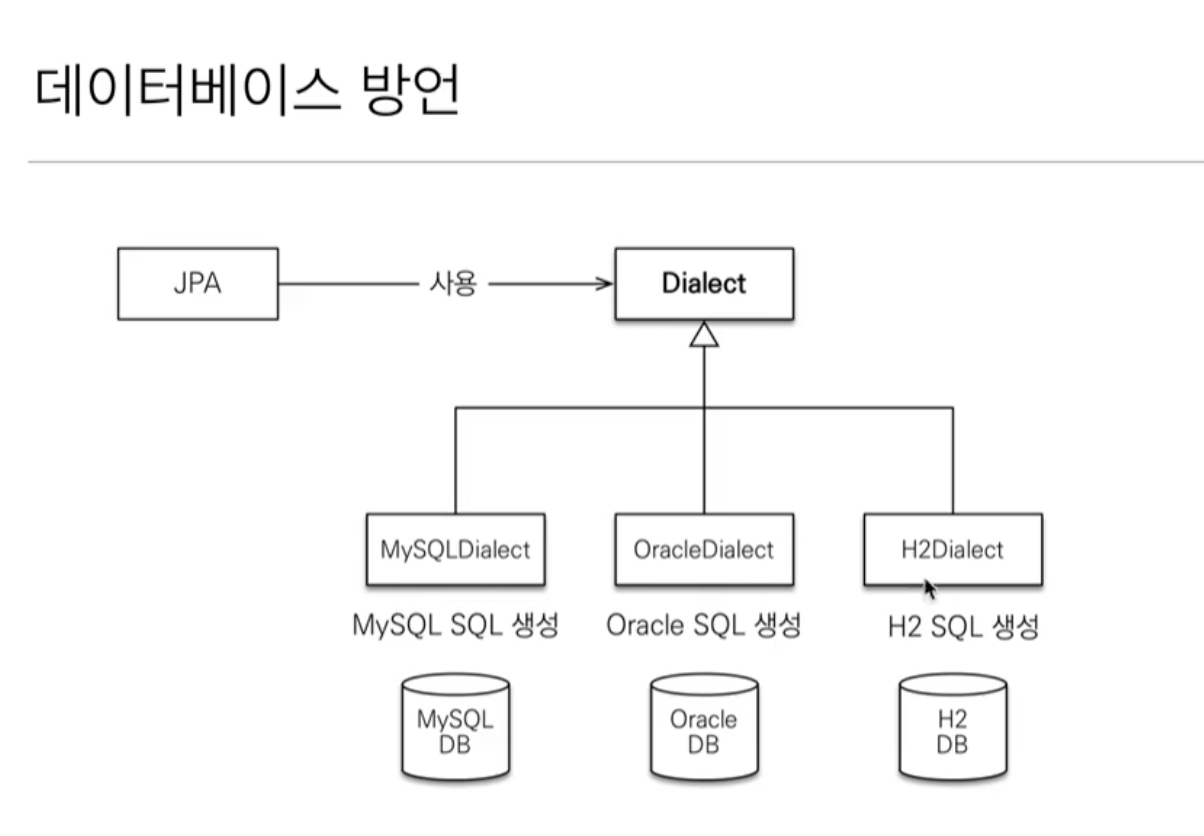
- 관계형 데이터베이스는 같은 기능도 벤더마다 사용법이 다른 경우가 많기 때문에 애플리케이션은 처음 선택한 데이터베이스 기술에 종속되고 다른 데이터베이스로 변경하기 매우 어려움
- JPA는 애플리케이션과 데이터베이스 사이에 추상화된 데이터 접근 계층을 제공해서 애플리케이션이 특정 데이터베이스 기술에 종속되지 않도록 지원
- 만약 데이터베이스를 변경하면 JPA에게 다른 데이터베이스를 사용한다고 알려주기만 하면 됨
- ex) native query를 사용하지 않았다는 가정 하에 JPA를 사용하면 Dialect 변경을 통해 로컬 개발 환경은 H2 데이터베이스를 사용하고 개발이나 상용 환경은 Oracle이나 MySQL 데이터베이스를 사용할 수 있음
참고
자바 ORM 표준 JPA 프로그래밍 - 김영한 저
반응형
'DB > 자바 ORM 표준 JPA 프로그래밍' 카테고리의 다른 글
| [6장] 다양한 연관관계 매핑 (0) | 2025.02.27 |
|---|---|
| [5장] 연관관계 매핑 기초 (1) | 2025.02.24 |
| [4장] 엔티티 매핑 (0) | 2025.02.21 |
| [3장] 영속성 관리 (0) | 2025.02.21 |
| [2장] JPA 시작 (1) | 2025.02.21 |