1. 인공 신경망 (Artificial Neural Network)
- 인간 뇌의 신경망 구조에서 영감을 받아 만들어졌으며
- 인공적으로 만든 신경들이 서로 연결되어 망을 이룬 형태
1.1 생물학적 신경 구조와 인공 신경의 유사성
생물학적 신경 구조는 다음과 같이 크게 세 가지 부분으로 나눌 수 있습니다.
- 수상돌기: 전기 신호를 받는 부분
- 세포체: 받은 신호를 처리하는 부분
- 축삭: 처리된 신호를 다음 신경으로 전달하는 부분
위와 같은 구조로 자극을 수용하고 해당 자극이 특정 임계값을 넘으면 다음 신경으로 신호를 전달하는 방식으로 작동합니다.

인공 신경은 위와 같은 생물학적 신경의 작동 원리를 모방합니다.
인공 신경의 작동 과정을 간단히 설명하면 다음과 같습니다.
- 여러 입력 노드로부터 자극을 받고
- 받은 자극들의 총합을 계산
- 계산된 총합을 활성화 함수에 통과시킨 뒤
- 활성화 함수의 출력값을 다음 층의 신경에 전달
1.2 활성화 함수 (Activation Function)
- 들어오는 값과 나가는 값의 관계를 나타냄
- 인공 신경이 입력 신호를 어떻게 처리하여 출력할지를 결정
- 인공 신경망의 뉴런 출력에 비선형성을 추가하여 모델이 복잡한 패턴을 학습할 수 있도록 지원
- 각 뉴런의 출력에 적용되며, 이로 인해 네트워크는 다양한 입력에 대해 다양한 출력을 생성 가능
- 신경망의 성능에 큰 영향을 미치며, 모델의 수렴 속도와 정확도에 중요한 역할을 수행하기 때문에 문제의 특성에 따라 적절한 활성화 함수를 선택하는 것이 딥러닝 모델의 성능을 최적화하는 데 필수적
- ex) Unit Step Function, Sigmoid Function, Hyperbolic Tangent, ReLU (Rectified Linear Unit), Leaky ReLU, Softmax
1.3 인공 신경의 Weight와 Bias
- 인공 신경은 노드와 엣지로 이루어져 있고, 입력된 자극의 값에 웨이트를 곱하고 바이어스와 함께 더한 다음 활성화 함수를 통과시킴
- Bias는 들어오는 값을 계산할 때 자극의 값과 함께 더해지는 값으로, 신경의 민감도를 조절하는 파라미터
- Weight는 각 자극의 중요도를 결정하는 파라미터로, 자극의 값에 곱해져 총합에 반영
- 웨이트와 바이어스 값을 적절히 부여하는 것이 인공 신경의 성능을 결정하는 데 매우 중요함
- 실제 인공 신경망에서는 웨이트와 바이어스가 수억 개에 달할 수 있어, 사람이 일일이 값을 정하는 것은 불가능하며 후술 할 알고리즘들을 통해 AI가 스스로 적절한 바이어스와 웨이트를 찾아내도록 구현해야 함
1.4 인공 신경망과 MLP (Multi-Layer Perception)
- 인공 신경망은 여러 인공 신경이 서로 연결되어 망을 이루는 구조로 본질적으로 이는 `곱하고 더하고 액티베이션하는` 과정의 연속
- 각 노드가 가진 웨이트 세트가 곧 해당 노드의 `역할`을 결정하므로 웨이트 세트가 서로 충분히 다를 때, 각 신경은 고유한 역할을 수행할 수 있음
- 이러한 다양성이 신경망의 표현력을 높이는 핵심 요소
- 노드끼리 모두 연결된 층을 Fully-Connected 레이어라고 하며
- Input, Output Layer와 더불어 Hidden Layer를 하나 이상 가지면서 모든 레이어가 Fully-Connected 레이어인 신경망을 MLP라고 지칭
- Input Layer: 입력값을 가진 노드들이 존재하는 층
- Hidden Layer: 중간에 존재하는 은닉된 층
- Output Layer: 최종 출력을 내는 층
- 히든 레이어의 개수가 많을수록 신경망은 더욱 깊어지며 히든 레이어 개수가 많은 인공 신경망을 깊은 인공 신경망이라고 지칭
- 초기에는 Unit Step Function을 사용하는 인공 신경만을 퍼셉트론이라고 불렀지만, 현재는 히든 레이어에서 비선형 액티베이션을 사용하기만 하면 MLP라고 부름
- 선형 액티베이션 (Linear Activation): f(x) = x의 형태로, 쉽게 말해 들어온 값이 그대로 나가게끔 하는 액티베이션
- 비선형 액티베이션 (Non-linear Activation): 입력에 대해 어떤 형태로든 변화를 주어 출력하는 함수라고 생각할 수 있으며 이러한 변화는 데이터를 처리하는 방식에 있어서 더 복잡하고 유연한 패턴을 학습하도록 지원
1.5 인공 신경망은 함수다
- 함수는 입력값을 처리하여 하나의 출력값에 대응시키는 것
- 인공 신경망 역시 Input Layer를 통해 입력값이 들어오고 여러 Hidden Layer를 거쳐 Output Layer에서 출력값을 얻으므로 함수라고 정의할 수 있음
- 정리하면 인공 신경망은 웨이트를 곱하고, 바이어스를 더하고, 액티베이션을 통과시키는 작은 구성 요소들이 연결된 하나의 복잡한 함수
- 따라서, AI의 학습은 수많은 데이터를 보여주면서 `해당 입력에는 해당 출력이 나와야해! 라고 반복적으로 알려주며 입력과 출력을 연결하는 최적의 함수를 찾아가는 과정`
2. 선형 회귀 (Linear Regression)
- 머신러닝의 기본적인 기법 중 하나
- 선형 회귀를 인공 신경망으로 구현하고 학습시켜 봄으로써 딥러닝의 핵심 원리를 이해할 수 있음
- 회귀란 입력과 출력 간의 관계를 알아내는 것으로 정의할 수 있음
- 입력과 출력을 연결하는 함수를 알아내는 것
- 선형 회귀는 해당 관계를 선형으로 놓고 알아내는 것으로 정의 가능
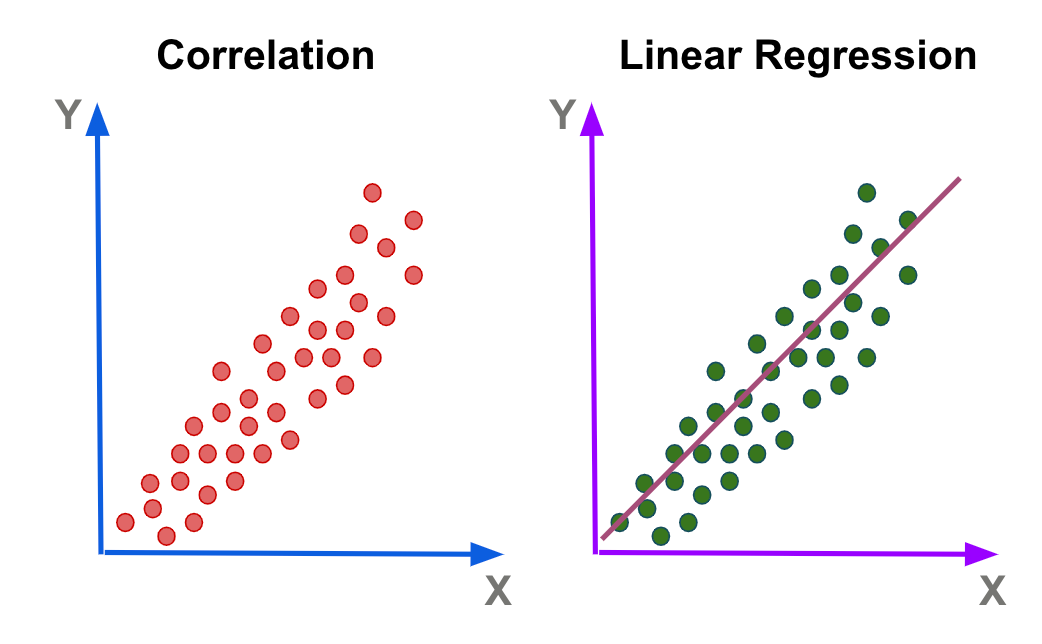
2.1 손실 함수 (Loss 함수)
- 선형 회귀의 목표는 특정 관계를 가장 잘 표현하는 직선을 찾는 것
- 간단하게 해당 직선을 y = ax + b라고 가정했을 때
- 학습 초기에는 a와 b를 무작위로 설정한 뒤
- Loss 함수를 통해 파라미터의 좋고 나쁨을 정량적으로 평가한 뒤 a와 b 값을 조정
- 위 두 과정을 반복하여 Loss 함수의 값을 최소화하는 a와 b를 찾으면 됨
- 정리하자면 Loss 함수는 해당 파라미터가 얼마나 안 좋은지를 나타내는 함수로, 이를 최소화하는 파라미터가 곧 최적의 파라미터
- 따라서, `이 입력`에는 `이 출력`이 가깝게 나올수록 Loss가 작아지도록 설계해야 함
- Loss 함수는 딥러닝 학습의 핵심 요소로 해결하고자 하는 문제의 특성에 맞게 적절히 정의해야 함
- MSE (Mean Squared Error) Loss: 예측값과 실제값 간의 차이(오차)를 제곱한 후 평균을 구한 값, 미분 가능하므로, 수학적으로 최적화하기에 유리한 특성을 지님
- MAE (Mean Absolute Error) Loss: 예측값과 실제값 간의 차이의 절대값을 평균한 값, 이상치(outlier)에 덜 민감하며, 직관적으로 해석하기 쉬움
- 복잡한 인공 신경망의 경우 파라미터 개수가 매우 많기 때문에 Loss 함수의 결과를 통해 파라미터의 값을 일일이 바꿔가며 찾는 방법을 적용하기는 현실적으로 불가능
- 위 문제를 해결하기 위해 개발된 최적화 기법들이 존재
3. 최적화 기법들
3.1 경사 하강법 (Gradient Descent)
- 경사 하강법의 작동 방식은 다음과 같음
- 파라미터 a와 b를 임의의 값으로 초기화
- 현재 위치에서 가장 가파르게 내려가는 방향을 탐색
- 해당 방향으로 한 걸음 나아감
- 새로운 위치에서 두 번째, 세 번째 과정 반복
- 최소점에 도달할 때까지 위 과정을 반복
- 현재 위치에서 가장 가파르게 내려가는 방향을 알아내는 것은 상대적으로 빠르기 때문에 a와 b를 일일이 바꿔가며 Loss 함숫값을 비교하는 것보다 훨씬 빠르게 최적의 값을 찾을 수 있음
- 경사 하강법의 핵심 역할을 하는 것은 그레디언트
- 그레디언트는 항상 함숫값이 가장 가파르게 증가하는 방향을 가리킴
- 따라서 현재 위치에서 그래디언트를 구한 뒤 그 반대 방향으로 이동하면 Loss를 줄일 수 있음
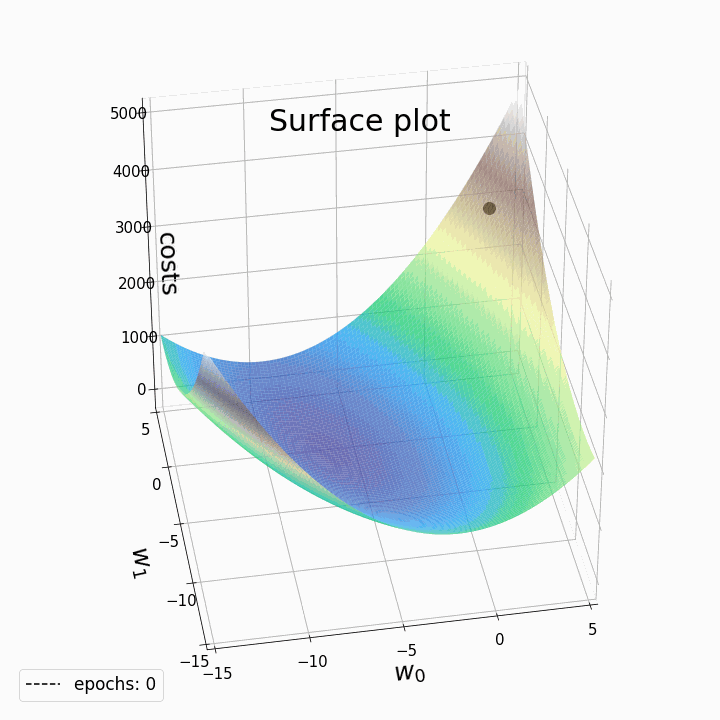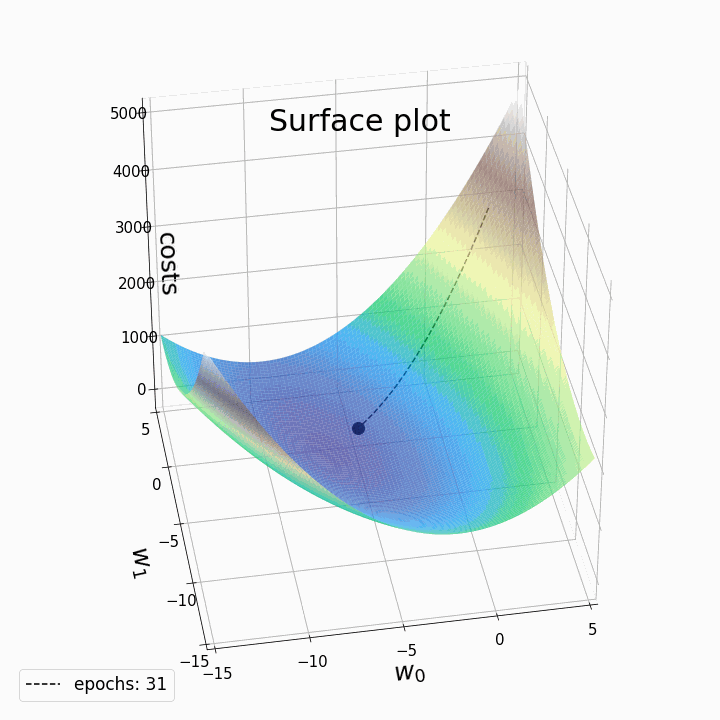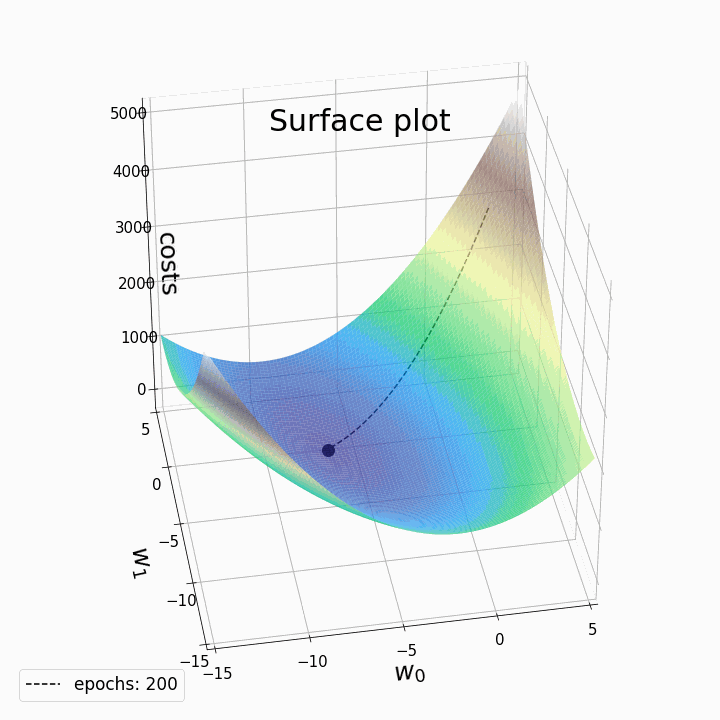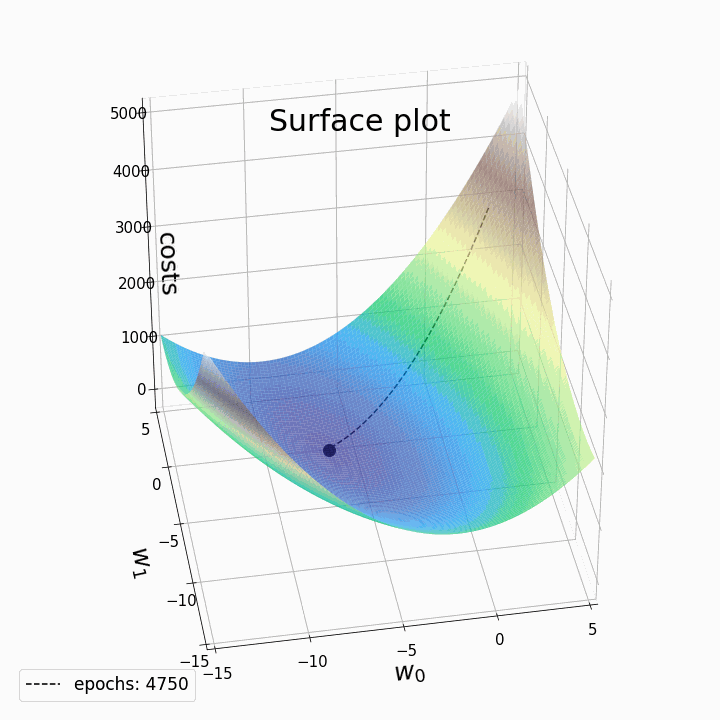
3.1.1 Learning Rate (학습률)
- 경사 하강법에서 그레디언트의 반대 방향으로 이동할 때 그 보복을 조정하는 역할
- 초기 Gradient Descent 알고리즘에서는 각 반복마다 매개변수를 얼마나 변경할지를 결정하기 위한 방법이 필요했으며 Learning Rate는 이러한 변경의 크기를 조절함으로써 효율적인 최적화를 가능
- Learning Rate가 너무 크면 최적점 근처에서 오버슈팅(over-shooting)하여 발산할 수 있고
- 너무 작으면 수렴 속도가 느려져 학습이 오래 걸릴 수 있음
- 따라서 적절한 Learning Rate를 설정하는 것이 모델의 성공적인 학습에 필수적
- 일반적으로 Learning Rate는 0.1, 0.01, 0.001 등의 값을 사용하며, 문제의 복잡도와 데이터의 특성에 따라 조정
- 많은 경우 0.01이나 0.001부터 시작하여 점진적으로 조정해 나가는 방식을 사용

3.1.2 경사 하강법의 두 가지 문제
- 경사 하강법은 효과적인 최적화 알고리즘이지만, 두 가지 주요한 문제를 지니고 있음
- 계산 속도가 여전히 느릴 수 있고
- 좋지 않은 Local Minimum에 빠질 수 있음
- 경사 하강법은 모든 파라미터를 일일이 바꿔가며 Loss 값을 관찰하는 방법보다 빠르지만, 여전히 개선의 여지는 있음
- 경사 하강법의 수식을 보면 Loss 함수가 모든 데이터를 고려하고 있음을 알 수 있으며
- 이는 데이터가 많아질수록 한 번의 파라미터 업데이트에도 상당한 시간이 소요되어 최소점에 수렴하기까지 매우 오랜 시간이 필요하게 됨
- 모든 데이터를 고려하기 때문에 매우 신중하게 방향을 설정한다고 할 수 있으나 극단적인 속도 저하를 초래하여 대규모 데이터셋에서는 현실적으로 사용이 어려워짐
- Loss 함수가 여러 개의 아래로 볼록한 형태로 가질 때 좋지 않은 Local Minimum에 빠질 수 있음
- 여러 개의 아래로 볼록한 형태를 가질 때 Loss 함수는 여러 개의 Local Minimum을 가짐
- Local Minimum은 주변의 작은 영역에서는 가장 낮은 값을 가지지만, 전체 영역에서 반드시 가장 낮은 값은 아닌 지점을 의미
- 반면, Global Minimum은 전체 영역에서 가장 낮은 값을 가지는 지점을 지칭
- 경사 하강법의 문제점은 이러한 상황에서 좋지 않은 Local Minimum에 수렴할 가능성이 크다는 점
- 파라미터의 초기값은 보통 무작위로 설정되며 무작위 위치에서 시작하여 가장 가까운 Local Minimum에 수렴할 경우 충분한 탐색이 이뤄지지 않아 좋지 않은 Local Minimum에 도달할 가능성이 높아짐
- 해당 문제점은 후술 할 확률적 경사 하강법을 통해 해결 가능

3.2 웨이트 초기화 (Weight Initialization)
- 파라미터의 초깃값이 최소점으로부터 멀리 떨어져 있을수록 최적값에 도달하기 위해 더 많은 업데이트가 필요함
- 이는 학습 시간을 늘리고 모델의 성능에 부정적인 영향을 미칠 수 있음
- 위와 같은 문제를 개선하기 위해 다양한 웨이트 초기화 방법이 소개됨
- ex) Yann Lecun 방식, Kaiming He 방식, Xavier 방식
- 앞서 소개한 세 가지 웨이트 초기화 방식은 모두 공통적으로 웨이트를 평균이 0이니 랜덤 한 값으로 초기화하며, 웨이트의 분산은 각 방식에 따라 다르게 설정
- 바이어스는 일반적으로 0으로 초기화하거나 작은 양수 값으로 초기화
- 웨이트와 달리 바이어스는 각 뉴런의 민감도를 조정하는 역할을 수행하기 때문
3.2.1 Lecun 방식, He 방식, 그리고 Xavier 방식



3.2.2 소개된 초기화 방식들이 입력 뉴런의 수와 출력 뉴런의 수를 고려하는 이유
- 입력 뉴런의 수가 크면 그만큼 많은 입력값이 각각의 웨이트와 곱해진 후 모두 더해지기 때문에 액티베이션을 통과한 인풋 값의 분산이 커짐
- 인풋 값의 분산이 지나치게 클 경우 Sigmoid와 같은 활성화 함수를 사용할 때 문제가 발생할 수 있음 (Sigmoid 함수의 경우 입력값이 매우 크거나 작으면 그레디언트가 0에 가까워져 학습이 느려지는 현상 발생)
- 위 문제점을 `기울기 소실 (Vanishing Gradeint)` 문제라고 지칭
- 기울기 소실 문제를 해결하기 위해 앞서 소개된 세 가지 초기화 방식 모두 `입력 뉴런의 수`가 클수록 분산을 작게 하여 웨이트를 0에 더 가깝게 초기화
- 이는 순전파 (Forward Propagation) 과정, 즉 입력 데이터가 신경망의 입력층에서 출력층까지 층층이 전달되며 계산되는 과정에서 분산이 급격히 커지는 것을 방지함
- Xavier 방식은 특이하게 출력 뉴런의 수까지 고려하는데 이는 역전파 (Backpropagation) 과정 때문
- 그레디언트를 계산할 때는 출력층에서 입력층 방향으로 웨이트가 곱해지고 더해지는 연산이 수행됨
- 이러한 계산 구조는 순전파 과정과 매우 유사하지만 방향이 반대라는 점이 다름
- 인풋 뉴런의 수가 커지면 순전파에서 인풋 뉴런의 수가 클 때와 마찬가지로 그레디언트 값의 분산이 커지게 됨
- 분산이 커지면 학습이 불안정하게 만들고 `그레디언트 폭발 (Exploring Gradient)` 문제를 야기할 수 있음
- Xavier 방식은 이러한 점을 고려하여 순전파와 역전파 모두에서 분산을 적절하게 유지하도록 설계됨
- 정리하자면 앞서 소개한 세 가지 초기화 방식들은 신경망의 깊이가 깊어져도 안정적으로 학습할 수 있도록 지원
- 적절한 초기화는 그레디언트 소실이나 폭발 문제를 완화하고 더 빠르고 안정적인 학습을 가능케 함
3.3 확률적 경사 하강법 (Stochastic Gradient Descent)
- 앞서 언급했듯이 확률적 경사 하강법은 경사 하강법의 한계를 개선하는 방법
- 경사 하강법은 모든 데이터를 고려하여 Loss를 계산하는 반면
- 확률적 경사 하강법은 단 하나의 데이터만을 `무작위로 선택`하여 Loss를 계산
- 확률적 경사 하강법이 진행 과정은 다음과 같음
- 초기화: 모델 파라미터를 무작위로 초기화
- 데이터 셔플링: 전체 데이터셋을 무작위로 섞음
- 무작위 하나의 데이터 포인트 선택: 하나의 데이터 샘플 선택
- 그래디언트 계산: 선택된 데이터 샘플에 대한 손실 함수의 기울기 계산
- 파라미터 업데이트: 수식 θ:=θ−α∇J(θ) 에 따라 업데이트
- 는 학습률, 는 비용 함수의 기울기
- 확률적 경사 하강법의 Loss 함수는 각 스텝마다 하나의 데이터 샘플만 고려하기 때문에 모든 데이터 샘플을 고려하는 경사 하강법보다 속도가 빠름 (앞서 언급한 한계점 #1 해결)
- 확률적 경사 하강법은 한계점 #2로 거론된 Local Minimum에 빠지는 문제를 완화할 수 있음
- 확률적 경사 하강법의 불규칙한 움직임 덕분에 경사 하강법과 달리 Global Local Minimum에 고일 가능성이 생김
- 데이터를 무작위로 선택한 순서에 따라 결과가 달라질 수 있으므로 확률적 경사 하강법은 단지 Local Minimum으로부터 `탈출할 기회를 제공한다`고 이해하는 것이 적절
- 100% 해결한다는 아님

부연 설명
- 확률적 경사 하강법은 매 스텝마다 무작위로 선택된 하나의 데이터 포인트에 대한 Loss를 최소화하는 방향으로 움직임
- 따라서 각 스텝은 해당 데이터의 '+'를 향하지만, 전체 Loss 함수의 환점에서 보면 불규칙한 경로를 그리는 것으로 보이게 됨
- 반면, 경사 하강법의 Loss 함수는 모든 데이터를 고려하기 때문에 규칙적인 경로를 그리는 것으로 보임
- 위와 같은 확률적 경사 하강법의 특성은 복잡한 Loss 지형에서 더 유연한 탐색을 가능하게 하며, 때로는 경사 하강법보다 더 좋은 해를 찾을 수 있게 해 줌
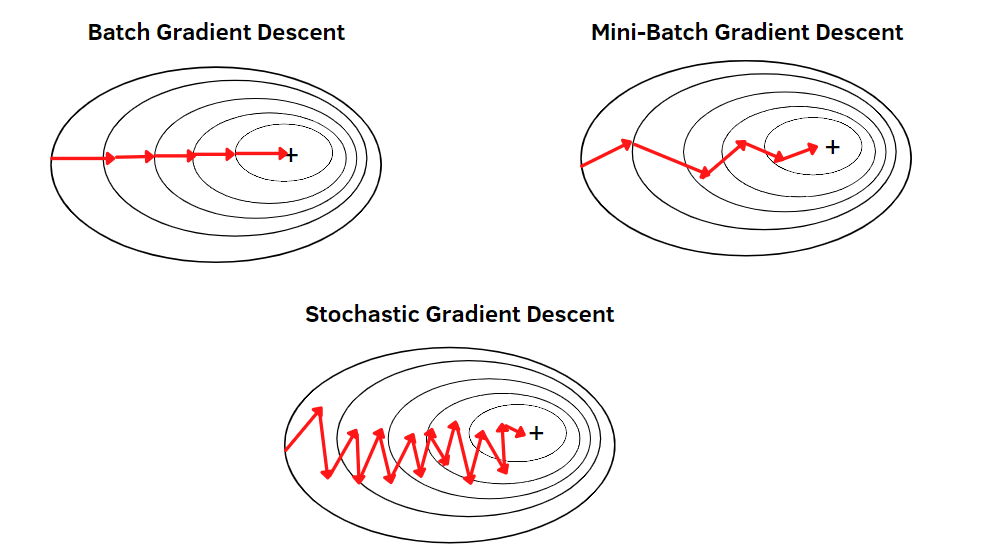
3.4 Mini-Batch Gradient Descent
- 확률적 경사 하강법의 경우 단 하나의 데이터만을 고려하기 때문에 대규모 데이터셋에서 지나치게 편향된 업데이트를 초래하는 문제점이 발생할 수 있음
- Mini-Batch GD는 위 문제를 해결하기 위해 복수의 데이터를 Loss 계산에 포함시킴
- Mini-Batch GD의 진행 과정은 다음과 같음
- 초기화: 모델 파라미터를 무작위로 초기화
- 데이터 셔플링: 전체 데이터셋을 무작위로 섞음
- 미니배치 선택: 일정 크기의 데이터 샘플 선택
- 그래디언트 계산: 선택된 미니배치에 대한 손실 함수의 기울기 계산
- 파라미터 업데이트: 수식 θ:=θ−α∇J(θ) 에 따라 업데이트
- 는 학습률, 는 비용 함수의 기울기
- 진행 과정을 보면 알 수 있다시피 Mini-Batch GD는 확률적 경사 하강법과 경사 하강법의 중간 지점에 있는 알고리즘
- Batch Size가 1이면 확률적 경사 하강법과 같고 Batch Size를 키울수록 경사 하강법에 가까워짐
- 이러한 유연성 덕분에 Mini-Batch GD는 데이터의 특성과 컴퓨팅 자원에 따라 적절히 조정하여 사용할 수 있음
- GPU를 사용하면 Mini-Batch GD의 효율성이 더욱 높아짐
- GPU는 병렬 연산이 가능하므로, 여러 데이터에 대한 계산을 동시에 수행할 수 있음
- Batch Size를 키우면 전체적인 학습 속도를 크게 향상할 수 있으나 GPU 메모리의 한계로 인해 병렬적으로 처리할 수 있는 Batch Size에는 제한이 있음
- 또한 Batch Size를 키우는 것이 항상 좋은 것이 아닌 게 Batch Size가 커질수록 경사 하강법과 가까워져 안 좋은 Local Minimum에 수렴할 가능성이 커짐
- 따라서, Batch Size 선택 시 학습 속도와 최적화 성능 사이의 균형을 고려해야 함
3.4.1 Batch Size와 Learning Rate의 조절
- 일반적인 방법에서는 Batch Size가 커질수록 에러가 증가
- 위 문제를 해결하기 위해 논문에서는 두 가지 방법을 제안
- Linear Scaling Rule: Batch Size를 키울 때 Learning Rate도 비례하여 키우는 방식
- Learning Rate Warmup: 학습 초기에 Learning Rate를 0에서 시작하여 점진적으로 증가시키는 방식
Linear Scaling Rule
- 해당 규칙은 주로 대규모 분산 학습에서 효율적으로 적용되며, 배치 크기를 k배 늘릴 때 학습률도 k배 늘려야 수렴 속도와 모델 성능이 유지된다는 경험적·이론적 근거에 기반함
- 미니배치 기법에서 그래디언트는 각 샘플마다 발생하는 오차를 평균 내어 추정
- 배치 크기가 커질수록 실제 그래디언트에 대한 추정 분산이 작아지고, 이는 학습 과정에서의 잡음을 줄여 더욱 안정적인 업데이트를 가능케 함
- 즉, 배치 크기 B가 증가하면 그래디언트 추정의 정확도가 높아지고, 그만큼 학습률을 높여 업데이트 양을 늘려도 학습이 폭주하지 않고 수렴을 유지할 수 있음
- 배치 크기가 매우 큰 경우에도 항상 완벽한 선형 스케일링이 성립하는 것은 아님
- 배치 크기가 지나치게 크면 분산 감소 효과가 한계에 도달하며, 통신 병목이나 메모리 제약 등의 물리적 요소가 추가로 작용
Learning Rate Warmup
- 학습 초기에는 파라미터가 랜덤 한 값으로 초기화되어 있어 그래디언트가 큰 경향이 있으므로, 이 시기에는 Learning Rate Warmup을 적용
- 이는 Learning Rate를 0에서 시작하여 점진적으로 목푯값까지 증가시키는 방법
- 아래 그래프는 Epoch에 따른 Learning Rate 변화를 보여주며 이와 같이 Learning Rate를 조절하는 것을 `Learning Rate Scheduling`이라고 함
- 그래프에서 볼 수 있는 `Cosine Decay`와 `Step Decay`는 각각 코사인 함수 모양과 계단 모양으로 Learning Rate를 감소시키는 방법
- 그래프 초반부의 선형적 증가 구간은 앞서 설명한 `Learning Rate Warmup` 구간

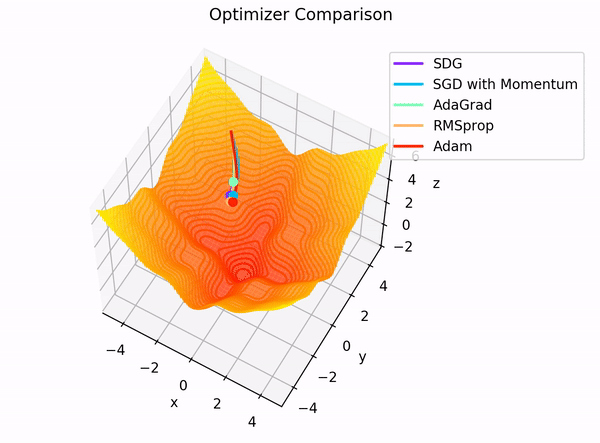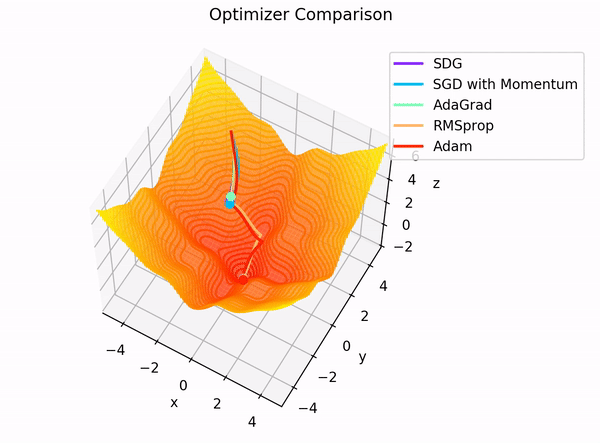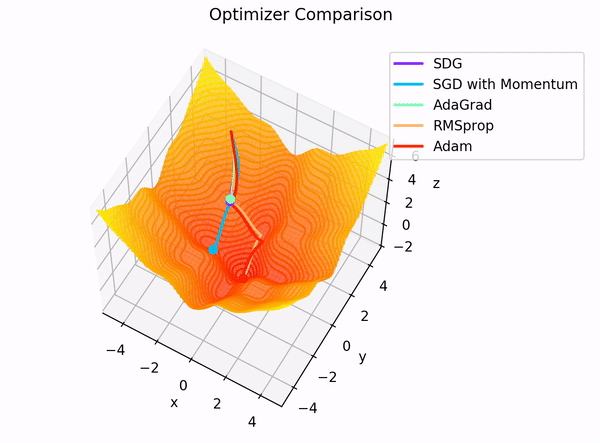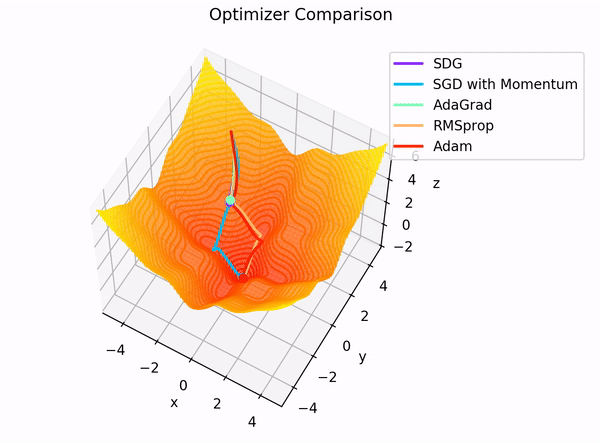
여태까지 설명한 경사 하강법, 확률적 경사 하강법, 그리고 Mini-batch 경사 하강법은 현재 시점의 그래디언트 정보만 활용하기 때문에 개선의 여지가 있습니다.
이를 더 발전시킨 방법으로 Momentum, RMSProp, 그리고 Adam이 있으며 해당 알고리즘들은 과거의 그래디언트 정보도 활용하여 더 효과적인 학습을 수행합니다.
3.5 Momentum
- 경사 하강법, 확률적 경사 하강법, 그리고 Mini-Batch 경사 하강법은 특정 상황, 특히 Loss 함수의 등고선이 타원형일 때 효율적인 학습에 어려움을 겪을 수 있음
- 경사 하강법에서는 그래디언트가 항상 등고선에 수직 하기 때문에 최저점을 향해 지그재그로 움직임
- 확률적 경사 하강법이나 Mini-Batch 경사 하강법도 비슷한 패턴을 보일 수 있는데, 이는 전체 데이터의 Loss 함수 등고선이 타원형이라면 개별 데이터나 Mini-Batch의 등고선도 유사한 형태일 가능성이 높기 때문
- 위 문제를 해결하기 위해 고안된 Momentum은 이전 그래디언트들을 누적하여 현재의 이동 방향을 결정
- 물리학의 `관성` 개념과 유사
- Momentum의 작동 원리는 다음과 같음
- 첫 번째 이동: 경사 하강법과 동일한 방향으로 이동
- 두 번째 이동: 현재와 이전 그래디언트를 합산하여 방향 결정
- 세 번째 이동: 현재 그래디언트가 한쪽을 가리켜도 직전의 반대 방향으로 이동하던 관성이 남아 한쪽으로의 이동이 제한됨
- 이후 이동: 위 과정이 반복되면서 좌우 움직임은 상쇄되지만, 최저점을 향한 방향으로의 움직임은 누적됨
- 정리하면 Momentum은 불필요한 좌우 진동을 줄이며 최저점을 향해 더 빠르고 직접적으로 나아가며 이로 인해 최저점으로의 수렴이 더 빨라짐
- 때로는 관성으로 인해 최저점을 약간 지나칠 수 있지만, 전체적으로 보다 효율적인 학습이 가능해짐
- Momentum 방식은 경사 하강법뿐만 아니라 확률적 경사 하강법, Mini-Batch 경사 하강법에도 적용할 수 있어 다양한 최적화 상황에서 학습 효율을 크게 높일 수 있음

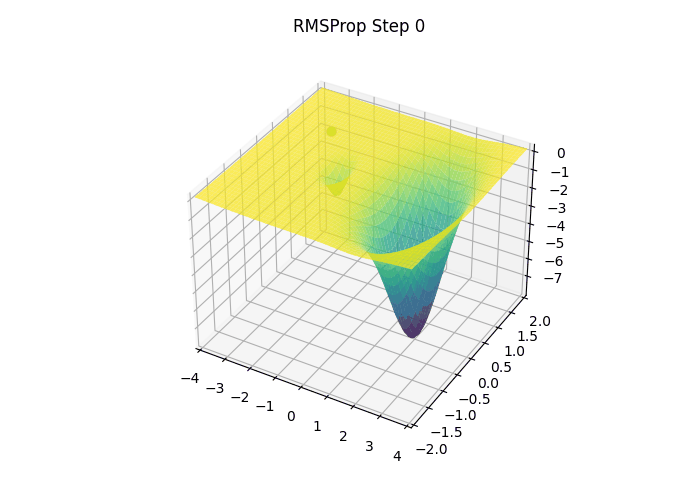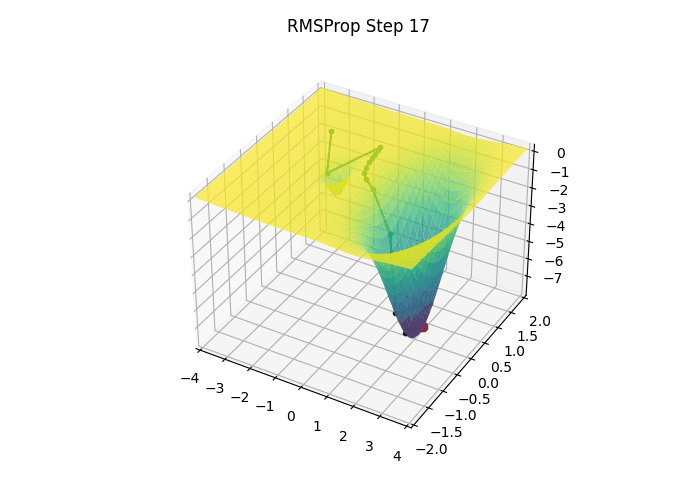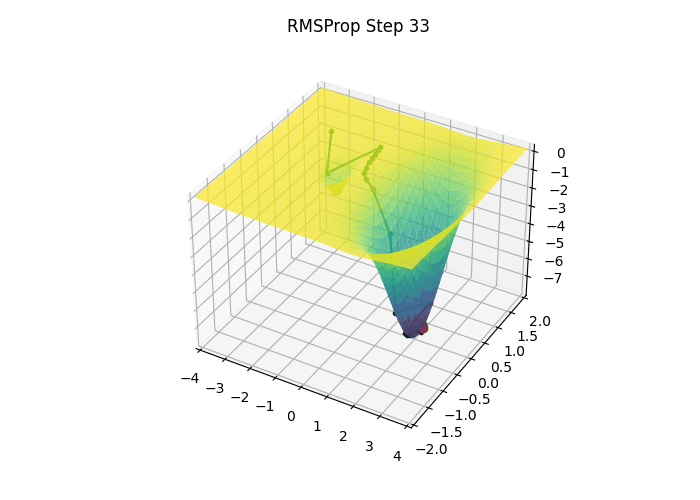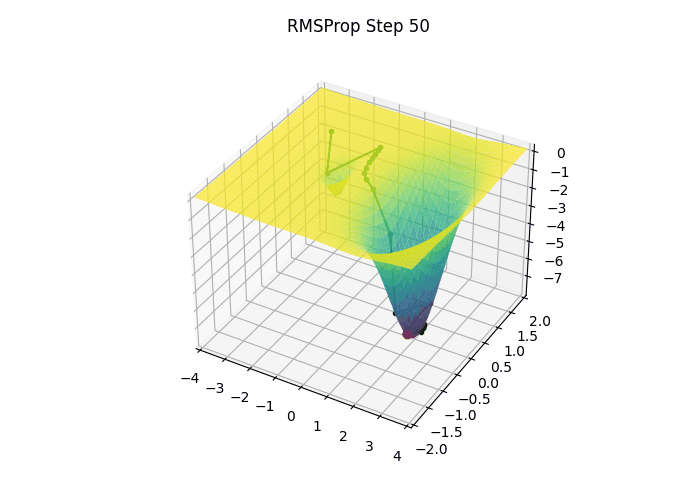
3.6 RMSProp (Root Mean Squared Propagation)
- Momentum이 이전 그래디언트를 더해서 누적했던 것과 달리 RMSProp은 각 파라미터에 대한 편미분값을 제곱하여 누적시킴
- RMSProp의 이름을 보면 과정을 잘 이해할 수 있음
- Root: 제곱근을 취함
- Mean: 누적할 때 이동 평균을 사용
- Squared: 편미분값을 제곱
- Propagation: 위 과정을 계속 진행
- RMSProp은 최근 기울기(gradient)의 제곱을 지수 이동 평균(Exponential Moving Average) 형태로 추적하여, 파라미터마다 다른 크기의 학습률을 적용하고 이를 통해, 기울기가 크게 변동하는 축에서는 업데이트 크기를 작게 하고, 기울기가 안정적인 축에서는 더 크게 업데이트하여 빠르고 안정적인 수렴을 유도
- 위 과정을 통해 RMSProp은 방향마다 다른 크기의 학습률을 적용함으로써, 최적점 근방에서 불필요한 진동을 줄이고 빠르게 수렴할 수 있으며 이는 단순 SGD나 모멘텀 기반 방법에서 관찰되는 학습률 설정의 어려움을 상당 부분 해결해 주어, 깊은 신경망 모델을 안정적으로 학습시키는 데 유용한 기법으로 널리 사용
- ex) 파라미터가 두 개고 첫 이동 방향이 [0.1, 10] 이었다면, RMSProp을 적용한 후에는 대략 [1, 1] 로 수정됨
- 이는 마치 가파른 축으로는 조심스럽게, 완만한 축으로는 과감하게 이동하는 효과를 냄
- RMSProp의 장점은 얕고 가파른 부분과 깊고 완만한 부분을 동시에 가지고 있는 복잡한 Loss 함수 지형에서 잘 드러남
- 가파른 부분은 작은 이동으로도 Loss 값이 크게 변하는 부분으로, 많이 이동하면 최저점을 지나칠 수 있기 때문에 조심스럽게 이동하여 급격한 변화를 방지함
- 완만한 부분은 Loss의 변화가 크지 않는 부분으로, 더 많이 이동해도 안전하기 때문에 과감하게 이동하여 평평한 영역을 빠르게 탈출할 수 있게 함
| import numpy as np | |
| import matplotlib.pyplot as plt | |
| from mpl_toolkits.mplot3d import Axes3D | |
| import imageio | |
| # ----------------------------- | |
| # 1. RMSProp 하이퍼파라미터 | |
| # ----------------------------- | |
| eta = 0.3 # 학습률(learning rate)을 크게 | |
| rho = 0.9 # RMSProp 지수 이동 평균 계수 | |
| epsilon = 1e-8 # 분모 0 방지 | |
| num_iterations = 50 | |
| # ----------------------------- | |
| # 2. Loss 함수 및 기울기 정의 | |
| # ----------------------------- | |
| def f(x, y): | |
| """ | |
| (x=-1, y=0) 주변: 얕고 좁은 로컬 미니멈 | |
| (x= 2, y=0) 주변: 훨씬 깊고 완만한 글로벌 미니멈 | |
| f(x, y) = 0.01*(x^2 + y^2) | |
| - 1.5 * exp(-10*((x+1)^2 + y^2)) | |
| - 8.0 * exp(-1*((x-2)^2 + y^2)) | |
| """ | |
| return ( | |
| 0.01*(x**2 + y**2) | |
| - 1.5*np.exp(-10.0*((x+1.0)**2 + y**2)) | |
| - 8.0*np.exp(-1.0*((x-2.0)**2 + y**2)) | |
| ) | |
| def grad_f(x, y): | |
| """ | |
| f(x, y)의 기울기. | |
| """ | |
| term_local = np.exp(-10.0*((x+1.0)**2 + y**2)) # 로컬 미니멈 담당(좁고 얕게) | |
| term_global = np.exp(-1.0*((x-2.0)**2 + y**2)) # 글로벌 미니멈 담당(깊고 완만) | |
| # f(x, y) = 0.01(x^2 + y^2) | |
| # - 1.5 * term_local | |
| # - 8.0 * term_global | |
| # d/dx[0.01*(x^2 + y^2)] = 0.02*x | |
| # d/dx[-1.5 * term_local] = -1.5 * term_local * [ -10 * 2(x+1) ] | |
| # = +30.0*(x+1)*term_local | |
| # d/dx[-8.0 * term_global] = +16.0*(x-2.0)*term_global | |
| grad_x = ( | |
| 0.02*x | |
| + 30.0*(x+1.0)*term_local | |
| + 16.0*(x-2.0)*term_global | |
| ) | |
| # d/dy[0.01*(x^2 + y^2)] = 0.02*y | |
| # d/dy[-1.5 * term_local] = +30.0*y*term_local | |
| # d/dy[-8.0 * term_global] = +16.0*y*term_global | |
| grad_y = ( | |
| 0.02*y | |
| + 30.0*y*term_local | |
| + 16.0*y*term_global | |
| ) | |
| return np.array([grad_x, grad_y]) | |
| # ----------------------------- | |
| # 3. 초깃값: 더 높은 곳에서 시작 | |
| # ----------------------------- | |
| np.random.seed(42) | |
| # 대략 x in [-2.5, -2.0], y in [-1.0, 1.0] 정도 범위 | |
| x_current = np.random.uniform(-2.5, -2.0) | |
| y_current = np.random.uniform(-1.0, 1.0) | |
| v = np.zeros(2) # RMSProp 기울기 제곱 추적 | |
| positions = [(x_current, y_current)] | |
| # ----------------------------- | |
| # 4. RMSProp 반복 업데이트 | |
| # ----------------------------- | |
| for i in range(num_iterations): | |
| g = grad_f(x_current, y_current) | |
| # v <- rho*v + (1-rho)*g^2 | |
| v = rho*v + (1.0 - rho)*(g**2) | |
| # 파라미터 업데이트 | |
| # x <- x - (eta / sqrt(v_x + epsilon)) * g_x | |
| # y <- y - (eta / sqrt(v_y + epsilon)) * g_y | |
| x_current -= (eta / np.sqrt(v[0] + epsilon)) * g[0] | |
| y_current -= (eta / np.sqrt(v[1] + epsilon)) * g[1] | |
| positions.append((x_current, y_current)) | |
| # ----------------------------- | |
| # 5. 3차원 표면 데이터 | |
| # ----------------------------- | |
| X = np.linspace(-4, 4, 300) | |
| Y = np.linspace(-2, 2, 200) | |
| XX, YY = np.meshgrid(X, Y) | |
| ZZ = f(XX, YY) | |
| # ----------------------------- | |
| # 6. 3D 그래프 + 경로 애니메이션 | |
| # ----------------------------- | |
| frames = [] | |
| fig = plt.figure(figsize=(7,5)) | |
| path_x = [p[0] for p in positions] | |
| path_y = [p[1] for p in positions] | |
| path_z = [f(px, py) for px, py in zip(path_x, path_y)] | |
| for i in range(len(positions)): | |
| ax = fig.add_subplot(111, projection='3d') | |
| ax.clear() | |
| # 3D 표면 | |
| surf = ax.plot_surface( | |
| XX, YY, ZZ, | |
| rstride=5, cstride=5, | |
| cmap='viridis', alpha=0.75 | |
| ) | |
| # 지나온 RMSProp 경로 (초록색) | |
| ax.plot(path_x[:i+1], path_y[:i+1], path_z[:i+1], | |
| color='green', marker='o', markersize=3) | |
| # 현재 위치 (빨간 점) | |
| ax.scatter(path_x[i], path_y[i], path_z[i], | |
| color='red', s=40) | |
| ax.set_title(f"RMSProp Step {i}", pad=20) | |
| ax.set_xlim(-4, 4) | |
| ax.set_ylim(-2, 2) | |
| ax.set_zlim(np.min(ZZ), np.max(ZZ)) | |
| ax.view_init(elev=35, azim=-60) # 시야 각도 | |
| fig.canvas.draw() | |
| image = np.frombuffer(fig.canvas.tostring_rgb(), dtype='uint8') | |
| image = image.reshape(fig.canvas.get_width_height()[::-1] + (3,)) | |
| frames.append(image.copy()) | |
| plt.clf() | |
| plt.close(fig) | |
| # GIF 생성 | |
| imageio.mimsave('rmsprop_escape_global.gif', frames, fps=5) | |
| print("rmsprop_escape_global.gif 생성 완료!") |
3.7 Adam (Adaptive Moment Estimation)
- Adam은 딥러닝 모델 학습에서 자주 사용되는 최적화 알고리즘 중 하나로, 확률적 경사하강법(SGD)에 모멘텀과 RMSProp의 장점을 결합한 기법
- 과거 기울기를 활용한 관성 효과(모멘텀)와, 현재 기울기의 제곱에 대한 가중 이동 평균을 통한 적응형 학습률(RMSProp)을 동시에 적용
- 이를 통해 학습 초기에는 빠르게 내려가면서도, 최적점 근방에서 적절히 학습률을 줄여 안정적으로 수렴하는 특징을 가짐
- 기존 파라미터 업데이트 수식은 다음과 같았음: θ:=θ−α∇J(θ)
- Adam은 기본적으로 확률적 경사하강법(SGD)의 “θ := θ − α∇J(θ)” 공식을 변형해, 1차 모멘트(모멘텀)와 2차 모멘트(기울기 제곱에 대한 지수 이동 평균)를 모두 추적하고, 이를 통해 학습률을 좌표별로 조절
- 단순히 기울기만 사용하는 것이 아니라, 적응형 스케일링과 바이어스 보정 단계를 거친 모멘텀( m̂ᵗ )을 사용한다는 점에서 크게 달라짐

부연 설명
- m̂ᵗ 는 편향 보정된 Momentum, (v^t)^(1/2) + ϵ 는 편향 보정된 RMSProp을 반영한 항
- 모멘텀은 그래디언트의 지수 이동 평균 (Exponential Moving Average)을 통해 구하는 것을 확인할 수 있으며 과거의 그래디언트 정보가 지수적으로 감소하여 누적되는 것을 볼 수 있음
- 이는 실제 관성과 유사하게, 오래된 시점의 이동 방향이 점점 잊히는 효과를 나타냄
- RMSProp 부분 또한 모멘텀과 마찬가지로 EMA를 이용하여 누적하는 것을 확인할 수 있으며 이렇게 계산된 값에 제곱근을 취해 분모에 넣음으로써 가파른 경사에서는 천천히, 완만한 경사에서는 빠르게 이동하도록 함
- 또, 0으로 나누는 것과 분모가 0에 가까워 이동하는 보폭이 크게 튀는 문제를 방지하기 위해 작은 양수 입실론이 분모에 추가됨
- Adam은 mt와 vt에 대해 바이어스 보정을 수행하는데 보정이 필요한 이유는 다음과 같음
- 보정된 추정치의 기댓값 E[mt]이 실제 그래디언트의 기댓값 E[gt]와 유사해지도록 만드는 것이 핵심 아이디어
- 이를 통해 학습 초기부터 그래디언트 추이를 더욱 잘 따라갈 수 있게 됨
- vt에 대해서도 동일한 원리로 보정이 이루어짐
정리하면 Adam은 Momentum의 `관성` 효과와 RMSProp의 적응적 이동 방향 조정을 모두 활용하면서, 학습 초반의 편향 문제도 해결하기 때문에 결과적으로 Adam은 다양한 최적화 문제에서 안정적이고 효율적인 성능을 보여줍니다.
4. 검증 데이터
- 이전 챕터를 복습하자면 모델은 훈련 데이터로 학습하고, 처음 보는 데이터인 테스트 데이터로 최종 성능이 평가됨
- 여기서 핵심은 AI의 진정한 목표가 훈련 데이터가 아닌 테스트 데이터에서 좋은 성능을 보인다는 점
- 테스트 성능이 실제 상황에서의 성능을 나타냄

- 하지만 여기서 딜레마가 발생함
- 테스트 데이터를 학습 과정에 사용하면 실제 상황에서의 성능을 알 수 없지만
- 훈련 데이터만으로는 언제 학습을 멈춰야 할지 판단하기 어려움
- 위 그래프처럼 반복 학습할수록 Loss는 점점 줄어들다가 결국 수렴하지만 이것만으로는 최적의 학습 중단 시점을 결정하기 어려움

- 앞선 딜레마에 답하기 위해 테스트 데이터의 Loss를 함께 살펴보면 위 그래프처럼 흥미로운 현상이 나타남
- 초기에는 Test Loss도 감소하지만, 어느 순간부터 다시 증가하기 시작
- 이는 모델이 훈련 데이터에 과도하게 맞춰져 일반화 능력을 잃는 Overfitting 현상 때문
- 띠리사 그래프에 표시된 Optimal Training Point에서 학습을 멈추는 것이 이상적으로 보이지만 해당 방법에도 문제가 있음
- 테스트 데이터를 기준으로 학습을 조정할 경우 해당 테스트 데이터에 Overfitting 된 모델을 얻게 될 수 있기 때문
- 위 딜레마를 해결하기 위해 등장한 것이 바로 검증 데이터 (Validation Data)
- 검증 데이터는 훈련 데이터의 일부를 떼어내 만듦
- 이를 통해 총 Epoch 수, batch Size 등의 하이퍼파라미터를 조정할 수 있음
- 검증 데이터에 대한 Loss는 Test Loss와 유사한 그래프 개형을 보이기 때문에 Test Loss가 아닌 Val Loss가 최소가 되는 시점에서 학습을 멈추는 것이 총 Epoch 수를 결정하는 적절한 방법
4.1 K-fold 교차 검증 (K-fold Cross Validation)
- 데이터가 부족할 때는 검증 데이터를 더 효과적으로 활용하기 위해 교차 검증을 사용하며 이 중 가장 널리 사용되는 기법이 K-fold 교차 검증
- K-fold 교차 검증은 데이터를 K 개의 그룹으로 나누어 각기 다른 훈련, 검증 데이터 쌍을 만드는 방식
- K개의 서로 다른 훈련/검증 데이터 조합을 만들고, 각 조합에 대해 Loss를 구한 후 평균을 산출
- 해당 평균 Val Loss를 기준으로 하이퍼파라미터를 선정할 경우 편향 문제를 줄일 수 있음
- 다만, 해당 방식은 K배만큼의 추가 학습 시간이 소요됨

참고
혁펜하임의 Easy! 딥러닝
'딥러닝 > 혁펜하임의 Easy! 딥러닝' 카테고리의 다른 글
| [Chapter 6] 깊은 인공 신경망의 고질적 문제와 해결 방안 (2) | 2025.02.03 |
|---|---|
| [Chapter 5] 인공 신경망, 그 한계는 어디까지인가? (0) | 2025.02.01 |
| [Chapter 4] 이진 분류와 다중 분류 (1) | 2025.01.27 |
| [Chapter 3] 딥러닝, 그것이 알고 싶다 (0) | 2025.01.25 |
| [Chapter 1] 개념 정리 (2) | 2025.01.22 |