1. 언제 샤딩해야 하나
- 너무 일찍 샤딩할 경우 배포 운영이 더 복잡해지며 나중에 변경이 어려운 구조에 대한 결정을 내려야 한다는 단점 존재
- 반면 너무 늦게 샤딩할 경우 과부하된 시스템을 중단 없이 샤딩하기 어렵다는 단점 존재
- 일반적으로 샤딩은 다음과 같은 경우에 사용됨
- 사용 가능한 메모리를 늘릴 때
- 사용 가능한 디스크 공간을 늘릴 때
- 서버의 부하를 줄일 때
- 한 개의 mongod가 다룰 수 있는 처리량보다 더 많이 데이터를 읽거나 쓸 때
- 따라서 샤딩이 필요한 시점을 결정하는 데 모니터링이 중요하며, 각 지표를 주의 깊게 측정해야 함
- 일반적으로 한 가지 병목 항목에 빠르게 맞닥뜨리게 되므로 어떤 항목을 프로비저닝할지 찾고, 복제 셋 전환 방법과 시기를 미리 계획하는 것을 권장
2. 서버 시작
- 클러스터를 생성하려면 먼저 필요한 프로세스를 모두 시작해야 함
- mongos와 샤드 설정
- 클러스터 구성을 저장하는 일반 mongod 서버인 구성 서버 설정 (몽고DB 3.2부터는 복제 셋을 구성 서버로 사용할 수 있음)
2.1 구성 서버
- 구성 서버는 클러스터의 두뇌부 역할 수행
- 어떤 서버가 무슨 데이터를 갖고 있는지에 대한 모든 메타 데이터를 보유하므로 구성 서버를 가장 먼저 설정해야 함
- 구성 서버에 있는 데이터는 매우 중요하므로 저널링이 활성화된 채 시리행 중이며 데이터가 영구적인 드라이브에 저장돼 있는지 확인 필요
- 운영 배포에서 구성 서버 복제 셋은 3개 이상의 멤버로 구성해야 하며 각 구성 서버는 지리적으로 분산된 별도의 물리적 장비에 있어야 함
- mongos가 구성 서버로부터 구성을 가져오므로, 구성 서버는 mongos 프로세스에 앞서 시작해야 함
- 3개의 개별 시스템에서 다음 명령을 실행해 구성 서버 시작 가능
- 이후 구성 서버를 복제 셋으로 시작하면 되고 mongo 셸을 복제 셋 멤버 중 하나에 연결
$ mongo --host <호스트명> --port <포트>
- 그리고 rs.initiate() 보조자를 사용
- 복제 셋 이름으로 configRS를 사용하며 해당 이름은 각 구성 서버를 인스턴스화할 때 명령행과 rs.initiate() 호출 모두에 나타남
- --configsvr 옵션은 mongod를 구성 서버로 사용하겠다는 뜻으로 해당 옵션으로 실행되는 서버에서 클라이언트는 config과 admin 이외의 데이터베이스에 데이털르 쓸 수 없음
- admin 데이터베이스는 인증 및 권한 부여와 관련된 컬렉션과, 내부용 기타 system.* 컬렉션을 포함
- config 데이터베이스는 샤딩된 클러스터 메타데이터를 보유하는 컬렉션을 포함
- 몽고DB는 청크 마이그레이션이나 청크 분할 후처럼 메타데이터가 변경될 때 config 데이터베이스에 데이터를 씀
- 몽고DB는 구성 서버에 쓰기를 수행할 때 writeConcern 수준의 "majoirty"를 사용하며 구성 서버에서 읽을 때는 readConcern 수준의 "majority"를 사용
- 샤딩된 클러스터 메타데이터가 롤백될 수 없을 때까지 구성 서버 복제 셋에 커밋되지 않음
- 또한 구성 서버 오류가 발생해도 살아남을 메타데이터만 읽을 수 있음
- 위 특성들은 샤드 클러스터에서 데이터가 구성되는 방식을 모든 mongos 라우터가 일관되게 보도록 하는 데 필요
- 구성 서버를 네트워킹 및 CPU 리소스 측면에서 적절하게 프로비저닝해야 함
- 구성 서버는 클러스터 내 데이터의 목차만 보유하므로, 필요한 스토리지 리소스가 최소화됨
- 시스템 리소스에 대한 경합을 방지하려면 별도의 하드웨어에 배포해야 함
2.2 mongos 프로세스
- 세 개의 구성 서버가 실행 중이면 애플리케이션이 접속할 mongos 프로세스를 시작하는데 mongos 프로세스가 구성 서버들의 위치를 알야 하므로 항상 --configdb 옵션으로 mongos 프로세스를 시작해야 함
- mongos는 기본적으로 27017로 실행하며 mongos 자체는 데이터를 보유하지 않고, 시작할 때 구성 서버로부터 클러스터 구성을 가져오기 때문에 데이터 디렉터리는 필요 없음
- 여러 샤드에 접근해야 하거나 분산/수집 작업을 수행하는 쿼리의 성능을 향상하기 위해 적은 수의 mongos 프로세스를 시작해야 하며, 가능한 한 모든 샤드에 가까이 배치하는 것을 권장
- 고가용성을 보장하기 위해서는 mongos 프로세스가 최소 두 개 필요하며 적은 수의 라우터를 사용하는 것을 권장
2.3 복제 셋으로부터 샤딩 추가
- 애플리케이션에 이미 복제 셋이 있다면 해당 셋이 첫 번째 샤드가 됨
- 복제 셋을 샤드로 전환하려면 멤버의 구성을 약간 수정한 후, mongos에게 샤드를 구성할 복제 셋을 찾는 방법을 알려야 함
- i.g. svr1.example.net, svr2.example.net, svr3.example.net에 rs0이라는 복제 셋이 있으면 먼저 mongo 셸을 사용해 멤버 중 하나에 연결함
$ mongo srv1.example.net
- 이후 rs.status()를 사용해 어떤 멤버가 프라이머리이고 어떤 멤버가 세컨더리인지 확인
- 몽고DB 3.4부터 샤드용 mongod 인스턴스는 반드시 --shardsvr 옵션으로 구성해야 하며 구성 파일 설정 sharding.clusterRole 혹은 명령행 옵션 --shardsvr을 통해 구성 가능
- 샤드로 변환하는 과정에서 복제 셋의 각 멤버에 대해 해당 작업을 수행해야 함
- 먼저 --shardsvr 옵션을 사용해 각 세컨더리를 차례로 재시작한 뒤
- 프라이머리를 단계적으로 강등하고 --shardsvr 옵션을 사용해 재시작하면 됨
- 복제 셋을 샤드로 추가했으면 애플리케이션이 복제 셋 대신에 mongos에 접속하게 할 수 있음
- 샤드를 추가할 때 mongos는 복제 셋 내 모든 데이터베이스를 해당 샤드가 `소유`한다는 것을 등록하므로, 모든 쿼리를 새로운 샤드로 전달
- mongos는 클라이언트 라이브러리처럼 애플리케이션의 장애 조치를 자동으로 처리하며, 사용자에게 오류를 전달
- 개발 환경에서 샤드의 프라이머리 장애 조치 기능을 테스트해서, 애플리케이션이 mongos로부터 받은 오류를 적절히 처리하는지 확인하는 것을 권장
2.4 용량 추가
- 용량을 추가하려면 샤드를 추가해야 함
- 복제 셋을 생성해 빈 샤드를 새로 추가하고, 기존 샤드들과 다른 이름으로 명명해야 함
- 복제 셋이 초기화되고 프라이머리를 갖게 되면, mongos를 통해 addShard 명령을 실행해 클러스터에 추가하고, 새로운 복제 셋의 이름과 호스트를 시드로 지정
- 샤드가 아닌 기존 복제 셋이 여러 개 있으면, 데이터베이스 이름이 겹치지 않는 한 클러스터에 새로운 샤드로 추가할 수 있음
2.5 데이터 샤딩
- 몽고DB는 데이터를 어떻게 분산할지 알려주기 전에는 자동으로 데이터를 분산하지 않음
- 분산하기 위해서는 분산하려는 데이터베이스와 컬렉션을 명시적으로 알려줘야 함
- i.g. music 데이터베이스의 artist 컬렉션을 "name" 키로 샤딩한다고 가정했을 때 우선 music 데이터베이스의 샤딩을 활성화해야 함
- 데이터베이스는 항상 데이터베이스 내 컬렉션보다 먼저 샤딩해야 함
> sh.enableSharding("music")
- 데이터베이스 수준에서 샤딩을 활성화하고 나면 sh.shardCollection을 실행해서 컬렉션을 샤딩할 수 있음
- 이제 artists 컬렉션은 "name" 키로 샤딩됨
- 기존 컬렉션을 샤딩하려면 "name" 필드에 인덱스가 있어야 함
- 인덱스가 없을 경우 shardCollection 호출은 오류를 반환함
- 샤딩할 컬렉션이 아직 존재하지 않으면 mongos가 자동으로 샤드 키 인덱스를 생성함
> sh.shardCollection("music.artists", {"name": 1})
- shardCollection 명령은 컬렉션을 청크로 나눔
- 명령 실행이 성공하면 몽고DB는 클러스터의 샤드에 컬렉션을 분산하며 해당 프로세스는 컬렉션이 클 경우 최초 분산을 끝내는 데 몇 시간이 걸릴 수도 있음
- 데이터를 로드하기 전에, 샤드에서 청큭가 생성될 곳을 사전 분할함으로써 시간을 줄일 수 있음
- 이 시점 이후에 로드된 데이터는 추가 밸런싱 없이 현재 샤드에 직접 삽입됨
3. 몽고DB는 어떻게 클러스터 데이터를 추적하는가
- 각 mongos는 샤드 키가 주어지면, 도큐먼트를 어디서 찾을지 항상 알아야 함
- 몽고DB는 주어진 샤드 키 범위 내에 있는 도큐먼트를 청크로 나누고
- 하나의 청크는 항상 하나의 샤드에 위치하므로 몽고DB는 샤드에 매핑된 청크의 작은 테이블을 가짐
- i.g. 사용자 컬렉션의 샤드 키가 {"age": 1}이면, 하나의 청크는 "age" 필드가 3과 17 사이인 모든 도큐먼트가 됨, mongos는 {"age": 5} 쿼리 요청을 받으면 청크([3, 17])가 있는 샤드에 쿼리를 라우팅
- 삽입을 수행하면 청크가 더 많은 도큐먼트를 포함하게 되고, 제거를 수행하면 더 적은 도큐먼트를 포함하게 되므로 쓰기가 발생하면 청크 안에 있는 도큐먼트 개수와 크기가 바뀜
- 대부분의 데이터가 하나의 샤드에 위치하게 됐을 때 데이터 분산 지점이 해결되지 않아 다소 곤란할 수 있음
- 그러므로 청크가 일정 크기까지 커지면 몽고DB는 자동으로 두 개의 작은 청크로 나눔
- 만약 범위가 겹칠 수 있다면 몽고DB는 14와 같이 중복된 나이를 찾기 위해 두 청크를 모두 확인해야 하기 때문에 [3, 15]와 [12, 17]처럼 범위가 겹치는 청크는 가질 수 없음
- 도큐먼트는 항상 단 하나의 청크에만 속하므로 배열 필드를 샤드 키로 사용할 수 없음
- 몽고DB가 배열에 여러 개의 인덱스 항목을 만들기 때문
- i.g. 어떤 도큐먼트의 "age" 필드가 [5, 26, 83]과 같은 값을 갖는다면, 해당 도큐먼트는 세 개의 청크에 속할 수도 있음
3.1 청크 범위
- 새로 샤딩된 컬렉션은 단일 청크로부터 출발하며 모든 도큐먼트는 해당 청크에 위치함
- 청크 범위는 셸에서 $minKey와 $maxKey로 표시되며, 값은 음의 무한대와 양의 무한대 사이
- 청크가 커지면 몽고DB는 자동으로 음의 무한대에서 `어떤 값`까지와 `어떤 값`에서 양의 무한대까지의 범위를 갖는 두 개의 청크로 나뉨
- 두 청크에서 `어떤 값`은 똑같음
- 하위 청크는 `어떤 값`까지의 모든 값을 포함하며, 상위 청크는 `어떤 값` 이상 값을 포함
- i.g. "age"로 샤딩했다고 가정했을 때 "age"가 3과 17 사이인 모든 도큐먼트는 하나의 청크 [3, 17]에 포함됨, 이를 나누면 두 개의 범위가 되며 한 청크는 [3, 12)이고 다른 청크는 [12, 17]이며 이때 12를 분할점이라고 지칭
- 복합 샤드 키의 경우, 샤드 범위는 두 개의 키로 정렬할 때와 동일한 방식으로 작동
- 아래 예제에서 mongos는 주어진 사용자명을 갖는 누군가가 위치한 청크를 쉽게 찾을 수 있지만 나이만 주어질 경우 mongos는 모든 청크 혹은 대부분의 청크를 확인해야 함
- 샤드 키의 후반부에 걸린 범위는 여러 청크를 가로지르기 때문에 올바른 청크에 나이로 쿼리 하려면 {"age": 1, "username": 1}과 같이 역순의 샤드 키를 사용해야 함
3.2 청크 분할
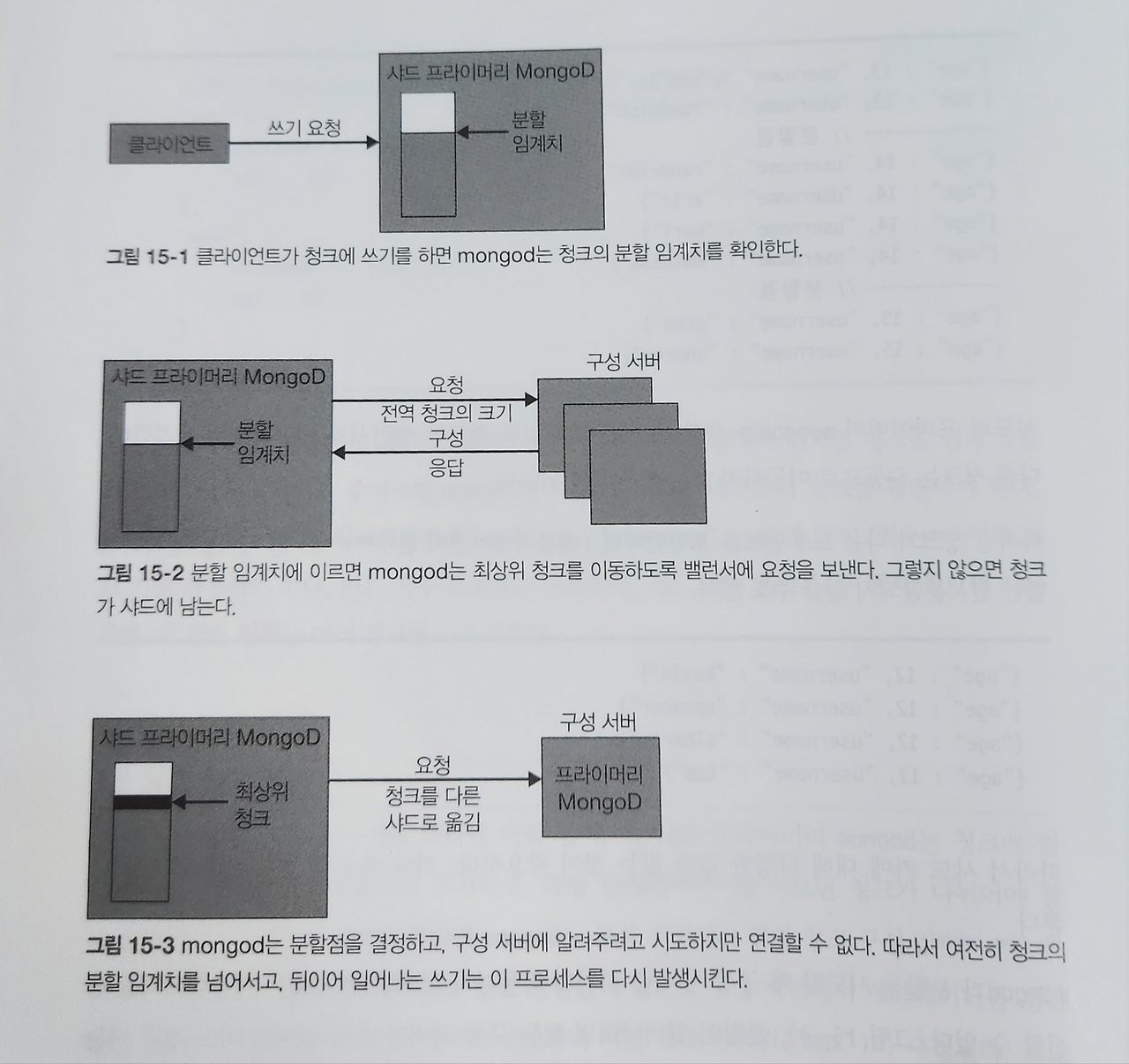
- 각 샤드 프라이머리 mongod는 청크에 얼마나 많은 데이터가 삽입됐는지 추적하고, 특정 임계치에 이르면 청크가 나뉘어야 할지 확인함
- 청크가 나뉘어야 한다면 mongod는 구성 서버에서 전역 청크 구성 값을 요청
- 그런 다음 청크 분할을 수행하고 구성 서버에서 메타데이터를 갱신
- 새 청크 도큐먼트가 구성 서버에 생성되며 이전 청크의 범위("max")가 수정됨
- 샤드 키가 단조롭게 증가하는 키를 사용하는 경우 샤드가 과부하 상태가 되는 것을 방지하기 위해 샤드의 최상위 처크인 경우 mongod는 청크를 다른 샤드로 이동하도록 밸런서에 요청
- 청크를 적합하게 분할하는 방법은 제한적이기 때문에 크기가 큰 청크인데도 샤드가 분할점을 찾지 못하는 케이스가 발생할 수 있음
- 샤드 키가 같은 두 도큐먼트는 같은 청크에 있어야 하기 때문에, 청크는 샤드 키 값이 변경되는 도큐먼트를 기준으로만 분할될 수 있음
- 샤드의 프라이머리 mongod는 분할 시 샤드의 최상위 청크만 밸런서로 이동하도록 요청
- 다른 청크는 수동으로 이동하지 않는 한 샤드에 남음
- 하지만 청크가 다음 도큐먼트를 포함한다면 분할되지 않을 수도 있음
- 따라서 샤드 키에 대해 다양한 값을 갖는 것이 중요
- mongod가 분할을 시도할 때 구성 서버 중 하나가 작동하지 않으면 mongod는 메타데이터를 갱신할 수 없음
- 분할이 일어나려면 모든 구성 서버가 살아 있어야 하고 접근 가능해야 함
- mongod가 청크에 대한 쓰기 요청을 계속 받으면, 계속해서 청크를 분할하려고 시도하다가 실패함
- 구성 서버가 정상적이지 않으면 분할은 작동하지 않으며 모든 분할 시도는 mongod 및 연관된 샤드가 느려지도록 함
- mongod가 반복적으로 청크 분할을 시도하고 실패하는 과정을 분할 소동이라고 지칭하며 분할 소동을 방지하는 유일한 방법은, 가능한 시간만큼 구성 서버가 살아 있고 정상이게 하는 것
4. 밸런서
- 밸런서는 데이터 이동을 책임지며 주기적으로 샤드 간의 불균형을 체크하다가 불균형이면 청크를 이동하기 시작함
- 몽고DB 3.4 이후 버전에서 밸런서는 구성 서버 복제 셋의 프라이머리 멤버에 있음
- 몽고DB 3.4 이전 버전에서는 각 mongos가 때때로 밸런서 역할을 수행
- 밸런서는 각 샤드의 청크 수를 모니터링하는 구성 서버 복제 셋의 프라이머리의 백그라운드 프로세스
- 샤드의 청크 수가 특정 마이그레이션 임계치에 이를 때만 활성화됨
- 일부 컬렉션이 임계치에 이르면 밸런서는 청크를 옮기기 시작함
- 과부하 된 샤드에서 청크를 선택하고, 옮기기 전에 샤드에 청크를 분할해야 하는지 질의함
- 분할해야 하면 더 적은 청크를 갖는 장비로 청크를 옮김
5. 콜레이션
- 몽고DB의 콜레이션을 이용해 문자열 비교를 위한 언어별 규칙을 지정할 수 있음
- 규칙의 예로는 대소문자와 강세 부호를 비교하는 방법이 있음
- 기본적으로 콜레이션인 컬렉션을 샤딩하는 것도 가능한데 이를 위해 컬렉션에는 접두사가 샤드 키인 인덱스가 있어야 하며 인덱스에는 {locale: "simple"} 콜레이션이 있어야 함
6. 스트림 변경
- 스트림 변경을 사용하면 애플리케이션이 데이터베이스 내 데이터의 실시간 변경 사항을 추적할 수 있음
- 스트림 변경은 컬렉션, 컬렉션 집합, 데이터베이스 또는 전체 배포상의 모든 데이터 변경에 대한 구독 메커니즘을 제공함
- 해당 기능에는 집계 프레임워크가 사용되며 이를 통해 애플리케이션은 특정 변경 사항을 필터링하거나 수신된 변경 알림을 변환할 수 있음
- 샤드 클러스터에서 모든 스트림 변경 작업은 mongos에 대해 실행해야 함
- 샤드 클러스터의 변경 사항은 전역 논리 클록을 사용해 순서대로 보관되기 때문에 변경 순서가 보장되며, 스트림 알림은 수신된 순서대로 안전하게 해석됨
- mongos는 변경 알림을 받으면 각 샤드를 살펴보고 더 최근의 변경 사항이 없는지 확인함
- 클러스터의 활동 수준과 샤드의 지리적 분포는 확인 과정의 응답 시간에 영향을 미칠 수 있는데 알림 필터를 사용하면 응답 시간을 개선할 수 있음
참고
몽고DB 완벽 가이드 3판 - 한빛미디어
반응형
'DB > 몽고DB 완벽 가이드 3판' 카테고리의 다른 글
| [17장] 샤딩 관리 (0) | 2025.05.17 |
|---|---|
| [16장] 샤드 키 선정 (0) | 2025.05.16 |
| [14장] 샤딩 소개 (0) | 2025.05.16 |
| [13장] 복제 셋 관리 (0) | 2025.04.26 |
| [12장] 애플리케이션에서 복제 셋 연결 (0) | 2025.04.25 |