상속 관계 매핑
- 관계형 데이터베이스에는 객체지향 언어에서 다루는 상속이라는 개념이 없지만
- 슈퍼타입 서브타입 관계 (Super-Type Sub-Type Relationship)라는 모델링 기법이 객체의 상속 개념과 가장 유사함
- ORM에서 이야기하는 상속 관계 매핑은 객체의 상속 구조와 데이터베이스의 슈퍼타입 서브타입 관계를 매핑하는 것
- 슈퍼타입 서브타입 논리 모델을 실제 모델인 테이블로 구현할 때는 다음과 같은 세 가지 방법을 선택 가능
- 각각의 테이블로 변환: 각각을 모두 테이블로 생성하고 조회할 때 조인을 사용하며 JPA에서는 조인 전략이라고 부름
- 통합 테이블로 변환: 테이블을 하나만 사용해서 통합하고 JPA에서는 단일 테이블 전략이라고 부름
- 서브타입 테이블로 변환: 서브 타입마다 하나의 테이블을 생성하며 JPA에서는 구현 클래스마다 테이블 전략이라고 부름
1. 조인 전략
- 엔티티 각각을 모두 테이블로 생성하고 자식 테이블이 부모 테이블의 기본 키를 받아서 기본 키 + 외래 키로 사용하는 전략
- 조회할 때 조인을 자주 사용
- 객체는 타입으로 구분할 수 있지만 테이블은 타입의 개념이 없으므로 타입을 구분하는 컬럼을 추가해야 함
- 책에서는 DTYPE 컬럼을 구분 컬럼으로 사용
- JPA 표준 명세는 구분 컬럼을 사용하는 것을 권장하지만 하이버네이트를 포함한 몇몇 구현체는 구분 컬럼 없이도 동작함

부연 설명
- @Inheritance(strategy = InheritanceType.JOINED): 상속 매핑은 부모 클래스에 @Inheritance를 사용한 뒤 매핑 전략을 지정해야 하는데 여기서는 조인 전략을 사용하므로 InheritanceType.JOINED 사용
- @DiscriminatorColumn(name = "DTYPE"): 부모 클래스에 구분 컬럼을 지정하고 해당 컬럼으로 저장된 자식 테이블을 구분할 수 있음
- @DiscriminatorValue("M"): 엔티티를 저장할 때 구분 컬럼에 입력할 값을 지정, 영화 엔티티를 저장하면 구분 컬럼 DTYPE에 값 M이 저장됨
1.1 조인 전략 장점
- 테이블이 정규화됨
- 외래 키 참조 무결성 제약 조건 활용 가능
- 저장 공간을 효율적으로 사용
1.2 조인 전략 단점
- 조회할 때 조인을 많이 사용하므로 성능 저하 야기
- 조회 쿼리 복잡함
- 테이블 등록 시 INSERT SQL 두 번 실행
2. 단일 테이블 전략
- 이름 그대로 테이블 하나만 사용
- 구분 컬럼 (이 책에서는 DTYPE)으로 어떤 자식 데이터가 저장되었는지를 구분
- 테이블 하나에 모든 것을 통합하므로 구분 컬럼을 필수로 사용
- @DiscriminatorValue를 지정하지 않을 경우 기본으로 엔티티 이름을 사용
- 조회할 때 조인을 사용하지 않으므로 일반적으로 가장 빠름
- 여러 서브 타입을 한 테이블에 저장해야 하므로 자식 엔티티가 매핑한 컬럼은 모두 nullable

2.1 단일 테이블 전략 장점
- 조인이 필요 없기 때문에 일반적으로 조회 성능 우수
- 조회 쿼리가 단순함
2.2 단일 테이블 전략 단점
- 자식 엔티티가 매핑한 컬럼은 모두 nullable
- 단일 테이블에 모든 것을 저장하기 때문에 테이블이 비대해질 수 있으며 테이블이 커질수록 조회 성능이 느려질 수 있음
3. 구현 클래스마다 테이블 전략
- 자식 엔티티마다 테이블 생성하며 자식 테이블 각각에 필요한 컬럼이 모두 있음
- 앞선 전략들과 달리 구분 컬럼을 사용하지 않음
- 일반적으로 추천하지 않는 전략

3.1 구현 클래스마다 테이블 전략 장점
- 서브 타입을 구분해서 처리할 때 효과적
- not null 제약 조건을 사용할 수 있음
3.2 구현 클래스마다 테이블 전략 단점
- SQL에 UNION을 사용하기 때문에 여러 자식 테이블을 함께 조회할 때 성능이 느림
- 자식 테이블을 통합해서 쿼리하기 어려움
@MappedSuperclass
- 앞서 학습한 상속 관계 매핑은 부모 클래스와 자식 클래스를 모두 데이터베이스 테이블과 매핑했음
- 부모 클래스는 테이블과 매핑하지 않고 부모 클래스를 상속 받는 자식 클래스에게 매핑 정보만 제공하고 싶을 경우 @MappedSuperclass 어노테이션을 사용
- 추상 클래스와 비슷한데 @Entity는 실제 테이블과 매핑되지만
- @MappedSuperclass는 실제 테이블과 매핑되지 않음
- 매핑 정보를 상속할 목적으로만 사용
- MappedSuperclass로 지정한 클래스는 엔티티가 아니므로 em.find()나 JPQL에서 사용할 수 없음
- 해당 클래스를 직접 생성해서 사용할 일은 거의 없으므로 추상 클래스로 생성하는 것을 권장
- @MappedSuperclass를 사용하면 등록일자, 수정일자, 등록자, 그리고 수정자 같은 여러 엔티티에서 공통으로 사용하는 속성을 효과적으로 관리할 수 있음

부연 설명
- BaseEntity에는 객체들이 주로 사용하는 공통 매핑 정보를 정의했고 자식 엔티티들은 상속을 통해 BaseEntity의 매핑 정보를 물려받음
- BaseEntity는 테이블과 매핑할 필요가 없고 자식 엔티티에게 공통으로 사용되는 매핑 정보만 제공하면 되기 때문에 @MappedSuperclass를 사용함
복합 키와 식별 관계 매핑
1. 식별 관계 vs 비식별 관계
- 데이터베이스 테이블 사이 관계는 외래 키가 기본 키에 포함되는지 여부에 따라 식별 관계와 비식별 관계로 구분함
식별 관계 (Identifying Relationship)
- 식별 관계는 부모 테이블의 기본 키를 내려받아 자식 테이블의 기본 키 + 외래 키로 사용하는 관계

비식별 관계 (Non-identifying Relationship)
- 부모 테이블의 기본 키를 받아 자식 테이블의 외래 키로만 사용
- 비식별 관계는 외래 키에 NULL을 허용하는지 여부에 따라 필수적 비식별 관계와 선택적 비식별 관계로 구분
- 필수적 비식별 관계: 외래 키에 NULL을 허용하지 않으며 연관관계를 필수적으로 맺어야 함
- 선택적 비식별 관계: 외래 키에 NULL을 허용하며 연관관계를 맺을지 여부를 선택 가능
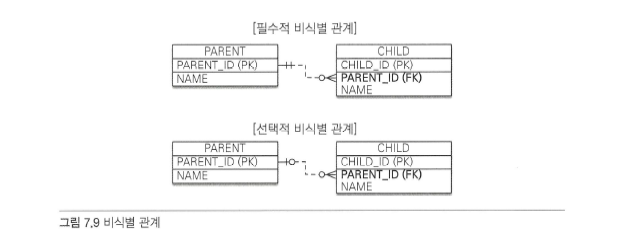
- 데이터베이스 테이블을 설계할 때 식별 관계나 비식별 관계 중 하나를 선택해야 하며 최근에는 비식별 관계를 주로 사용하고 꼭 필요한 곳에만 식별 관계를 사용하는 추세
- JPA는 식별 관계와 비식별 관계를 모두 지원
2. 복합 키: 비식별 관계 매핑
- JPA에서 기본 키를 구성하는 컬럼이 하나면 @Id 어노테이션을 통해 단순하게 매핑하면 되지만
- 둘 이상의 컬럼으로 구성된 복합 기본 키를 사용하고 싶을 때 별도의 식별자 클래스를 생성해야 함
- JPA는 복합 키를 지원하기 위해 @IdClass와 @EmbeddedId 두 가지 방법을 제공
- 식별자 필드가 하나일 때는 보통 자바의 기본 타입을 사용하므로 문제가 없으나 식별자 필드가 두 개 이상이면 별도의 식별자 클래스를 만들고 그곳에 equals와 hashCode를 구현해야 함
- JPA는 영속성 컨텍스트에 엔티티를 보관할 때 엔티티의 식별자를 키로 사용하며 식별자를 구분하기 위해 equals와 hashCode를 사용해서 동등성 비교 진행
- 따라서 식별자 객체의 동등성 (equals 비교)이 지켜지지 않으면 예상과 다른 엔티티가 조회되거나 엔티티를 찾을 수 없는 등 영속성 컨텍스트가 엔티티를 관리하는 데 심각한 문제가 발생하므로 복합 키는 equals()와 hashCode()를 필수로 구현해야 함
- 복합 키에는 @GeneratedValue를 사용할 수 없음
2.1 @IdClass
- @IdClass를 사용할 때 식별자 클래스는 다음 조건을 만족해야 함
- 식별자 클래스의 속성명과 엔티티에서 사용하는 식별자의 속성명이 같아야 함 i.g. Parent.id1과 ParentId.id1, Parent.id2와 ParentId.id2
- Serializable 인터페이스를 구현해야 함
- equals와 hashCode를 구현해야 함
- 기본 생성자가 있어야 함
- 식별자 클래스는 public이어야 함

부연 설명
- 위 코드에서 복합 키 테이블은 비식별 관계이며 PARENT는 복합 기본 키를 사용
- PARENT 테이블을 보면 기본 키를 PARENT_ID1, 그리고 PARENT_ID2로 묶은 복합 키로 구성
- 이에 따라 복합 키를 매핑하기 위해 식별자 클래스를 별도로 생성
- 부모 테이블의 기본 키 컬럼이 복합 키이기 때문에 자식 테이블의 외래 키도 복합 키
- 따라서 외래 키 매핑 시 여러 컬럼을 매핑해야 하기 때문에 @JoinColumns 어노테이션을 사용하고 각각의 외래 키 컬럼을 @JoinColumn으로 매핑
복합 키를 사용하여 저장 및 조회하는 예
부연 설명
- 저장 코드를 보면 식별자 클래스인 ParentId가 보이지 않는데, em.persist()를 호출할 경우 영속성 컨텍스트에 엔티티를 등록하기 직전에 내부에서 Parent.id1, Parent.id2 값을 사용해서 식별자 클래스인 ParentId를 생성하고 영속성 컨텍스트의 키로 사용
- 조회 코드를 보면 식별자 클래스인 ParentId를 상요해서 엔티티를 조회
2.2 @EmbeddedId
- @IdClass가 데이터베이스에 맞춘 방법이라면 @EmbeddedId는 좀 더 객체지향적인 방법
- Parent 엔티티에서 식별자 클래스를 직접 사용하고 @EmbeddedId 어노테이션을 부여하면 됨
- @IdClass와는 다르게 @EmbeddedId를 적용한 식별자 클래스는 식별자 클래스에 기본 키를 직접 매핑
- @EmbeddedId를 적용한 식별자 클래스는 다음 조건을 만족해야 함
- @Embeddable 어노테이션을 붙여주어야 함
- Serializable 인터페이스를 구현해야 함
- equals, hashCode를 구현해야 함
- 기본 생성자가 있어야 함
- 식별자 클래스는 public이여야 함
@EmbeddedId를 사용하여 저장 및 조회하는 코드
2.3 @IdClass vs @EmbeddedId
- 각각 장단점이 있기 때문에 취향 차이
- @EmbeddedId가 @IdClass에 비해 객체지향적이고 중복도 없어서 좋아 보이긴 하지만 특정 상황에 JPQL이 조금 더 길어질 수 있음
- @EmbeddedId: em.createQuery("SELECT p.id.id1, p.id.id2 FROM Parent p);
- @IdClass: em.createQuery("SELECT p.id1, p.id2 FROM Parent p);
3. 복합 키: 식별 관계 매핑
- 아래 그림을 보면 부모, 자식, 그리고 손자까지 계속 기본 키를 전달하는 식별 관계
- 식별 관계에서 자식 테이블은 부모 테이블의 기본 키를 포함해서 복합 키를 구성해야 하므로 @IdClass나 @EmbeddedId를 사용해서 식별자를 매핑함

3.1 @IdClass와 식별 관계
부연 설명
- 식별 관계는 기본 키와 외래 키를 같이 매핑해야 하기 때문에 식별자 매핑인 @Id와 연관관계 매핑인 @ManyToOne을 같이 사용하면 됨
- Child 엔티티의 parent 필드를 보면 @Id로 기본 키를 매핑하면서 @ManyToOne과 @JoinColumn으로 외래 키를 같이 매핑함
3.2 @EmbeddedId와 식별 관계
부연 설명
- @EmbeddedId는 식별 관계로 사용할 연관관계의 속성에 @MapsId를 사용하면 됨
- @IdClass와 다른 점은 @Id 대신에 @MapsId를 사용한다는 것인데 @MapsId는 외래 키와 매핑한 연관관계를 기본 키에도 매핑하겠다는 뜻
- @MapsId의 속성 값은 @EmbeddedId를 사용한 식별자 클래스의 기본 키 필드를 지정하면 되며 위 코드에서는 ChildId의 parentId 필드를 선택
4. 비식별 관계로 구현
- 복합 키가 없으므로 복합 키 클래스 없이 구현 가능
- 식별 관계의 복합 키를 사용한 코드와 비교했을 때 매핑도 쉽고 코드가 단순함

5. 일대일 식별 관계
- 일대일 식별 관계는 자식 테이블의 기본 키 값으로 부모 테이블의 기본 키 값만 사용함
- 이에 따라 부모 테이블의 기본 키가 복합 키가 아니면 자식 테이블의 기본 키 또한 복합 키로 구성하지 않아도 됨

부연 설명
- BoardDetail처럼 식별자가 단순히 컬럼 하나일 경우 속성 값을 비워둔 상태로 @MapsId를 사용하면 됨
- @MapsId는 @Id를 사용해서 식별자로 지정한 BoardDetail.boardId와 매핑됨
5.1 일대일 식별 관계 저장하는 예시
6. 식별, 비식별 관계의 장단점
식별 관계를 사용하면 기본 키 인덱스를 활용하기 좋고, 상위 테이블들의 기본 키 칼럼을 자식, 손자 테이블들이 가지고 있으므로 특정 상황에 조인 없이 하위 테이블만으로 검색할 수 있다는 장점이 있습니다.
하지만 데이터베이스 설계 관점에서 봤을 때 다음과 같은 이유로 식별 관계보다는 비식별 관계를 선호합니다.
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블로 전파하면서 자식 테이블의 기본 키 칼럼이 점점 늘어나며 이에 따라 조인할 때 SQL이 복잡해지고 기본 키 인덱스가 불필요하게 커질 수 있음 (복합키: 식별관계 매핑의 부모, 자식, 손자 예시 참고)
- 식별 관계는 두 개 이상의 컬럼을 합해서 복합 기본 키를 만들어야 하는 케이스가 많음
- 식별 관계를 사용할 때 기본 키로 비즈니스 의미가 있는 자연 키 컬럼을 조합하는 경우가 많은 반면 비식별 관계의 기본 키는 비즈니스와 전혀 관계없는 대리 키를 주로 사용 (비즈니스 요구사항은 시간이 지남에 따라 언젠가는 변하기 때문에 식별 관계의 자연 키 컬럼들이 자식에 손자까지 전파되면 변경하기 힘듦)
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블의 기본 키로 사용하므로 비식별 관계보다 테이블 구조가 유연하지 못 함
객체 관계 매핑의 관점에서 보더라도 다음과 같은 이유로 비식별 관계를 선호합니다.
- 일대일 관계를 제외하고 식별 관계는 두 개이상의 컬럼을 묶은 복합 기본 키를 사용하는데 JPA에서 복합 키는 별도의 복합 키 클래스를 만들어서 사용해야 하기 때문에 번거로움
- 비식별 관계의 기본 키는 주로 대리 키를 사용하는데 JPA는 @GeneratedValue처럼 대리 키를 생성하기 위한 편리한 방법 제공
ORM 신규 프로젝트 진행시 추천하는 방법은 다음과 같습니다.
- 비식별 관계를 사용
- 비즈니스 요구사항이 변경하더라도 유연한 대처가 가능하도록 기본 키를 비즈니스와 관련 없는 Long 타입의 대리키로 선정
- 선택적 비식별 관계는 nullable이므로 LEFT OUTER JOIN을 사용해야 하는데 필수적 관계는 NOT NULL로 항상 관계가 있다는 것을 보장하므로 INNER JOIN만 사용해도 되기 때문에 필수적 비식별 관계 추천
조인 테이블
데이터베이스 테이블의 연관관계를 설계하는 방법은 다음과 같이 크게 두 가지입니다.
- 조인 컬럼 사용 (외래 키)
- 조인 테이블 사용
조인 컬럼 사용
- 테이블 간에 관계는 주로 조인 컬럼이라 부르는 외래 키 컬럼을 사용해서 관리
- ex) 회원과 사물함이 있는데 각각 테이블에 데이터를 등록했다가 회원이 원할 때 사물함을 선택할 수 있다고 가정
- 회원이 사물함을 사용하기 전까지는 아직 둘 사이에 관계가 없으므로 MEMBER 테이블의 LOCKER_ID 외래 키에 null을 입력해야 함
- 이렇게 외래 키에 null을 허용하는 관계를 선택적 비식별 관계라 함

부연 설명
- 선택적 비식별 관계는 외래 키에 null을 허용하므로 회원과 사물함을 조인할 때 LEFT OUTER JOIN을 사용해야 함
- INNER JOIN 사용 시 조회 안됨
- 회원과 사물함이 아주 가끔 관계를 맺는다면 외래 키 값 대부분이 null로 저장되는 단점 존재
조인 테이블 사용
- 조인 테이블은 별도의 테이블을 사용해서 연관관계를 관리함
- 조인 컬럼을 사용하는 방법은 단순히 외래 키 커럼만 추가해서 연관관계를 맺지만
- 조인 테이블을 사용하는 방법은 연관관계를 관리하는 조인 테이블을 추가하고 여기서 두 테이블의 외래 키를 가지고 연관관계를 관리함
- 조인 테이블의 가장 큰 단점은 테이블을 하나 추가해야 한다는 점
- 관리해야 하는 테이블이 늘어나고 회원과 사물함 두 테이블을 조인하려면 MEMBER_LOCKER 테이블까지 추가로 조인해야 함
- 이에 따라 기본은 조인 컬럼을 사용하고 필요하다고 판단되면 조인 테이블을 사용하는 것을 권장
- 조인 테이블에 별도 컬럼을 추가할 경우 @JoinTable 전략을 사용할 수 없음
- 컬럼 추가를 원할 경우 새로운 엔티티를 생성한 뒤 조인 테이블과 매핑

부연 설명
- 연관관계를 관리하는 조인 테이블 (MEMBER_LOCKER)이 두 테이블의 외래 키를 가지고 연관관계를 관리함
- 이에 따라 MEMBER와 LOCKER에는 연관관계를 관리하기 위한 외래 키 칼럼이 없음
- 회원과 사물함 데이터를 각각 등록했다가 회원이 원할 때 사물함을 선택하면 MEMBER_LOCKER 테이블에만 값을 추가해야 됨
1. 일대일 조인 테이블
- 일대일 관계를 만들려면 조인 테이블의 외래 키 컬럼 각각에 총 두 개의 유니크 제약조건을 걸어야 함
- PARENT_ID는 기본 키이므로 유니크 제약조건이 걸려 있음

부연 설명
- 부모 엔티티를 보면 @JoinColumn 대신 @JoinTable 어노테이션을 사용
- @JoinTable의 속성은 다음과 같음
- name: 매핑할 조인 테이블명
- joinColumns: 현재 엔티티를 참조하는 외래 키
- inverseJoinColumns: 반대방향 엔티티를 참조하는 외래 키
2. 일대다 조인 테이블
- 일대다 관계를 만들려면 조인 테이블의 컬럼 중 다 (N)와 관련된 컬럼인 CHILD_ID에 유니크 제약조건을 걸어야 함
- CHILD_ID는 기본 키이므로 유니크 제약조건이 걸려 있음

3. 다대일 조인 테이블
- 다대일은 일대다에서 방향만 바대이므로 조인 테이블 모양은 일대다에서 설명한 것과 같음
4. 다대다 조인 테이블
- 다대다 관계를 만들렴녀 조인 테이블의 두 컬럼을 합해서 하나의 복합 유니크 제약조건을 걸어야 함
- PARENT_ID와 CHILD_ID는 복합 기본 키이므로 유니크 제약조건이 걸려 있음

5. 엔티티 하나에 여러 테이블 매핑
- 잘 사용하지는 않지만 @SecondaryTable 어노테이션을 사용하면 한 엔티티에 여러 테이블을 매핑할 수 있음
- @SecondaryTable을 사용해서 두 테이블을 하나의 엔티티에 매핑하는 방법보다는 테이블당 엔티티를 각각 생성해서 일대일 매핑하는 것을 권장
- @SecondaryTable을 사용하면 항상 두 테이블을 조회하므로 최적화하기 어려움
- 일대일 매핑은 원하는 부분만 조회할 수 있고 필요하면 둘을 함께 조회하면 됨

부연 설명
- Board 엔티티는 @Table을 사용해서 BOARD 테이블과 매핑했으며 @SecondaryTable을 사용해서 BOARD_DETAIL 테이블을 추가로 매핑함
- @SecondaryTable 속성은 다음과 같음
- name: 매핑할 다른 테이블명 i.g. BOARD_DETAIL
- pkJoinColumns: 매핑할 다른 테이블의 기본 키 컬럼 속성 i.g. BOARD_DETAIL_ID
- content 필드는 @Column(table = "BOARD_DETAIL")을 사용해서 BOARD_DETAIL 테이블의 컬럼에 매핑함
- title 필드처럼 테이블을 지정하지 않을 경우 기본 테이블인 BOARD에 매핑됨
참고
자바 ORM 표준 JPA 프로그래밍 - 김영한 저
'DB > 자바 ORM 표준 JPA 프로그래밍' 카테고리의 다른 글
| [9장] 값 타입 (0) | 2025.03.04 |
|---|---|
| [8장] 프록시와 연관관계 관리 (0) | 2025.03.01 |
| [6장] 다양한 연관관계 매핑 (0) | 2025.02.27 |
| [5장] 연관관계 매핑 기초 (1) | 2025.02.24 |
| [4장] 엔티티 매핑 (0) | 2025.02.21 |