1. JPA 상속 정리
1.1 JPA에서 상속이 중요한 이유
- 상속은 도메인 모델에서 공통 속성과 비즈니스 로직을 추상 클래스 또는 인터페이스로 표현할 수 있게 해 줌
- 엔티티 계층 구조를 통해 중복 코드와 설계 복잡도를 줄이고, 전략 패턴(Strategy Pattern), 방문자 패턴(Visitor Pattern) 등 행동 패턴 구현에 적합함
- 데이터 구조(속성)의 재사용보다, 메서드의 다양화에 더 적합함
- 데이터 재사용에는 컴포지션 패턴이 더 나음
1.2 상속과 전략 패턴 실전 예시
- 구독자 발송 시스템을 예로 들면 다음과 같음
- Subscriber(부모): firstName, lastName, createdOn 등 공통 속성
- EmailSubscriber, SmsSubscriber(자식): 각자 email, phoneNumber 등 추가 속성
- 서비스 계층은 Subscriber의 타입에 따라 EmailCampaignSender, SmsCampaignSender 등 알맞은 전략을 선택
- Spring DI, @Autowired List 등으로 전략 자동 매핑
- 새로운 구독자 유형이 추가되어도, 비즈니스 로직과 데이터 구조가 유연하게 확장 가능
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // 공통 속성을 갖는 추상 엔티티 | |
| @Entity | |
| @Table(name = "subscriber") | |
| @Inheritance(strategy = InheritanceType.SINGLE_TABLE) | |
| @DiscriminatorColumn(name = "type") | |
| public abstract class Subscriber { | |
| @Id | |
| @GeneratedValue(strategy = GenerationType.IDENTITY) | |
| private Long id; | |
| private String firstName; | |
| private String lastName; | |
| @Column(nullable = false) | |
| private LocalDateTime subscribedOn = LocalDateTime.now(); | |
| // getters / setters | |
| } | |
| // 이메일 구독자 | |
| @Entity | |
| @DiscriminatorValue("EMAIL") | |
| public class EmailSubscriber extends Subscriber { | |
| @Column(nullable = false) | |
| private String emailAddress; | |
| // getters / setters | |
| } | |
| // SMS 구독자 | |
| @Entity | |
| @DiscriminatorValue("SMS") | |
| public class SmsSubscriber extends Subscriber { | |
| @Column(nullable = false) | |
| private String phoneNumber; | |
| // getters / setters | |
| } | |
| // 구독자 조회용 Spring Data JPA 리포지토리 | |
| @Repository | |
| public interface SubscriberRepository extends JpaRepository<Subscriber, Long> { | |
| // 기본 CRUD 외에 필요시 메서드 추가 | |
| } | |
| // 캠페인 발송자 전략 인터페이스 | |
| public interface CampaignSender<T extends Subscriber> { | |
| /** | |
| * 이 CampaignSender가 지원하는 Subscriber 타입 | |
| */ | |
| Class<T> appliesTo(); | |
| /** | |
| * 실제 발송 로직 | |
| */ | |
| void send(String title, String message, T subscriber); | |
| } | |
| // 이메일 발송 전략 구현 | |
| @Component | |
| public class EmailCampaignSender implements CampaignSender<EmailSubscriber> { | |
| private static final Logger LOGGER = LoggerFactory.getLogger(EmailCampaignSender.class); | |
| @Override | |
| public Class<EmailSubscriber> appliesTo() { | |
| return EmailSubscriber.class; | |
| } | |
| @Override | |
| public void send(String title, String message, EmailSubscriber subscriber) { | |
| // 실제 이메일 전송 로직 대신 로그로 출력 | |
| LOGGER.info("Send Email: {} - {} to address: {}", | |
| title, message, subscriber.getEmailAddress()); | |
| } | |
| } | |
| // SMS 발송 전략 구현 | |
| @Component | |
| public class SmsCampaignSender implements CampaignSender<SmsSubscriber> { | |
| private static final Logger LOGGER = LoggerFactory.getLogger(SmsCampaignSender.class); | |
| @Override | |
| public Class<SmsSubscriber> appliesTo() { | |
| return SmsSubscriber.class; | |
| } | |
| @Override | |
| public void send(String title, String message, SmsSubscriber subscriber) { | |
| // 실제 SMS 전송 로직 대신 로그로 출력 | |
| LOGGER.info("Send SMS: {} - {} to phone number: {}", | |
| title, message, subscriber.getPhoneNumber()); | |
| } | |
| } | |
| // 캠페인 서비스 – 전략 선택 및 실행 | |
| @Service | |
| public class CampaignService { | |
| @Autowired | |
| private SubscriberRepository subscriberRepository; | |
| @Autowired | |
| private List<CampaignSender<?>> campaignSenders; | |
| private Map<Class<? extends Subscriber>, CampaignSender<?>> senderMap = new HashMap<>(); | |
| @PostConstruct | |
| @SuppressWarnings("unchecked") | |
| public void init() { | |
| // 각 CampaignSender 빈의 appliesTo() 타입과 매핑 | |
| for (CampaignSender<?> sender : campaignSenders) { | |
| senderMap.put(sender.appliesTo(), sender); | |
| } | |
| } | |
| @Transactional | |
| public void sendCampaign(String title, String message) { | |
| // DB에서 모든 구독자 조회 | |
| List<Subscriber> subscribers = subscriberRepository.findAll(); | |
| // 구독자 타입별로 적절한 전략으로 전송 | |
| for (Subscriber subscriber : subscribers) { | |
| CampaignSender<Subscriber> sender = | |
| (CampaignSender<Subscriber>) senderMap.get(subscriber.getClass()); | |
| if (sender != null) { | |
| sender.send(title, message, subscriber); | |
| } | |
| } | |
| } | |
| } | |
| // 간단한 테스트 코드 | |
| @Component | |
| public class DemoRunner implements CommandLineRunner { | |
| private final SubscriberRepository subscriberRepository; | |
| private final CampaignService campaignService; | |
| public DemoRunner(SubscriberRepository subscriberRepository, | |
| CampaignService campaignService) { | |
| this.subscriberRepository = subscriberRepository; | |
| this.campaignService = campaignService; | |
| } | |
| @Override | |
| public void run(String... args) { | |
| // 구독자 엔티티 생성 및 저장 | |
| EmailSubscriber email = new EmailSubscriber(); | |
| email.setFirstName("Vlad"); | |
| email.setLastName("Mihalcea"); | |
| email.setEmailAddress("vlad@example.com"); | |
| subscriberRepository.save(email); | |
| SmsSubscriber sms = new SmsSubscriber(); | |
| sms.setFirstName("Jane"); | |
| sms.setLastName("Doe"); | |
| sms.setPhoneNumber("010-1234-5678"); | |
| subscriberRepository.save(sms); | |
| // 캠페인 전송 | |
| campaignService.sendCampaign( | |
| "Spring Boot Rocks!", | |
| "High-Performance Java Persistence with Vlad Mihalcea"); | |
| } | |
| } |
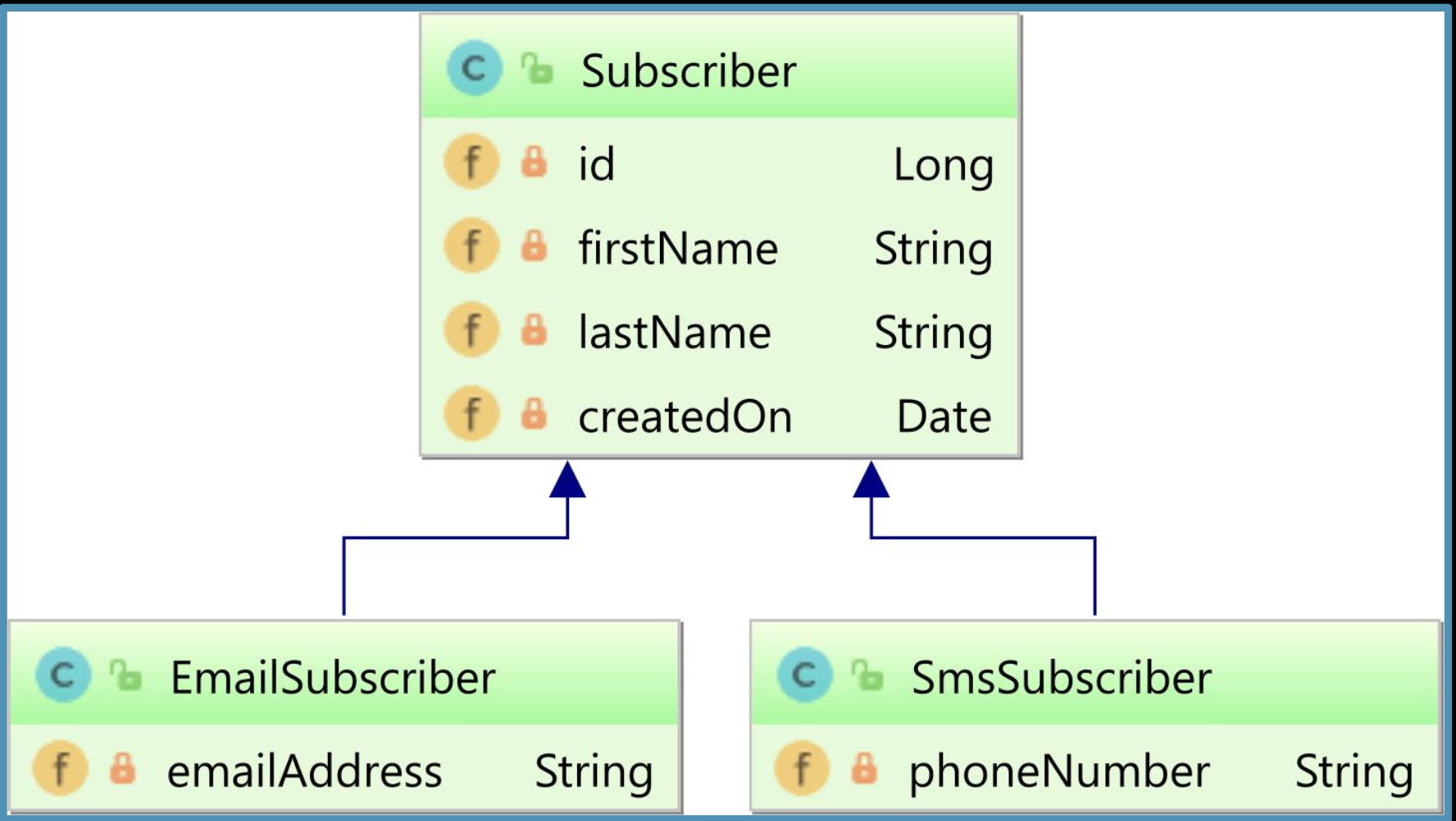
1.3 관계형 데이터베이스 내 세 가지 상속 매핑 전략
가. Single Table Inheritance
- 계층 전체를 단일 테이블에 저장
- discriminator column(구분자 컬럼)으로 실제 타입 구분
- 장점: 쿼리 단순, 조인 불필요, 성능 우수
- 단점: null 컬럼 많아지며 컬럼 관리가 불편해짐
나. Class Table Inheritance (Joined Strategy)
- 부모, 자식 각각 별도 테이블이며 PK = FK로 동등 조인
- 장점: 정규화, 데이터 무결성
- 단점: 쿼리 시 조인 필요하며 성능 저하 유발할 수 있음
다. Concrete Table Inheritance (Table Per Class)
- 각 구체 자식마다 모든 속성을 포함한 테이블 생성
- 장점: 단순하고 자식마다 독립적 테이블을 가짐
- 단점: 공통 속성이 중복되며 UNION 쿼리 필요
1.4 실무 권장사항
- 비즈니스 로직 다양화가 목적이라면 상속을 이용하고 속성 구조의 재사용이 목적이라면 컴포지션 패턴 사용하는 것을 권장
- 전략 패턴 등 유연한 서비스 구현에 상속이 매우 유용
- JPA 상속 매핑 전략은 성능, 테이블 구조, 쿼리 복잡성에 따라 신중히 선택해야 됨
- 대량 데이터/자식이 많을수록 Single Table
- 정규화·무결성이 중요하면 Joined
- 단순/테이블 독립이 필요하면 Table Per Class
- 상속계층이 DB에 반영되지 않아도 된다면, @MappedSuperclass로 추상화
- 상속은 오직 도메인 모델에서만, 테이블은 생성하지 않음
- 실질적으로 추상 클래스에서 공통 속성, 매핑, 로직만 상속받을 때 사용
2. Single Table 상속 전략
- 단일 테이블 상속은 JPA에서 상속 계층 전체를 하나의 테이블로 매핑하는 전략
- DTYPE 등 구분자 컬럼으로 실제 엔티티 타입을 구분
장점
- 단일 테이블이므로 SELECT/INSERT/UPDATE가 단순하고 빠름
- 다형성 쿼리(JPQL에서 부모 타입으로 조회, 자식 타입만 조회 등)도 SQL 한 번으로 처리 가능
- JOIN이 없으므로 I/O, 네트워크, 인덱스 비용이 최소화됨
단점
- 테이블에 모든 자식 속성이 컬럼으로 존재하므로, 어떤 행에는 특정 컬럼이 null이어야 정상적인데 서브클래스 전용 컬럼에 NOT NULL을 둘 수 없음
- 자식 클래스 전용 컬럼은 모두 NULL 허용이어야 하고, 상위 클래스 컬럼만 NOT NULL 지정 가능
- 해당 단점을 극복하기 위해 PostgreSQL에서는 CHECK 제약 조건 활용
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ALTER TABLE topic ADD CONSTRAINT post_content_check | |
| CHECK (DTYPE != 'Post' OR content IS NOT NULL); |
- 데이터 무결성(Consistency) 약화
- ACID의 Consistency 보장 측면에서 명확한 한계
- 애플리케이션/Bean Validation만으로는 불충분
2.1 실무 적용 팁 및 한계
- 하위 클래스 수가 적고, 컬럼 수가 많지 않을 때 권장
- 읽기/쓰기가 많은 OLTP 시스템에서 성능이 잘 나옴
- 하지만 하위 클래스가 많아질수록 테이블 컬럼 수가 기하급수적으로 증가하는 단점 존재
- null 컬럼이 많이 생기면 관리, 성능 및 인덱스 효율이 저하됨
- 따라서 실무에서는 하위 타입이 몇 개 안 될 때 그리고 최적의 성능이 필요할 때만 Single Table 전략을 채택하는 것을 권장
3. JPA Discriminator Column
- Discriminator 컬럼은 JPA 상속 계층 (특히 SINGLE_TABLE 전략)에서 동일 테이블 내 각 행이 어떤 구체 서브클래스 엔티티에 해당하는지 식별하는 컬럼
- 만약 해당 컬럼이 없다면, JPA/Hibernate는 각 행이 어떤 타입인지 알 수 없음
- SINGLE_TABLE 상속에서는 자동으로 DTYPE(문자열, 엔티티 이름)이 생성됨
- 명시적으로 @DiscriminatorColumn 혹은 @DiscriminatorValue 어노테이션을 선언하여 컬럼 이름, 타입, 길이, 값 등을 커스터마이징 할 수 있음
- STRING (default 값): 엔티티 이름 또는 지정 문자열
- CHAR: 한 글자 식별자
- INTEGER: 정수형 식별자
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| @DiscriminatorColumn( | |
| discriminatorType = DiscriminatorType.STRING, | |
| name = "topic_type_id", | |
| columnDefinition = "VARCHAR(3)" | |
| ) | |
| @DiscriminatorValue("TPC") |
부연 설명
- CHAR/INTEGER 타입을 사용하면 메모리 및 인덱스는 절약되지만, 실제 의미 파악이 힘듦
- i.g. 1=Post, 2=Announcement 등
- 이를 해결하기 위해 컬럼 주석을 활용하거나 별도 설명 테이블을 생성하는 방법이 있음
3.1 Discriminator 컬럼과 엔티티 저장 및 조회
- 엔티티 저장 시, 각 서브클래스별로 Discriminator 컬럼이 자동으로 채워짐
- JPQL/SQL 조회 시, Discriminator 컬럼을 WHERE 절에서 활용해 특정 타입만 필터링 가능
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT ... FROM topic t WHERE t.DTYPE = 'Post' | |
| SELECT ... FROM topic t WHERE t.topic_type_id = 'PST' |
3.2 JOINED 상속 전략에서의 Discriminator 컬럼
- JOINED 전략에서도 Discriminator 컬럼을 둘 수 있지만 필수는 아님
- Hibernate는 기본 테이블(부모)에 DTYPE 등 구분 컬럼을 두지만 서브클래스 테이블에는 별도 컬럼이 없음
- 다형성 쿼리 시 JOIN과 함께 DTYPE을 WHERE 절로 활용할 수 있음
- 만약 Discriminator 컬럼이 없으면, LEFT JOIN 결과를 기반으로 CASE 구문으로 가상 구분 컬럼을 생성해 동적으로 타입을 식별함
3.3 실무 적용 팁
- SINGLE_TABLE 상속에는 Discriminator 컬럼이 필수
- 엔티티 타입 식별, 다형성 쿼리, 성능 모두에 중요
- @DiscriminatorColumn/@DiscriminatorValue로 컬럼명, 타입, 값을 적절히 커스터마이징 하는 것을 권장
- CHAR/INTEGER 타입 사용 시에는 반드시 주석 또는 설명 테이블로 값 의미를 명확히 문서화하는 것을 권장
- JOINED 전략에서는 Discriminator 컬럼이 선택사항이지만, 다형성 쿼리의 효율성을 위해 사용하는 것을 권장
4. Joined 상속 전략
- Joined 상속은 JPA 상속 전략 중 하나로, 부모(기본) 클래스와 각 자식(서브클래스)마다 별도의 테이블을 생성함
- 각 엔티티 테이블은 상속 구조에 맞게 공통 속성은 부모 테이블에, 하위 클래스 전용 속성은 각 자식 테이블에 저장
- 각 자식 테이블의 PK는 부모 테이블의 PK와 동일함 (즉, 자식 PK는 부모 PK의 FK)
장점
- 각 테이블에 중복된 속성 없음
- 서브클래스 전용 컬럼의 null 허용을 할 필요가 없으므로 데이터 무결성 ↑
- 확장성 측면에서 우수한 전략
단점
- 엔티티 저장 시 부모 및 자식 테이블에 각각 INSERT 필요
- N개의 서브클래스가 있을 때 N + 1개 테이블을 JOIN 하므로 쿼리/인덱스/실행계획이 복잡해지고 성능 저하를 유발할 수 있음
- 각 테이블의 PK 인덱스를 유지해야 하므로 메모리 사용량 증가
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| @Entity | |
| @Inheritance(strategy = InheritanceType.JOINED) | |
| public class Topic { | |
| @Id | |
| @GeneratedValue | |
| private Long id; // 모든 공통 컬럼 | |
| private String title; // 모든 공통 컬럼 | |
| // 기타 공통 속성 | |
| } | |
| @Entity | |
| public class Post extends Topic { | |
| private String content; | |
| } | |
| @Entity | |
| public class Announcement extends Topic { | |
| private Date validUntil; | |
| } |
부연 설명
- Post/Announcement를 저장하면 부모 테이블(topic)에 한 번, 자식 테이블(post/announcement)에 한 번씩 총 2개의 INSERT 수행
- 부모 타입으로 조회할 때 각 자식 테이블을 모두 JOIN 한 뒤 CASE 구문으로 실제 타입을 구분함
4.1 실무 적용 팁
- Joined 상속 전략은 자식 클래스가 많고, 각 클래스별 구조가 많이 다르며, 다형성 쿼리가 자주 발생하지 않을 때 가장 적합함
- 다형성 쿼리가 빈번하거나, 성능이 최우선이면 SINGLE_TABLE 전략 고려
- INSERT/SELECT 시 2개 이상의 테이블에 접근/조인하므로 성능에 민감한 환경에서는 테스트 및 튜닝 필수
5. TABLE_PER_CLASS 상속 전략
- JPA 상속 전략 중 하나로, 상속 계층의 각 엔티티마다 별도의 테이블을 생성하는 전략
- 각 자식 테이블은 부모의 모든 필드와 자신의 필드를 모두 가짐 (즉, 모든 속성을 포함하며 중복된 컬럼이 존재함)
- 저장할 때마다 공통 속성 및 자식 전용 속성을 모두 별도로 삽입해야 하며 PK는 각 테이블마다 독립적으로 관리됨
- @ManyToOne, @OneToOne 등 연관관계 매핑 시, 부모 테이블 PK를 FK로 직접 참조할 수 없고 대신 각 자식 테이블 PK를 사용해야 함
- 다형성 쿼리 즉, 부모 타입으로 조회할 때는 UNION ALL 또는 UNION을 통해 여러 테이블을 합쳐 결과를 생성해야 함
- 실제 서브클래스 엔티티(자식 테이블)만 조회할 때는 효율적이지만
- 부모 타입을 통해 조회하는 다형성 쿼리는 서브클래스 수가 많아질수록 점점 느려짐
- UNION ALL 지원이 중요한데, 일부 Hibernate Dialect(Hibernate 5.4.1 미만 MySQL, MariaDB 등)는 UNION만 지원하면 정렬(중복 제거)로 인해 성능이 더 저하될 수 있음
장점
- 각 테이블이 모든 속성을 가지므로, 자식별로 NOT NULL, 제약조건 등 자유롭게 설정 가능
- 단일 테이블에만 INSERT 하므로 쓰기 성능 우수
- 데이터 정규화 및 자식별 독립성 측면에서 우수
단점
- UNION ALL/UNION 사용 시 테이블이 많아질수록 다형성 쿼리 성능 저하
- 각 테이블이 독립적으로 PK를 관리하므로 PK 및 인덱스가 중복됨
- 부모/자식 테이블 간 FK가 없어, 다형성 관계 매핑이 번거로움
5.1 실무 적용 팁
- TABLE_PER_CLASS 상속 전략은 다음과 같은 상황일 때 사용하는 것을 권장
- 계층 구조가 작고, 각 자식 간 독립성이 매우 중요할 때
- 실제 서브클래스(자식)만 자주 조회할 때
- 부모/자식 간 연관관계가 단순할 때
- 다형성 쿼리, 대규모 상속 계층, PK 충돌 방지, 쿼리 성능 등이 중요하다면 SINGLE_TABLE 또는 JOINED 전략 추천
6. @MappedSuperclass
- @MappedSuperclass는 공통 속성과 매핑을 자식 엔티티에 물려주지만, 자신은 테이블로 매핑되지 않는 추상 클래스
- 즉, DB에는 테이블이 생성되지 않지만, 하위 클래스(@Entity로 선언된 엔티티)들은 해당 슈퍼클래스의 모든 필드와 매핑을 그대로 상속받아 자신의 테이블에 컬럼으로 포함시킴
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| @MappedSuperclass | |
| public abstract class Topic { | |
| @Id | |
| private Long id; | |
| private String title; | |
| private String owner; | |
| @Temporal(TemporalType.TIMESTAMP) | |
| private Date createdOn = new Date(); | |
| } | |
| // Post, Announcement 엔티티는 Topic의 모든 속성을 물려받아 | |
| // 각자 post, announcement 테이블에 모든 컬럼을 포함 | |
| @Entity | |
| public class Post extends Topic { | |
| private String content; | |
| } | |
| @Entity | |
| public class Announcement extends Topic { | |
| private Date validUntil; | |
| } |
장점
- 쓰기/읽기 모두 단일 테이블에서 동작하므로 매우 효율적
- 공통 매핑, 연관관계, 필드 관리가 상대적으로 쉬움
- 테이블 구조 중복, PK 충돌, 다형성 쿼리 비효율 등 Table Per Class의 단점을 회피하므로 Table Per Class 전략보다 실용적
단점
- 테이블이 존재하지 않으므로 부모 타입으로 직접 쿼리 및 연관관계 매핑이 불가하고 반드시 자식 엔티티로만 사용해야 함
6.1 실무 적용 팁
- @MappedSuperclass는 다음과 같은 상황일 때 사용하는 것을 권장
- 상위 클래스를 DB 테이블로 만들 필요가 없고 공통 매핑/필드를 여러 엔티티에 물려주고 싶을 때
- 다형성 쿼리 및 연관관계 매핑이 필요 없는 경우
참고
인프런 - 고성능 JPA & Hibernate (High-Performance Java Persistence)
반응형
'DB > JPA' 카테고리의 다른 글
| [Hibernate/JPA] Statement (0) | 2025.06.04 |
|---|---|
| [Hibernate/JPA] 영속성 컨텍스트 (0) | 2025.06.04 |
| [Hibernate/JPA] 관계 (0) | 2025.06.02 |
| [Hibernate/JPA] 식별자 생성 최적화 전략 (0) | 2025.05.30 |
| [Hibernate/JPA] 타입 (0) | 2025.05.29 |