1. 동기화
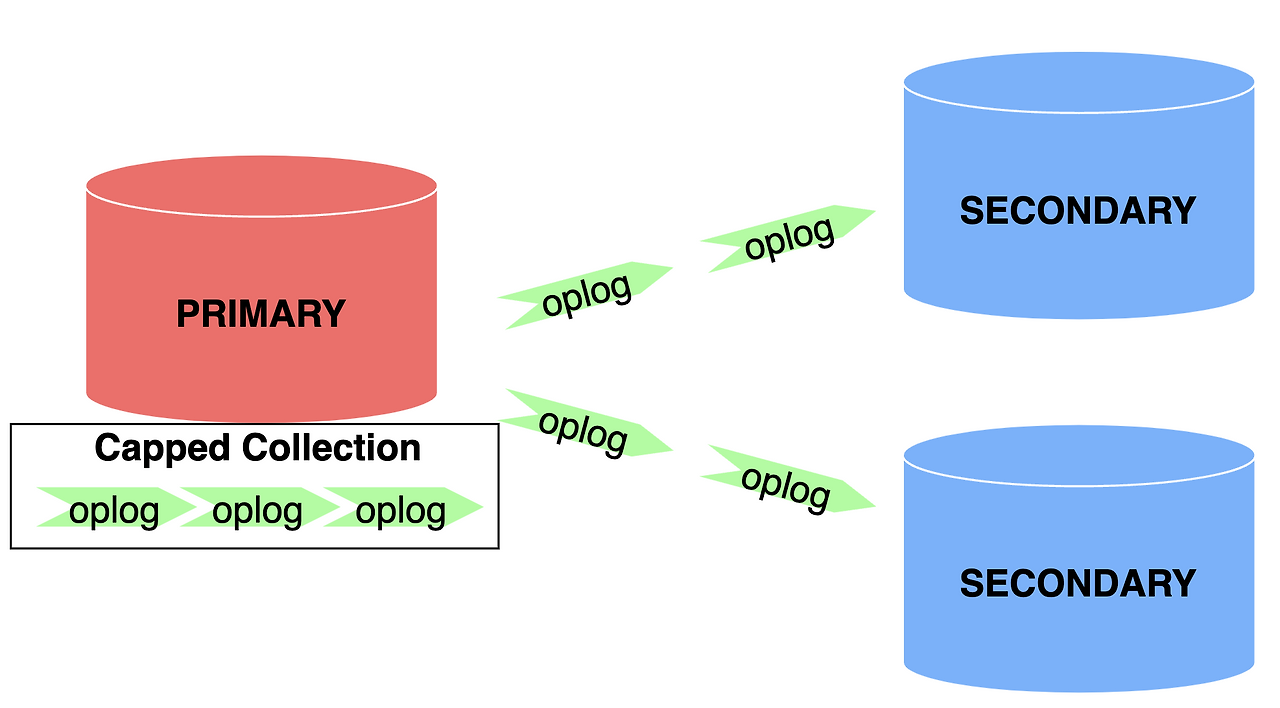
- 몽고DB는 Primary가 수행한 쓰기를 모두 포함하는 로그, 즉 oplog를 보관함으로써 복제를 수행
- oplog는 Primary의 로컬 데이터베이스에 있는 제한 컬렉션이며, Secondary는 해당 컬렉션에 복제를 위한 연산을 쿼리
- 각 Secondary는 Primary로부터 복제한 작업을 각각 기록하는 oplog를 보관
- Secondary는 동기화하는 멤버로부터 연산을 가져와서 데이터셋에 적용한 뒤 자신의 oplog에 씀
- 만약 연산 적용에 실패하면 Secondary는 종료됨
- Secondary가 어떤 이유로든 다운되면, 재시작할 때 oplog에 있는 마지막 연산과 동기화 수행
- 연산이 데이터에 적용되고 oplog에 쓰이면, Secondary는 이미 데이터에 적용된 연산을 재생할 수 있음, 즉 oplog 연산은 여러 번 재생해도 한 번 재생할 때와 같은 결과를 얻음 (oplog의 각 작업은 멱등)
- oplog는 크기가 고정되어 있으므로 담을 수 있는 연산의 수가 정해져 있음
- 일반적으로 oplog는 쓰기 연산이 시스템에 적용될 때와 비슷하게 공간을 차지
- Primary에 쓰기 연산이 분당 1kb 발생한다면, oplog는 대략 분당 1kb씩 채워짐
- 삭제나 다중갱신처럼 여러 도큐먼트에 영향을 미치는 연산은 여러 개의 oplog 항목으로 분해됨
- 연산 하나가 Primary에 수행되면, 영향받는 도큐먼트 개수당 하나씩 oplog 연산으로 분할됨
- 따라서 db.col.remove()로 컬렉션에 있는 도큐먼트 중 100만 개를 삭제할 경우 oplog 항목 100만 개가 도큐먼트를 하나씩 삭제함
- 대량 작업을 수행하는 경우 oplog가 예상보다 빨리 채워질 수 있음
- 일반적으로 oplog는 기본 크기면 충분하지만
- 복제 셋 워크로드가 다음 패턴 중 하나와 같다고 예상한다면 기본값보다 큰 oplog를 생성할 수 있음
- 반대로 애플리케이션이 주로 최소한의 쓰기 작업으로 읽기를 수행한다면 작은 oplog로 충분
다음은 oplog 크기가 기본 크기보다 커야 할 수도 있는 워크로드 종류입니다.
- 한 번에 여러 도큐먼트 갱신
- 삽입한 데이터와 동일한 양의 데이터 삭제
- 상당한 수의 내부 갱신
가. 한 번에 여러 도큐먼트 갱신
- oplog는 멱등성을 유지하기 위해 다중갱신을 개별 작업으로 변환해야 하는데 이때 oplog 공간을 많이 차지할 수 있으며, 데이터 크기나 디스크 사용은 이에 상응해 증가하지 않음
나. 삽입한 데이터와 동일한 양의 데이터 삭제
- 삽입한 데이터와 거의 같은 양의 데이터를 삭제하면, 데이터베이스는 디스크 사용량 측면에서 크게 증가하지 않지만 oplog 크기는 상당히 클 수 있음
다. 상당한 수의 내부 갱신
- 워크로드 상당 부분이 도큐먼트 크기를 증가시키지 않는 갱신이면, 데이터베이스가 기록하는 작업의 수는 많지만 디스크상 데이터 양은 변하지 않음
몽고DB에서 데이터 동기화는 두 가지 형태가 있습니다.
- 전체 데이터셋으로 새 멤버를 채우는 초기 동기화
- 전체 데이터셋에 지속적인 변경 사항을 적용하는 복제
1.1 초기 동기화
- 몽고DB는 초기 동기화를 수행해 복제 셋의 한 멤버에서 다른 멤버로 모든 데이터를 복사함
- 복제 셋 멤버는 시작할 때, 다음 멤버와 동기화를 시작하기에 유효한 상태인지 확인
- 유효할 경우 복제 셋의 다른 멤버의 데이터 전체를 복사
- 프로세스는 여러 단계에 걸쳐 진행하며 mongod 로그에서 확인 가능
- 먼저 몽고DB는 local 데이터베이스를 제외한 모든 데이터베이스를 복제함
- mongod는 각 소스 데이터베이스 내 컬렉션을 모두 스캔하고, 모든 데이터를 대상 멤버에 있는 자체 컬렉션 복사본에 삽입함
- 대상 멤버의 기존 데이터는 복제 작업을 시작하기 전에 삭제됨
- 몽고DB 3.4 및 이후 버전에서는 각 컬렉션에서 도큐먼트가 복사될 때 초기 동기화가 모든 컬렉션 인덱스를 구축
- 데이터 복사 중에 새로 추가된 oplog 레코드를 가져오므로, 대상 멤버가 데이터 복사 단계에서 레코드를 저장할 충분한 디스크 공간이 local 데이터베이스에 있는지 확인 필요
- 모든 데이터베이스가 복제되면 mongod는 소스의 oplog를 사용해 복제 셋의 현재 상태를 반영하도록 데이터셋을 갱신하고, 복사가 진행되는 동안 발생한 데이터셋에 모든 변경 사항을 적용
- 변경 사항에는 모든 유형의 쓰기가 있을 수 있음
- 즉 mongod는 복제자가 발견하지 못한 도큐먼트를 재복제해야 함
- 초기 동기화는 데이터 디렉토리가 깔끔한 상태에서 mongod를 시작하면 되므로 운영자 관점에서 쉬운 작업
- 하지만 23장에서 후술 할 다른 백업으로부터 복원하는 방식이 더 바람직함
- 백업으로부터 복원하면 mongod를 통해 모든 데이터를 복사할 때보다 빠를 때가 많음
- 복제는 동기화 소스의 작업 셋을 망칠 수 있으므로 주의해야 함
- 대부분의 배포는 결국 자주 접근하고 항상 메모리에 존재하는 데이터의 서브셋
- 초기 동기화를 수행하면 해당 멤버는 자주 사용되는 데이터를 축출해 메모리로 페이징 하며, 이는 램에 있는 데이터가 처리하던 요청들이 갑자기 디스크로 향하기 때문에 멤버가 급격하게 느려지게 함
- 하지만 데이터셋이 작고 서버에 여유 공간이 있을 경우 초기 동기화는 쉽고 좋은 방법
- 초기 동기화를 수행하면 시간이 오래 걸리는 문제가 흔히 발생
- 이때 새로운 멤버는 동기화 소스의 oplog 끝부분으로 밀려날 수 있고, 동기화 소스를 따라잡을 수 없을 정도로 뒤쳐져 버림
- 동기화 소스의 oplog는 새로운 멤버가 계속 복제해야 하는 데이터를 덮어쓰기 때문
- 문제를 해결하려면 덜 바쁜 시간에 초기 동기화를 시도하거나 백업으로부터 복원하는 방법을 사용해야 함
1.2 복제
- 몽고DB가 수행하는 두 번째 동기화 유형은 복제
- Secondary 멤버는 초기 동기화 후 지속적으로 데이터를 복제함
- 동기화 소스에서 oplog를 복사한 후 이러한 작업을 비동기 프로세스에 적용함
- Secondary는 핑 시간 및 다른 멤버의 복제 상태 변경에 따라, 필요에 따라 동기화 소스를 자동으로 변경할 수 있음
- 특정 노드가 어떤 멤버를 동기화할 수 있는지 제어하는 데는 몇 가지 규칙이 있음
- 투표수가 1인 복제 셋 멤버는 투표수가 0인 멤버와 동기화할 수 없음
- Secondary 멤버는 지연된 멤버나 숨겨진 멤버와 동기화하지 않음
1.3 실효 처리
- Secondary는 동기화 소스상에서 수행된 실제 연산들보다 훨씬 뒤떨어지면 곧 실효 상태가 됨
- 동기화 소스의 모든 연산이 실효 Secondary보다 훨씬 앞서기 때문에 실효 Secondary 소스의 모든 연산을 따라잡는 것은 불가능
- 따라서 동기화를 계속 진행하는 경우 일부 작업을 건너뛰게 되며 이는 Secondary가 다운타임 중이거나, 쓰기 요청이 처리량을 뛰어넘거나, 읽기 작업 때문에 매우 바쁠 때 발생
- Secondary가 실효 상태가 되면 복제 셋의 각 멤버로부터 차례로 복제를 시도해, 독자적으로 이행할 수 있는 긴 oplog를 갖는 멤버가 있는지 확인
- 충분히 긴 oplog를 갖는 멤버를 발견하지 못하면 해당 멤버에서 복제가 중지되고 완전히 재동기화돼야 함
- Secondary가 동기화되지 못하는 상황을 피하려면, Primary가 많은 양의 연산 이력을 보관하도록 큰 oplog를 가져야 함
- 큰 oplog는 당연히 더 많은 디스크 공간을 사용하지만 충분히 감수할 만 함
- 일반적으로 oplog는 2~3일 분량의 정상적인 연산에 대해 적용 범위를 제공해야 함
2. 하트비트
- 멤버는 복제 셋에 대한 최신 정보를 유지하기 위해 복제 셋의 모든 멤버로 2초마다 하트비트 요청을 보냄
- 하트비트 요청은 모두의 상태를 점검하는 짧은 메시지
- 하트비트의 가장 중요한 기능은 복제 셋의 과반수 도달 가능 여부를 Primary에 알리는 기능
- Primary가 더는 서버의 과반수에 도달할 수 없다면, 스스로를 강등해 Secondary가 됨
2.1 멤버 상태
멤버들은 하트비트를 통해 상태를 서로 주고받으며 Primary와 Secondary 외 멤버들이 가질 수 있는 일반적인 상태는 다음과 같습니다.
가. STARTUP
- 멤버를 처음 시작할 때의 상태로, 몽고DB가 멤버의 복제 셋 구성 정보 로드를 시도할 때 해당 상태가 됨
- 구성 정보가 로드되면 상태가 STARTUP2로 전환됨
나. STARTUP2
- 해당 상태는 초기 동기화 과정 전반에 걸쳐 지속되는데, 고자어은 일반적으로 단 몇 초 동안만 지속됨
- 복제와 선출을 다루기 위해 몇몇 쓰레드로 분리되며 다음 상태인 RECOVERING으로 변환됨
다. RECOVERING
- 멤버가 현재 올바르게 자동하지만 읽기 작업은 수행할 수 없음을 의미
- 조금 과부하 된 상태로 다양한 상황에서 나타남
- 시작 시 멤버는 여러 검사를 수행해 읽기 요청을 받아들이기 전에 유효한 상태인지 확인해야 하므로 모든 멤버는 시작하고 Secondary가 되기 전에 짧게 RECOVERING 상태를 거침
- 멤버는 조각 모음 같은 긴 연산이 진행될 때나 replSetMaintenance 명령에 대한 응답으로 REOVERING 상태가 될 수 있음
- 또한 멤버는 다른 멤버들보다 너무 많이 뒤처질 때 따라잡기 위해 RECOVERING 상태가 될 수 있음
라. ARBITER
- 아비터는 일반적인 연산 중에는 특수항 상태인 ARBITER를 유지
다음과 같이 몇몇 상태는 시스템상 문제를 나타냅니다.
가. DOWN
- 멤버가 살아 있지만 도달할 수 없는 상태
- `다운`됐다고 보고된 멤버는 사실 여전히 살아 있고 단지 네트워크 문제 때문에 도달할 수 없을 수 있음
나. UNKNOWN
- 멤버가 다른 멤버에 도달한 적이 없었다면 상태를 전혀 알 수 없으므로 UNKNOWN으로 알림
- 일반적으로 알 수 없는 멤버가 다운되거나 두 멤버 간에 네트워크 문제가 있음을 나타냄
다. REMOVED
- 멤버가 복제 셋으로부터 제거된 상태
- 제거된 멤버가 복제 셋에 다시 추가되면 `정상적인` 상태로 변환됨
라. ROLLBACK
- 멤버가 데이터를 롤백할 때 사용
- 롤백 과정 마지막에서 서버는 RECOVERING 상태로 전환되고 Secondary가 됨
3. 선출
- 멤버가 Primary에 도달하지 못하면 Primary 선출을 모색함
- 선출되고자 하는 멤버는 도달할 수 있는 모든 멤버에 알림을 보냄
- 알림을 받은 멤버는 해당 멤버가 Primary가 될 자격이 있는지 알아봄
- 해당 멤버가 복제에 뒤쳐졌거나 Primary가 이미 존재할 경우 알림을 받은 멤버들은 해당 멤버에 반대 투표함
- 반대할 이유가 없으면 멤버들은 선출되고자 하는 멤버에 투표함
- 해당 멤버가 복제 셋의 과반수로부터 득표하면 선출은 성공적으로 이루어지고 멤버는 Primary 상태로 전환됨
- 반면에 과반수로부터 득표하지 못하면 멤버는 Secondary 상태로 남으며 나중에 다시 Primary가 되려고 시도함
- Primary는 멤버의 과반수에 도달할 수 없거나, 다운되거나, Secondary로 강등되거나, 복제 셋이 재구성될 때까지는 자격을 계속 유지
4. 롤백
- 앞서 설명한 선출 과정은, Primary가 수행한 쓰기를 Secondary가 복제하기 전에 Primary가 다운되면 다음에 선출되는 Primary에 해당 쓰기가 없음을 의미
예시를 통한 설명
- 두 개의 데이터 센터가 있어, 하나는 Primary와 Secondary를 갖고 다른 하나는 세 개의 Secondary를 갖고 있고 두 데이터 센터 간에 네트워크 파티션이 존재한다고 가정했을 때 첫 번째 데이터 센터에 있는 서버들은 연산 126까지 있지만, 데이터 센터는 아직 다른 데이터 센터에 있는 서버들로 복제되지 않았음
- 다른 데이터 센터의 서버들은 여전히 복제 셋의 과반수에 도달할 수 있으며 그중 하나가 Primary로 선출될 수 있음
- 새로운 Primary는 쓰기를 수행하기 시작

- 네트워크가 복구되면 첫 번째 데이터 센터의 서버들은 다른 서버들로부터 동기화하려고 연산 126을 차지만 결국 찾지 못함
- 이런 현상이 발생하면 A와 B는 롤백이라는 과정을 시작
- 롤백은 복구 전에 복제되지 않은 연산을 원래 상태로 되돌리는 데 사용
- oplog에 126이 있는 서버들은 공통 지점을 찾으려고 다른 데이터 센터 서버들의 oplog를 살피며 일치하는 가장 최신 연산이 연산 #125 임을 발견
- A의 oplog가 123~128, B의 oplog가 123~131까지 있다고 가정
- 여기서 A의 연산 126~128와 B의 연산 126~128은 다른 연산 (B가 더 최근 작업)
- 따라서 A는 연산 126~128을 복제하기 전에 충돌이 발생했으므로 세 가지 작업을 롤백해야 함
- 이 시점에 oplog에 126이 있는 서버는, 자신이 가진 연산을 살펴보고 해당 연산으로부터 각 도큐먼트 버전을 데이터 디렉토리의 rollback 디렉토리에 있는. bson 파일에 씀
- 그러므로 만약 연산 126이 갱신 작업이었다면, 연산 126에 의해 갱신된 도큐먼트를 `컬렉션명. bson`에 씀
- 그 후 현재 Primary에서 해당 도큐먼트의 버전을 복제함
이러한 롤백 과정은 MongoDB가 데이터 일관성을 유지하고, 네트워크 장애와 같은 불가피한 상황에서도 복제 세트의 안정성을 보장하기 위한 중요한 메커니즘입니다.
4.1 롤백에 실패할 경우
- 몽고DB 4.0 이전 버전에서는 롤백이 수행되기에 너무 큰지 여부를 결정할 수 있었음
- 몽고DB 4.0부터는 롤백할 수 있는 데이터 양에 제한이 없음
- 4.0 이전 버전에서는 데이터가 300MB를 초과하거나 롤백에 시간이 30분 이상 걸리면 실패할 수 있으며 이때는 롤백에 갇힌 노드를 재동기화해야 함
- 실패하는 현상은 Secondary가 뒤쳐지고 Primary가 다운될 때 가장 흔히 발생함
- 이런 케이스에서는 Secondary 중 하나가 Primary가 되면 이전 Primary로부터 많은 연산을 놓치게 됨
- 멤버가 롤백에 갇히지 않게 하려면 Secondary를 가능한 한 최신 상태로 유지하는 것을 권장
참고
몽고DB 완벽 가이드 3판 - 한빛미디어
반응형
'DB > 몽고DB 완벽 가이드 3판' 카테고리의 다른 글
| [13장] 복제 셋 관리 (0) | 2025.04.26 |
|---|---|
| [12장] 애플리케이션에서 복제 셋 연결 (0) | 2025.04.25 |
| [10장] 복제 셋 설정 (0) | 2025.04.22 |
| [9장] 애플리케이션 설계 (0) | 2025.04.21 |
| [8장] 트랜잭션 (0) | 2025.04.16 |