1. AI vs ML vs DL

1.1 AI (Artificial Intelligence)
- 인간의 지능을 인공적으로 구현한 기술 전체를 아우르는 광범위한 개념
- 머신러닝과 딥러닝은 AI의 세부 분야로, AI를 실현하는 구체적인 방법론에 해당
- ex) Rule-Based Algorithm
1.2 ML (Machine Learning)
- 머신러닝의 핵심은 데이터 기반으로 학습한다는 점
- 데이터 기반 방식은 규칙을 하나하나 만들 필요 없이, 수많은 데이터를 제공하여 AI가 스스로 규칙을 찾도록 유도
- 복잡한 규칙을 일일이 정의할 필요 없이, 대량의 데이터를 통해 AI가 스스로 패턴을 학습하고 분류 능력을 기를 수 있음
- 반면, 규칙 기반 알고리즘은 직접 규칙을 정의해야 함
- 데이터로 학습하는 과정이 머신러닝의 `훈련 과정`이며, 이후 `테스트 과정`을 통해 AI의 성능을 평가
- 테스트 과정의 핵심은 AI가 한 번도 본 적 없는 새로운 데이터를 사용하는 것이며 주로 `정확도`를 평가 지표로 사용
- 학습 데이터로 테스트까지 진행하면 오버 피팅 이슈가 발생할 수 있음
- 머신러닝의 학습 방식은 크게 네 가지로 나눌 수 있음
- 지도 학습
- 비지도 학습
- 자기 지도 학습
- 강화 학습
- ex) Linear Regression, Perceptron
1.3 DL (Deep Learning)
- 머신러닝의 하위 개념으로, `깊은 인공 신경망`(Deep Neural Network)를 데이터 기반으로 학습시키는 방법
- 인공 신경망은 여러 층의 인공 신경 다발로 구성된 수학적 모델
- 해당 모델에서 입력된 데이터는 여러 층을 통과하며 처리되어 최종 출력으로 변환됨
- ex) CNN, RNN, Attention, Self-Attention
2. AI가 이미지를 분류하는 방법
- 각 데이터에 해당하는 분류 정보를 숫자로 대응시키며 데이터에 대응한 숫자를 레이블이라고 지칭
- ex) 강아지 사진은 1, 고양이 사진은 0으로 대응
- 학습 과정은 앞서 언급한 레이블을 사용하여 진행되며 `AI 모델`에 수많은 사진을 반복적으로 입력하며 사진에 대응되는 레이블을 출력하도록 대규모 데이터셋을 반복적으로 학습
- AI는 모든 정보를 숫자로 처리하기 때문에 입출력 모두 숫자 형태여야 함
- 입력으로 주어진 디지털 이미지 또한 본질적으로 숫자로 이루어진 `행렬`
- 이미지에서 각 칸은 픽셀이라고 부르며, 픽셀이 가지는 값은 보통 [0, 255] 범위의 정수로 해당 위치의 밝기로 표현함
- 흑백 이미지는 1차원, 컬러 이미지는 RGB 채널 모두 가져야 하므로 3차원
- 이미지의 크기를 표기할 때 채널, 행, 열 순으로 나타내며 100 * 100 픽셀을 가지는 컬러 이미지는 3 * 100 * 100으로 표현
- 정리하자면 이미지는 숫자로 이루어진 행렬로 표현되며, AI는 주어진 대량의 이미지들을 학습하여 복잡한 시각 정보를 처리하고 학습하여 이미지 분류, 객체 인식 등 다양한 컴퓨터 비전 작업을 수행할 수 있게 됨
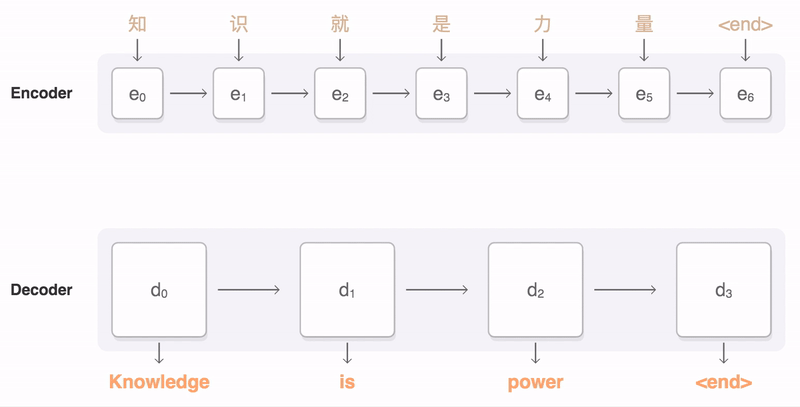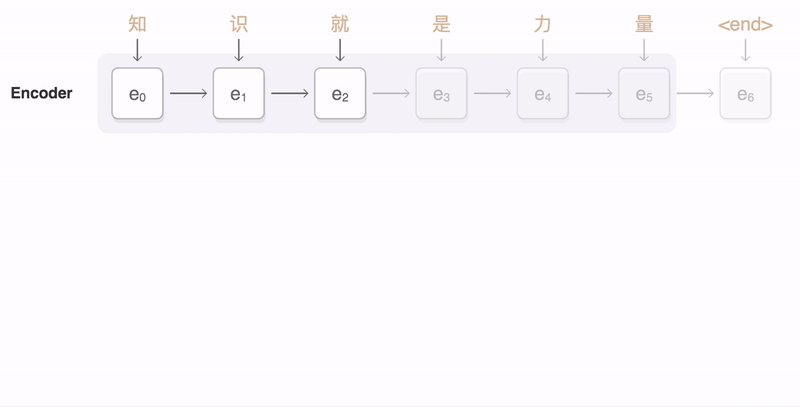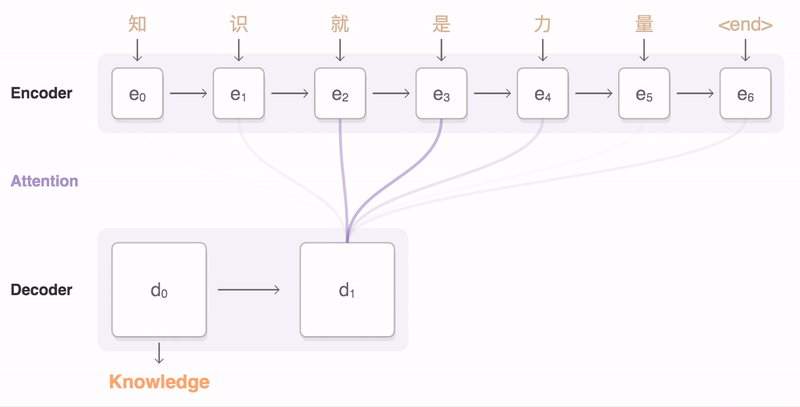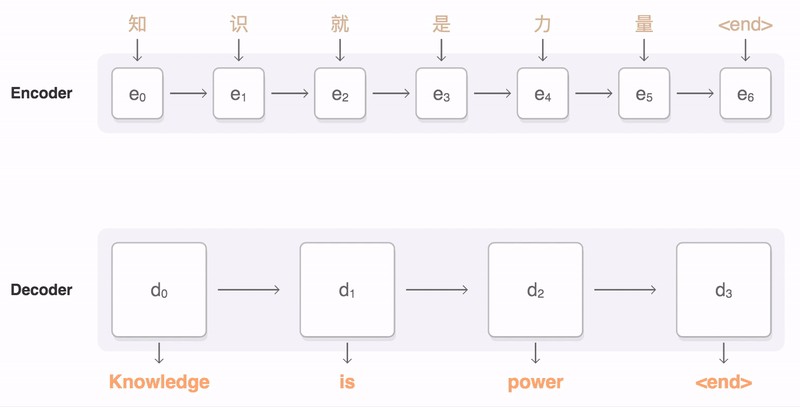
3. AI가 번역을 하는 방법
- 자연어 처리(Natural Language Processing)는 딥러닝 분야에서 이미지 처리만큼 중요한 위치를 차지하고 있으며 특히 기계 번역은 NLP의 대표적인 응용 사례로 꼽힘
- 번역 문제의 경우 하나의 데이터는 원문과 그에 대응하는 번역문으로 구성된 쌍이기 때문에 대량의 {원문, 번역문} 쌍으로 이루어진 대규모 데이터셋이 학습에 필요
- 학습 후 모델의 성능 평가는 학습에 사용되지 않은 새로운 한글 문장을 입력하여, 번역된 문장의 정확성을 확인하는 방식으로 이루어짐
- 여기까지는 이미지 분류 모델과 비슷하나 자연어 처리에는 이미지 처리와 달리 특별한 전처리 과정이 필요
- 앞서 이미지 분류 모델 설명에서 AI가 모든 정보를 숫자로 처리하기 때문에 입출력이 숫자 형태여야 한다고 언급
- 텍스트 그 자체론 숫자가 아니기 때문에 숫자 형태로 변경하기 위해 토크나이징이라는 전처리 필요
- 토크나이징은 텍스트를 적절한 단위로 나누는 작업이며 이렇게 나눈 각 토큰을 고유한 숫자에 대응시킴
- 일반적인 언어 모델은 수만에서 수십만 개의 토큰을 다룸
- 자연어 처리에서의 번역 작업은 연속적인 숫자 시퀀스를 받아 연속적인 숫자 시퀀스를 출력하는 방식으로 이루어지며 최종적으로 출력된 숫자 시퀀스를 다시 텍스트로 변환하여 최종 번역 결과를 얻게 됨
4. 지도 학습 (Supervised Learning)
- 정답을 알고 있는 상태에서 학습하는 방식
- ex) 이미지 분류, 문장 번역
- 지도 학습은 각 입력 데이터에 대한 레이블을 알고 있다는 가정 하에 입력에 대해 어떤 출력을 내야 하는지를 명확히 알고 있는 상태에서 학습을 진행시킴
- 이를 위해 사람이 직접 각 입력 데이터에 대한 정답을 부여하는 데이터 레이블링 작업이 선행되어야 함
- 데이터 레이블링은 시간 집약적인 작업이지만 학습 및 평가를 위해서는 필수적
- 학습이 완료된 후에는 모델의 실제 성능을 평가하기 위해 정답을 알려주지 않은 채로 새로운 데이터에 대한 예측 수행
- 지도 학습은 레이블의 형태에 따라 크게 회귀와 분류로 나눌 수 있음
- 회귀 (Regression): 주가와 같이 레이블이 연속적인 값인 경우
- 분류 (Classification): 동물 분류, 번역 작업과 같이 레이블이 이산적인 값인 경우
4.1 회귀와 분류가 컴퓨터 비전에서 활용되는 구체적인 사례
4.1.1 분류 (Classification)
- 이미지가 무엇을 나타내는지 하나의 클래스로 분류하는 작업
- 충분한 데이터만 있다면 N 개의 클래스를 포함하는 다중 분류도 가능
- ex) 강아지, 고양이 분류
4.1.2 위치 추정 (Localization)
- 분류와 함께 수행되며, 이미지 내 객체의 클래스를 판단하고 동시에 해당 객체의 위치를 출력
- 위치는 일반적으로 객체를 둘러싼 사각형 박스로 표현되며, 박스의 중심 좌표(x, y)와 높이(h), 너비(w)로 나타냄
- 분류 레이블과 함께 각 이미지에 대해 박스 정보에 대한 레이블링 작업도 동반되어야 하기 때문에 단순 분류보다 복잡한 작업
4.1.3 객체 탐지 (Object Detection)
- 한 이미지 내 여러 객체에 대해 분류와 위치 추정을 동시에 수행
- ex) YOLO와 같은 모델은 이미지를 그리도 나누고, 각 그리드 셀에서 분류 및 여러 개의 바운딩 박스 각각에 대한 신뢰도와 박스 정보를 예측
- 신뢰도는 0 ~ 1 사이의 값으로 그리드 셀 내 객체의 중심이 존재할 가능성과 에측된 박스가 실제 객체와 겹치는 정도를 곱한 값
4.1.4 분할 (Segmentation)
- 이미지의 모든 픽셀을 대상으로 각 픽셀이 어떤 클래스에 해당하는지 판단
- 해당 작업은 이미지의 모든 픽셀에 대해 수행되어 각 픽셀이 어떤 클래스에 속하는지를 나타내는 행렬이 출력됨
- 인스턴스 분할 (Instance Segmentation)은 같은 클래스의 객체들도 서로 구분하여 분할
- 인스턴스 분할의 경우 같은 클래스의 서로 다른 객체도 구분해야 함
- 일반적으로는 먼저 객체 탐지를 수행하여 개별 객체를 식별 후 각 객체 영역 내에서 분할 수행
4.1.5 자세 추정 (Pose Estimation)과 얼굴 랜드마크 탐지 (Facial Landmark Detection)
- 자세 추정은 사람의 주요 신체 부위의 좌표를 예측
- 얼굴 랜드마크 탐지는 얼굴의 주요 특징점의 좌표를 예측
- 위와 같은 작업들은 각 좌표에 대한 정확한 레이블링이 필요하며, 그 복잡성으로 인해 레이블 생성에 많은 시간이 소요됨
5. 자기 지도 학습 (Self-Supervised Learning)
- 지도 학습의 가장 큰 단점은 대량의 레이블링된 데이터가 필요하여 많은 비용과 시간이 소요된다는 점
- 지도 학습의 한계를 극복하기 위해 등장한 것이 자기 지도 학습
- 자기 지도 학습은 레이블이 없는 데이터로도 학습할 수 있음
- ex) Context Prediction, Constrastive Learning
- 자기 지도 학습은 일반적으로 사전 학습 (Pre-Training)과 미세 조정(Fine-Tuning)의 두 단계로 진행되며 이러한 두 단계 접근법은 레이블링 된 데이터만으로 학습한 모델보다 더 높은 성능을 얻을 수 있음
- 사전 학습 단계: 실제 풀고자 하는 진짜 문제 대신 가짜 문제를 새롭게 정의하여 해결하며 이 과정에서 레이블이 없는 데이터를 활용
- 미세 조정 단계: 레이블이 있는 데이터를 이용하여 일반적인 지도 학습 방식으로 모델 조정
- 자기 지도 학습으로 얻은 사전 학습 모델은 이미지에 대한 풍부한 정보와 지식을 갖게 되며 이러한 모델을 Downstream Task에 적용할 경우 적은 양의 레이블링 된 데이터로도 뛰어난 성능을 얻을 수 있음
- 특히 자세 추정과 같이 레이블링이 까다로워 데이터 확보가 쉽지 않은 경우에 자기 지도 학습의 장점이 더욱 부각됨
- 자연어 처리 분야에서도 자기 지도 학습이 활발히 연구되고 있으며 OpenAI의 GPT와 구글의 BERT가 대표적인 예
- GPT (Generative Pre-trained Transformer): 다음 단어를 예측 (Next Token Prediction)하는 방식으로 학습됨
- BERT (Bidirectional Encoder Representations from Transformers): 문장에 빈칸을 만들고 빈칸에 알맞은 토큰을 예측 (Masked Token Prediction)과 두 문장이 연속된 문장인지 예측 (Next Sentence Prediction)하는 방식을 동시에 사용
- 위 학습 방식에서는 텍스트 자체가 학습의 입력이자 정답이 되기 때문에 인위적인 레이블링 작업이 필요 없으며 인터넷에 존재하는 방대한 양의 텍스트 데이터를 활용하여 모델을 학습시킬 수 있음

5.1 Context Prediction
- 사전 학습 단계에서 이미지의 구조 및 객체 간 위치 관계를 학습하는 기법
- Context Prediction 과정은 다음과 같음
- 이미지에서 무작위로 위치를 선정하여 특정 크기의 파란색 패치를 배치
- 파란색 패치 주변에 동일한 크기의 패치들을 배치
- 모델이 파란색 패치와 주변 패치들의 상대적 위치 관계를 예측하도록 학습
- Context Prediction의 장점은 다음과 같음
- 레이블이 없는 데이터에도 적용 가능
- 파란색 패치의 위치를 임의로 선정할 수 있어 학습 데이터를 무한히 생성 가능
- 정리하자면 Context Prediction은 이미지의 픽셀값들이 무작위적이지 않고 일정한 패턴을 가진다는 사실을 활용한 학습 방법
- ex) 얼굴 이미지에서 눈, 코, 입이 특정 위치에 존재하고, 눈은 입 위에 위치하며, 몸통은 얼굴과 이어지고, 다리나 꼬리는 몸통에 연결되어 있다는 등의 구조적 특징을 가진다는 사실을 기반으로 학습
- 이러한 학습을 통해 모델은 이미지의 구조와 특징을 더 깊이 이해하게 되고 향후 실제 분류 작업에서 보다 나은 성능을 발휘하는 데 도움이 됨
5.2 Contrastive Learning
- 이미지 같의 관계를 학습하는 또 다른 자기 지도 학습 기법
- Contrastive Learning 과정은 다음과 같음
- 하나의 이미지에 이미지 회전, 밝기 조절, 일부 자름과 같이 서로 다른 두 가지 변형을 가함
- 변형된 이미지 쌍의 출처가 같은지 다른지를 인식하도록 모델을 학습시킴
- Contrastive Learning 과정을 통해 모델은 다음과 같은 규칙으로 학습됨
- 같은 이미지에 변형된 쌍 : 출력값을 서로 가깝게 만듦
- 서로 다른 이미지에서 변형된 쌍 : 출력값을 서로 멀어지게 만듦
- 정리하자면 출처가 같다면 당기고, 출처가 다르면 밀어내는 학습 방식으로 모델은 이미지의 고유한 특성을 파악하고, 이미지 간 유사도를 판단하는 능력을 기르게 됨
6. 비지도 학습 (Unsupervised Learning)
- 레이블이 없는 데이터에서 패턴이나 구조를 찾아내는 학습 방법
- 지도 학습과 달리 `정답`이 주어지지 않은 상태에서 데이터의 특징을 스스로 학습하는 것이 특징
- 대표적인 비지도 학습 방법으로는 군집화와 차원 축소가 있음
- 비지도 학습 (Clustering): 비슷한 특성을 가진 데이터들을 그룹으로 묶는 방법 ex) K-means Clustering, DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- 차원 축소 (Dimension Reduction): 데이터의 중요한 특성은 유지하면서 데이터의 복잡성을 줄이는 방법 ex) PCA (Principal Component Analysis), SVD (Singular Value Decomposition)

7. 강화 학습 (Reinforcement Learning)
- 특정한 행동을 강화시키는 학습 방식
- 원하는 행동 (Action)에 대해 적절한 보상 (Reward)를 줌으로써 해당 행동을 강화하는 것이 강화 학습의 핵심
- ex) 구글의 AI 바둑 기사 알파고
- 바둑에서 AI의 Action은 돌을 어디에 둘지 결정하는 것이며, 이기는 수를 뒀을 때 해당 행동을 강화하기 위해 보상을 주는 방식으로 학습을 진행
- 위와 같은 과정을 반복하면 AI는 바둑의 규칙을 이해하고 현재 바둑판 상황을 분석하여 최적의 수를 둘 수 있게 됨
- 핵심은 단순히 적절한 보상을 주는 것만으로 AI가 게임의 규칙을 스스로 깨닫고 이기는 전략을 학습한다는 것
7.1 강화 학습의 주요 개념
- Agent: 행동을 취하는 주체 ex) 오목에서의 흑돌
- Action: Agent가 취할 수 있는 모든 행동 ex) 오목에서 돌을 놓을 위치를 선택하는 행동
- Reward: Agent가 Action에 따라 받게 되는 보상 ex) 최종 보상은 승점, 중간 과정의 보상으로 돌을 연속적으로 배치했을 때 작은 보상을 주는 방식으로 강화 학습 진행
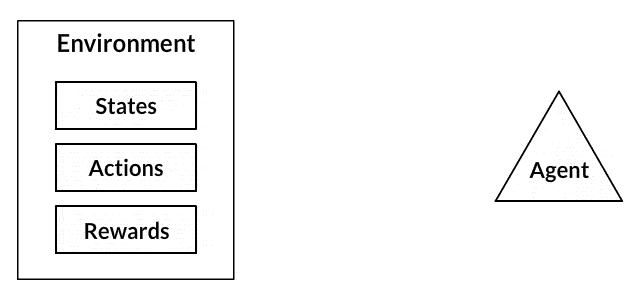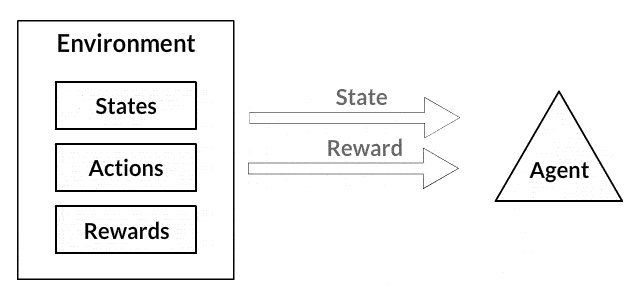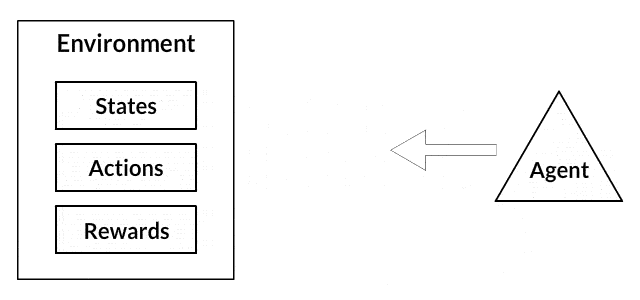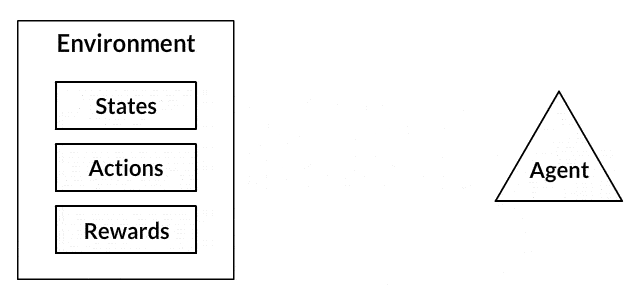
- Environment: 강화 학습이 일어나는 무대로 어떤 Action을 강화할지, 언제 어떠한 Reward를 줄지 설계된 공간 ex) 승패를 판단하는 심판과 백돌이 Environment
- State: 환경의 현재 상태를 나타내는 개념 ex) 바둑판의 돌 배치 상태와 현재 어떤 돌의 차례인지 정보
- 행동 가치 함수 Q: 특정 State에서 특정 Action을 했을 때 현재와 미래에 얻을 수 있는 Reward의 합의 기댓값
- 심층 강화 학습 (Deep Reinforcement Learning): Q 값을 딥러닝을 통해 학습
- Episode: 하나의 완전한 시행
- Q-Learning: Episode 내 수많은 Action을 수행하며 Q 값을 반복적으로 업데이트하여 최적의 행동 가치를 학습하는 방법
- Exploration: 기존에 학습하지 않은 새로운 방법을 찾는 것, 입실론 값으로 일탈의 빈도를 조정
- ex) 입실론이 0.1이라면 10%의 확률로 Q 값을 무시하고 무작위로 Action을 취함
- Discount Factor: Q 값을 현재 시점으로 가져올 때 곱하는 0과 1 사이의 값
- 1에 가까울수록 미래의 보상을 중요하게 여김
- State를 거슬러 올라갈 때마다 Q 값에 Discount Factor 감마를 곱함에 따라 목표에 멀어질수록 Q 값이 작아짐
- Q-Learning은 Exploration 전략과 Discount Factor를 활용하여 새로운 가능성을 탐색하면서도 장기적으로 최적의 해를 구할 수 있음
참고
혁펜하임의 Easy! 딥러닝
반응형
'딥러닝 > 혁펜하임의 Easy! 딥러닝' 카테고리의 다른 글
| [Chapter 6] 깊은 인공 신경망의 고질적 문제와 해결 방안 (2) | 2025.02.03 |
|---|---|
| [Chapter 5] 인공 신경망, 그 한계는 어디까지인가? (0) | 2025.02.01 |
| [Chapter 4] 이진 분류와 다중 분류 (1) | 2025.01.27 |
| [Chapter 3] 딥러닝, 그것이 알고 싶다 (0) | 2025.01.25 |
| [Chapter 2] 인공 신경망과 선형 회귀, 그리고 최적화 기법들 (1) | 2025.01.25 |