객체지향 쿼리 소개
- EntityManager.find() 메서드를 사용하면 식별자로 엔티티 하나를 조회 가능
- 이렇게 조회한 엔티티에 객체 그래프 탐색을 사용하면 연관된 엔티티들을 찾을 수 있음
- 식별자로 조회: EntityManager.find()
- 객체 그래프 탐색: i.g. member.getTeam()
- 하지만 이 기능만으로는 애플리케이션을 개발하기 어려움
- ex) 나이가 30살 이상인 회원을 모두 검색하고 싶을 때 좀 더 현실적이고 복잡한 검색 방법 필요
- 데이터는 DB에 있으므로 SQL로 필요한 내용을 최대한 걸러서 조회해야 하는데 ORM을 사용하면 DB 테이블이 아닌 엔티티 객체를 대상으로 개발하므로 검색도 테이블이 아닌 엔티티 객체를 대상으로 하는 방법이 필요
- JPQL은 위와 같은 문제를 해결하기 위해 만들어졌으며 특징은 다음과 같음
- 테이블이 아닌 객체를 대상으로 검색하는 객체지향 쿼리
- SQL을 추상화해서 특정 데이터베이스 SQL에 의존하지 않음
- JPA는 JPQL 뿐만 아니라 다양한 검색 방법을 제공하며 JPA가 공식적으로 지원하는 기능은 다음과 같음
- JPQL (Java Persistence Query Language)
- Criteria Query: JPQL을 편하게 작성하도록 지원하는 API, 빌더 클래스 모음
- Native SQL: JPA에서 JPQL 대신 직접 SQL을 사용할 수 있음
- JPA가 공식 지원하는 기능은 아니지만 알아둘 가치가 있는 기능들은 다음과 같음
- QueryDSL: Criteria Query처럼 JPQL을 편하게 작성하도록 도와주는 빌더 클래스 모음, 비표준 오픈소스 프레임워크
- JDBC 직접 사용: MyBatis 같은 SQL 매퍼 프레임워크 사용, 필요하면 JDBC 직접 사용 가능
1. JPQL 소개
- 엔티티 객체를 조회하는 객체지향 쿼리로 문법은 SQL과 비슷하며 ANSI 표준 SQL이 제공하는 기능을 유사하게 지원함
- JPQL은 SQL을 추상화하기 때문에 특정 데이터베이스에 의존하지 않음
- 데이터베이스 Dialect만 변경하면 JPQL을 수정하지 않아도 자연스럽게 데이터베이스 변경 가능
- JPQL은 엔티티 직접 조회, 묵시적 조인, 그리고 다형성 지원을 제공하므로 SQL보다 코드가 간결함
| @Entity | |
| public class Member { | |
| @Column(name = "name") | |
| private String username; | |
| // 중략 | |
| } | |
| public List<Member> getMembersWithLastNameKim() { | |
| String jpql = "SELECT m FROM Member AS m WHERE m.username = 'kim'"; | |
| List<Member> resultList = em.createQuery(jpql, Member.class).getResultList(); | |
| return resultList; | |
| } | |
| /** | |
| JPQL | |
| SELECT m FROM Member AS m WHERE m.username = 'kim' | |
| 실제 실행된 SQL | |
| SELECT | |
| member.id as id, | |
| member.age as age, | |
| member.team_id as team, | |
| member.name as name | |
| FROM | |
| Member member | |
| WHERE | |
| member.name = 'kim' | |
| **/ |
부연 설명
- JPQL에서 Member는 엔티티 이름이며 m.username은 테이블 컬럼명이 아니라 엔티티 객체의 필드명
- em.createQuery() 메서드에 실행할 JPQL과 반환할 엔티티의 클래스 타입인 Member.class를 넘겨주고 getResultList() 메서드를 실행하면 JPA는 JPQL을 SQL로 변환해서 데이터베이스를 조회하며 조회한 결과로 Member 엔티티를 생성해서 반환함
2. Criteria 쿼리 소개
- JPQL을 생성하는 빌더 클래스
- Criteria의 장점은 문자가 아닌 `query.select(m).where(...)`처럼 프로그래밍 코드로 JPQL을 작성할 수 있다는 점
- Criteria는 문자가 아닌 코드로 JPQL을 작성하므로 컴파일 시점에 오류를 발견할 수 있음
- 문자로 작성한 JPQL보다 코드로 작성한 Criteria의 장점은 다음과 같음
- 컴파일 시점에 오류를 발견할 수 있음
- IDE를 사용하면 코드 자동완성 기능 지원
- 동적 쿼리 작성 용이
- Criteria 가 가진 장점이 많지만 모든 장점을 상쇄할 정도로 복잡하고 장황하다는 단점이 있음
- 사용하기 불편한 건 물론이고 Criteria가 작성한 코드도 한눈에 들어오지 않음
| public void getMemberNameWithKim() { | |
| // Criteria 사용 준비 | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| CriteriaQuery<Member> query = cb.createQuery(Member.class); | |
| // 루트 클래스 (조회를 시작할 클래스) | |
| Root<Member> m = query.from(Member.class); | |
| // 쿼리 생성 | |
| CriteriaQuery<Member> cq = query.select(m).where(cb.equal(m.get("username"), "kim")); | |
| List<Member> resultList = em.createQuery(cq).getResultList(); | |
| } |
부연 설명
- 쿼리를 문자가 아닌 코드로 작성했지만 아쉽게도 m.get("username")을 보면 필드 명을 문자로 작성
- 이 부분도 문자가 아닌 코드로 작성하고 싶을 경우 MetaModel을 사용하면 됨
- 자바가 제공하는 어노테이션 프로세서 기능을 사용하면 어노테이션을 분석해서 클래스를 생성할 수 있는데 JPA는 해당 기능을 사용해서 Member 엔티티 클래스로부터 Member_라는 Criteria 전용 클래스를 생성하는데 이것을 메타 모델이라고 함
- 메타 모델을 사용하면 m.get("username")을 m.get(Member_.username)으로 변경 가능
3. QueryDSL 소개
- QueryDSL도 Criteria처럼 JPQL 빌더 역할을 수행
- QueryDSL은 코드 기반이면서 단순하고 사용하기 쉬운 것이 장점
- 작성한 코드도 JPQL과 비슷해서 한눈에 들어오는 것 또한 장점
| public List<Member> getMembersWithLastNameKim() { | |
| // 준비 | |
| JPQQuery query = new JPAQuery(em); | |
| QMember member = QMember.member; | |
| // 쿼리 결과 조회 | |
| List<Member> members = query.from(member) | |
| .where(member.username.eq("kim")) | |
| .list(member); | |
| return members; | |
| } |
부연 설명
- QueryDSL도 어노테이션 프로세서를 사용해서 쿼리 전용 클래스를 만들어야 함
- QMember는 Member 엔티티 클래스를 기반으로 생성한 QueryDSL 쿼리 전용 클래스
4. Native SQL 소개
- JPA는 SQL을 직접 사용할 수 있는 기능을 지원하는 이 것을 네이티브 SQL이라고 부름
- JPQL을 사용해도 가끔은 특정 데이터베이스에 의존하는 기능을 사용해야 할 때가 있음
- ex) Oracle 데이터베이스만 사용하는 CONNECT BY 기능이나 특정 데이터베이스에서만 동작하는 SQL 힌트 같은 것
- 예시로 든 기능들은 전혀 표준화되어 있지 않으므로 JPQL에서 사용할 수 없음
- 또한, SQL은 지원하지만 JPQL이 지원하지 않는 기능도 있으며 이 때는 네이티브 SQL을 사용하면 됨
- 네이티브 SQL의 단점은 특정 데이터베이스에 의존하는 SQL을 작성해야한다는 것
- 멀티 테넌시를 지원하는 프로젝트에서는 지양해야 함
| public List<Member> getMembersWithUsernameKim() { | |
| String sql = "SELECT ID, AGE, TEAM_ID, NAME FROM MEMBER WHERE NAME = 'kim'"; | |
| List<Member> resultList = em.createNativeQuery(sql, Member.class).getResultList(); | |
| return resultList; | |
| } |
5. JDBC 직접 사용, MyBatis 같은 SQL 매퍼 프레임워크 사용
- 드문 케이스지만 JDBC 커넥션에 직접 접근하고 싶을 때 JPA는 JDBC 커넥션을 획득하는 API를 제공하지 않기 때문에 JPA 구현체가 제공하는 방법을 사용해야 함
| Session session = entityManager.unwrap(Session.class); | |
| session.doWork(new Work) { | |
| @Override | |
| public void execute(Connection connection) throws SQLException { | |
| // work | |
| } | |
| } |
부연 설명
- 먼저 JPA EntityManager에서 hibernate Session을 구한 뒤 Session의 doWork() 메서드를 호출
- JDBC나 MyBatis를 JPA와 함께 사용하면 영속성 컨텍스트를 적절한 시점에 강제로 flush 해야 함
- JDBC를 직접 사용하든 MyBatis 같은 SQL 매퍼와 사용하든 모두 JPA를 우회해서 데이터베이스에 접근
- 문제는 JPA를 우회하는 SQL에 대해서는 JPA가 전혀 인식하지 못한다는 점
- 최악의 시나리오는 영속성 컨텍스트와 데이터베이스를 불일치 상태로 ㅁ나들어 데이터 무결성을 훼손시킬 수 있음
- 이런 이슈를 해결하는 방법은 JPA를 우회해서 SQL을 실행하기 직전에 영속성 컨텍스트를 수동으로 flush 해서 데이터베이스와 영속성 컨텍스트를 동기화하면 됨
- 스프링 프레임워크를 사용하면 JPA와 MyBatis를 손쉽게 통합할 수 있으며 AOP를 적절히 활용하면 JPA를 우회하여 데이터베이스에 접근하는 메서드를 호출할 때마다 영속성 컨텍스트를 flush 해서 상기 언급한 문제도 깔끔하게 해결 가능
JPQL
JPQL의 특징을 복습하면 다음과 같습니다.
- JPQL은 객체지향 쿼리 언어이기 때문에 테이블을 대상으로 쿼리하는 것이 아니라 엔티티 객체를 대상으로 쿼리함
- JPQL은 SQL을 추상화해서 특정 데이터베이스 SQL에 의존하지 않음
- JPQL은 결국 SQL로 변환됨
JPQL의 이해를 돕기 위해 다음 도메인 모델을 예제로 사용하겠습니다.
- 회원이 상품을 주문하는 다대다 관계
- address는 임베디드 타입 즉, 값 타입이므로 UML에서 스테레오 타입을 사용해 <<Value>>로 정의함

1. 기본 문법과 쿼리 API
- JPQL도 SQL과 비슷하게 SELECT, UPDATE, 그리고 DELETE 문을 사용할 수 있음
- 엔티티를 저장할 때는 EntityManager.persist() 메서드를 사용하면 되므로 INSERT 문은 없음
| select_문 :: = | |
| select_절 | |
| from_절 | |
| [where_절] | |
| [groupby_절] | |
| [having_절] | |
| [orderby_절] | |
| update_문 :: = update_절 [where_절] | |
| delete_문 :: = delete_절 [where_절] |
1.1 SELECT 문
SELECT 문은 다음과 같이 사용됩니다.
- SELECT m FROM Member AS m WHERE m.username = 'kim'
대소문자 구분
- 엔티티와 속성은 대소문자를 구분함
- ex) Member, username은 대소문자를 구분
- 반면 SELECT, FROM, AS 같은 JPQL 키워드는 대소문자를 구분하지 않음
엔티티 이름
- JPQL에서 사용한 Member는 클래스 명이 아니라 엔티티 명
별칭은 필수
- Member As m을 보면 Member에 m이라는 별칭을 준 것을 알 수 있음
- JPQL은 별칭을 필수로 사용해야 함
- `SELECT username FROM Member m` 은 잘 못된 문법
- `SELECT m.username FROM Member m` 처럼 사용해야 함
1.2 TypeQuery, Query
- 작성한 JPQL을 실행하려면 쿼리 객체를 만들어야 함
- 쿼리 객체는 TypeQuery와 Query가 있는데 반환할 타입을 명확하게 지정할 수 있는지 여부에 따라 선택
- TypeQuery는 반환할 타입을 명확하게 지정할 수 있을 때 사용
- Query는 반환할 타입을 명확하게 지정할 수 없을 때 사용
| // 조회 대상 타입이 명확하게 Member | |
| TypeQuery<Member> query = em.createQuery("SELECT m FROM Member m", Member.class); | |
| List<Member> resultList = query.getResultList(); | |
| for (Member member : resultList) { | |
| log.info("member = {}", member); | |
| } | |
| // 조회 대상 타입이 명확하지 않음 | |
| Query query = em.createQuery("SELECT m.username, m.age FROM Member m"); | |
| List resultList = query.getResultList(); | |
| for (Object o : resultList) { | |
| Object[] result = (Object[]) o; // 결과가 둘 이상이면 Object[] 반환 | |
| log.info("username = {}", result[0]); | |
| log.info("age = {}", result[1]); | |
| } |
1.3 결과 조회
다음 메서드들을 호출하면 실제 쿼리를 실행해서 데이터베이스를 조회합니다.
- query.getResultList(): 결과를 List로 반환하며 만약 결과가 없으면 빈 컬렉션을 반환
- query.getSingleResultList: 결과가 정확히 하나일 때 사용 (정확히 하나가 아닐 때 예외 발생)
2. 파라미터 바인딩
JDBC는 위치 기준 파라미터 바인딩만 지원하는 반면, JPQL은 이름 기준 파라미터 바인딩도 지원합니다.
2.1 이름 기준 파라미터 (Named Parameters)
- 이름 기준 파라미터는 파라미터를 이름으로 구분하는 방법
- 이름 기준 파라미터는 앞에 :를 사용
| String usernameParam = "User1"; | |
| TypeQuery<Member> query = em.createQuery("SELECT m FROM Member m WHERE m.username = :username", Member.class); | |
| query.setParameter("username", usernameParam); | |
| List<Member> resultList = query.getResultList(); |
2.2 위치 기준 파라미터 (Positional Parameters)
- 위치 기준 파라미터를 사용하면 ? 다음에 위치 값을 주면 됨
- 위치 값은 1부터 시작
| List<Member> members = em.createQuery("SELECT m FROM Member m WHERE m.username = ?1", Member.class) | |
| .setParameter(1, usernameParam) | |
| .getResultList(); |
두 바인딩 중 이름 기준 파라미터 바인딩 방식을 사용하는 것이 명확합니다.
3. 프로젝션
- SELECT 절에 조회할 대상을 지정하는 것을 프로젝션이라 하고 `[SELECT {프로젝션 대상} FROM]`으로 대상을 선택
- 프로젝션 대상은 엔티티, 엠비디드 타입, 그리고 스칼라 타입이 있음
- 스칼라 타입은 숫자, 문자 등 기본 데이터 타입을 의미
3.1 엔티티 프로젝션
- 아래 에제에서 처음은 회원을 조회했고 두 번째는 회원과 연관된 팀을 조회했는데 둘 다 엔티티를 프로젝션 대상으로 사용
- 원하는 객체를 바로 조회한 것인데 컬럼을 하나하나 나열해서 조회해야 하는 SQL과는 차이가 있으며 이렇게 조회한 엔티티는 영속성 컨텍스트에서 관리됨
| SELECT m FROM Member m // 회원 | |
| SELECT m.team FROM Member m // 팀 |
3.2 임베디드 타입 프로젝션
- JPQL에서 임베디드 타입은 엔티티와 거의 비슷하게 사용됨
- 임베디드 타입은 조회의 시작점이 될 수 없다는 제약이 있음
- 임베디드 타입은 엔티티 타입이 아닌 값 타입이므로 직접 조회한 임베디드 타입은 영속성 컨텍스트에서 관리되지 않음
| // 임베디드 타입을 시작점으로 사용해서 잘 못된 쿼리 | |
| String query = "SELECT a FROM Address a"; | |
| // 올바른 쿼리 | |
| String query = "SELECT o.address FROM Order o"; | |
| // SELECT order.city, order.street, order.zipcode FROM Orders orders | |
| List<Address> addresses = em.createQuery(query, Address.class) | |
| .getResultList(); |
3.3 스칼라 타입 프로젝션
- 앞서 설명했다시피 숫자, 문자, 날짜와 같은 기본 데이터 타이비들을 스칼라 타입이라고 부름
| // 전체 회원들의 이름을 조회하는 쿼리 | |
| List<String> usernames = em.createQuery("SELECT username FROM Member m", String.class) | |
| .getResultList(); | |
| // 통계 쿼리도 주로 스칼라 타입으로 조회 | |
| Double orderAmountAvg = em.createQuery("SELECT AVG(o.orderAmount) FROM Order o", Double.class) | |
| .getSingleResult(); |
3.4 여러 값 조회
- 엔티티 대상으로 조회하면 편리하지만 꼭 필요한 데이터들만 선택해서 조회해야 하는 케이스도 있음
- 프로젝션에 여러 값을 선택하면 조회 대상 타입이 명확하지 않으므로 TypeQuery를 사용할 수 없고 대신에 Query를 사용해야 함
| List<Object[]> resultList = em.createQuery("SELECT m.username, m.age FROM Member m") | |
| .getResultList(); | |
| for (Object[] row : resultList) { | |
| String username = (String) row[0]; | |
| Integer age = (Integer) row[1]; | |
| } |
3.5 NEW 명령어
- 앞선 예제에서 여러 값을 조회할 때 username과 age 필드를 프로젝션 해서 타입을 지정할 수 없으므로 TypeQuery를 사용할 수 없었음
- 이에 따라 Object[]를 반환받았는데 실무에서는 Object []를 직접 사용하지 않고 UserDTO처럼 의미 있는 객체로 변환해서 사용하는 것을 권장
- New 명령어를 사용할 때는 다음 두 가지 사항을 주의해야 함
- 패키지 명을 포함한 전체 클래스 명을 입력해야 함
- 순서와 타입이 일치하는 생성자가 필요함
| public List<UserDTO> getUsers() { | |
| TypeQuery<UserDTO> query | |
| = em.createQuery("SELECT new com.tistory.jaimemin.UserDTO(m.username, m.age) FROM Member m", UserDTO.class); | |
| return query.getResultList(); | |
| } | |
| public class UserDTO { | |
| private String username; | |
| private int age; | |
| public UserDTO(String username, int age) { | |
| this.username = username; | |
| this.age = age; | |
| } | |
| } |
4. 페이징 API
JPA는 페이징을 다음 두 API로 추상화했습니다.
- setFirstResult(int startPosition): 조회 시작 위치 (0부터 시작)
- setMaxResults(int maxResult): 조회할 데이터 수
| TypeQuery<Member> query | |
| = em.createQuery("SELECT m FROM Member m ORDER BY m.username DESC", Member.class); | |
| query.setFirstResult(10); | |
| query.setMaxResults(20); | |
| query.getResultList(); |
부연 설명
- 0-index이므로 11번째부터 시작해서 총 20건의 데이터를 조회 (11 ~ 30번 데이터 조회)
5. 집합과 정렬
- 집합은 집합함수와 함께 통계 정보를 구할 때 사용
| SELECT | |
| COUNT(m), // 회원수 | |
| SUM(m.age), // 나이 합 | |
| AVG(m.age), // 평균 나이 | |
| MAX(m.age), // 최대 나이 | |
| MIN(m.age), // 최소 나이 | |
| FROM | |
| Member m |
5.1 집합 함수 특징
- NULL 값은 무시하므로 통계에 잡히지 않음
- 만약 값이 없는데 SUM, AVG, MAX, MIN 함수를 사용하면 NULL 값이 되며 COUNT는 0이 됨
- DISTINCT를 집합 함수 안에 사용해서 중복된 값을 제거하고 난 뒤 집합을 구할 수 있음
- DISTINCT를 COUNT에서 사용할 때 임베디드 타입은 지원하지 않음
| 함수 | 설명 |
| COUNT | 결과 수를 반환하며 반환 타입은 Long |
| MAX, MIN | 문자, 숫자, 날짜 등에 사용되며 최대, 최소 값을 구함 |
| AVG | 숫자 타입만 사용 가능하며 평균 값을 구함, 반환 타입은 Double |
| SUM | 숫자 타입만 사용 가능하며 합을 구함 |
5.2 GROUP BY, HAVING
- GROUP BY는 통계 데이터를 구할 때 특정 그룹끼리 묶어주는 역할
- HAVING은 GROUP BY와 함께 사용되는데 GROUP BY로 그룹화한 통계 데이터를 기준으로 필터링
- 이런 쿼리들을 보통 통계 쿼리라고 부르며 통계 쿼리를 잘 활용하면 애플리케이션으로 수십 라인을 작성할 코드도 단 몇 줄이면 처리할 수 있음
- 하지만 보통 전체 데이터를 기준으로 처리하므로 실시간으로 사용하기에는 부담이 많으며 결과가 아주 많을 경우 통계 결과만 저장하는 테이블을 별도로 생성한 뒤 사용자가 적은 새벽에 통계 쿼리를 실행해서 해당 결과를 보관하는 것을 권장
그룹별 통계 데이터 중 평균나이가 10살 이상인 그룹을 조회하는 예제
| SELECT | |
| t.name, | |
| COUNT(m.age), | |
| SUM(m.age), | |
| AVG(m.age), | |
| MAX(m.age), | |
| MIN(m.age) | |
| FROM | |
| Member m | |
| LEFT JOIN | |
| m.team t | |
| GROUP BY | |
| t.name | |
| HAVING | |
| AVG(m.age) >= 10 |
5.3 정렬 (ORDER BY)
- ORDER BY는 결과를 정렬할 때 사용
나이를 기준으로 내림차순으로 정렬한 뒤 나이가 같으면 이름을 기준으로 오름차순 정렬하는 예제
| SELECT m FROM Member m ORDER BY m.age DESC, m.username ASC |
6. JPQL 조인
JPQL도 조인을 지원하는데 SQL 조인과 기능은 같고 문법만 약간 다릅니다.
6.1 내부 조인 (INNER JOIN)
- JPQL 내부 조인 구문을 보면 SQL의 조인과 약간 다른 것을 확인 가능
- JPQL 조인의 가장 큰 특징은 연관 필드를 사용한다는 것
- 아래 예제에서 m.team이 연관 필드인데 연관 필드는 다른 엔티티와 연관관계를 가지기 위해 사용하는 필드
| // JPQL | |
| String teamName = "팀A"; | |
| String query = "SELECT m FROM Member m INNER JOIN m.team t WHERE t.name = :teamName"; | |
| List<Member> memberse = em.createQuery(query, Member.class) | |
| .setParameter("teamName", teamName) | |
| .getResultList(); | |
| // SQL | |
| SELECT | |
| M.ID AS ID, | |
| M.AGE AS AGE, | |
| M.TEAM_ID AS TEAM_ID, | |
| M.NAME AS NAME | |
| FROM | |
| MEMBER M | |
| INNER JOIN | |
| TEAM T | |
| ON | |
| M.TEAM_ID = T.ID | |
| WHERE | |
| T.NAME = ? |
6.2 외부 조인 (OUTER JOIN)
- 외부 조인은 기능상 SQL의 외부 조인과 같음
- OUTER는 생략 가능해서 보통 LEFT JOIN으로 사용함
| // JPQL | |
| SELECT m FROM Member m LEFT JOIN m.team t | |
| // SQL | |
| SELECT | |
| M.ID AS ID, | |
| M.AGE AS AGE, | |
| M.TEAM_ID AS TEAM_ID, | |
| M.NAME AS NAME | |
| FROM | |
| MEMBER M | |
| LEFT OUTER JOIN | |
| TEAM T | |
| ON | |
| M.TEAM_ID = T.ID | |
| WHERE | |
| T.NAME = ? |
6.3 컬렉션 조인
- 일대다 관계나 다대다 관계처럼 컬렉션을 사용하는 곳에 조인하는 것을 컬렉션 조인이라고 부름
- [회원 -> 팀]으로의 조인은 다대일 조인이면서 단일 값 연관 필드 (m.team)를 사용
- [팀 -> 회원]은 반대로 일대다 조인이면서 컬렉션 값 연관 필드 (t.members)를 사용
| SELECT t, m FROM TEAM t LEFT JOIN t.members m |
6.4 세타 조인
- WHERE 절을 사용해서 세타 조인을 할 수 있음
- 세타 조인은 내부 조인만 지원
- 세타 조인을 사용하면 전혀 관계없는 엔티티도 조인할 수 있음
| // JPQL | |
| SELECT COUNT(m) FROM Member m, Team t WHERE m.username = t.name | |
| // SQL | |
| SELECT | |
| COUNT(M.ID) | |
| FROM | |
| MEMBER M | |
| CROSS JOIN | |
| TEAM T | |
| WHERE | |
| M.USERNAME = T.NAME |
6.5 JOIN ON 절
- JPA 2.1부터 조인할 때 ON 절을 지원
- ON 절을 사용하면 조인 대상을 필터링한 뒤 조인할 수 있음
- INNER JOIN의 ON 절은 WHERE 절을 사용할 때와 결과가 같으므로 보통 ON 절은 OUTER JOIN에서만 사용
| // JPQL | |
| SELECT m, t FROM Member m LEFT JOIN m.team t ON t.name = 'A' | |
| // SQL | |
| SELECT | |
| m.*, | |
| t.* | |
| FROM | |
| Member m | |
| LEFT JOIN | |
| Team t | |
| ON | |
| m.TEAM_ID = t.id | |
| AND | |
| t.name = 'A' |
7. 페치 조인
- SQL에서 이야기하는 조인의 종류는 아니고 JPQL에서 성능 최적화를 위해 제공하는 기능
- 연관된 엔티티나 컬렉션을 한 번에 같이 조회하는 기능인데 JOIN FETCH 명령어로 사용 가능
7.1 엔티티 페치 조인
- 아래 예제를 보면 JOIN 다음에 FETCH라 적은 것을 확인 가능하며 이렇게 하면 연관된 엔티티나 컬렉션을 함께 조회하는데 여기서는 회원과 팀을 함께 조회
- 일반적인 JPQL 조인과는 다르게 m.team 다음에 별칭이 없는데 페치 조인은 별칭을 사용할 수 없음
| // JPQL | |
| SELECT m FROM Member m JOIN FETCH m.team | |
| // 실행된 SQL | |
| SELECT | |
| M.*, | |
| T.* | |
| FROM | |
| MEMBER M | |
| INNER JOIN | |
| TEAM T | |
| ON | |
| M.TEAM_ID = T.ID |

부연 설명
- 엔티티 페치 조인 JPQL에서 select m으로 회원 엔티티만 선택했는데 실행된 SQL을 보면 SELECT M.*, T.*로 회원과 연관된 팀도 함께 조회된 것을 확인 가능
- 회원과 팀을 지연 로딩으로 설정했다고 가정했을 때 회원을 조회할 때 페치 조인을 사용해서 팀도 함께 조회했으므로 연관된 팀 엔티티는 프록시가 아닌 실제 엔티티
- 연관된 팀을 사용해도 지연 로딩이 발생하지 않음
- 프록시가 아닌 실제 엔티티이므로 회원 엔티티가 영속성 컨텍스트에서 분리되어 준영속 상태가 되어도 연관된 팀을 조회 가능
7.2 컬렉션 페치 조인
| // JPQL | |
| SELECT t FROM Team t JOIN FETCH t.members WHERE t.name = '팀A' | |
| // SQL | |
| SELECT | |
| T.*, | |
| M.* | |
| FROM | |
| TEAM T | |
| INNER JOIN | |
| MEMBER M | |
| ON | |
| T.ID = M.TEAM_ID | |
| WHERE | |
| T.NAME = '팀A' |
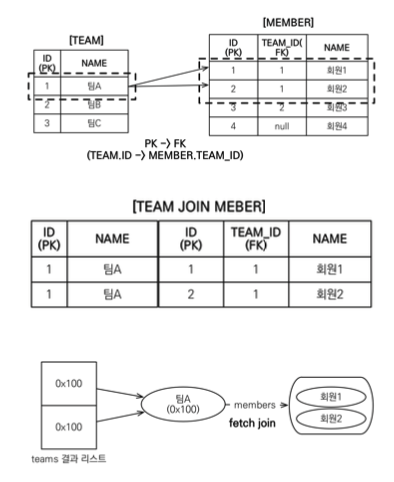
부연 설명
- 아래 예제에서 컬렉션을 페치 조인한 JPQL에서 select t로 팀만 선택했는데 실행된 SQL을 보면 T.*, M.*로 팀과 연관된 회원도 함께 조회한 것을 확인 가능
- TEAM 테이블에서 '팀A'는 하나지만 MEMBER 테이블과 조인하면서 결과가 증가해 조인 결과 테이블을 보면 같은 '팀A'가 두 건 조회된 것을 확인 가능
7.3 페치 조인과 DISTINCT
- SQL의 DISTINCT는 중복된 결과를 제거하는 명령어
- JPQL의 DISTINCT 명령어는 SQL에 DISTINCT를 추가하는 것은 물론이고 애플리케이션에서 한 번 더 중복을 제거
| // JPQL | |
| SELECT DISTINCT t FROM Team t JOIN FETCH t.members WHERE t.name = '팀A' |

부연 설명
- DISTINCT를 사용하면 SQL에 SELECT DISTINCT가 추가되지만 각 로우의 데이터가 다르므로 SQL의 DISTINCT는 효과가 없음
- JPQL의 DISTINCT 명령어는 애플리케이션에서도 중복을 제거하므로 중복인 팀A가 하나만 조회됨
7.4 페치 조인 vs 일반 조인
- JPQL은 결과를 반환할 때 연관관계까지 고려하지 않고 SELECT 절에 지정한 엔티티만 조회함
- 이에 따라 팀 엔티티만 조회하고 연관된 회원 컬렉션을 조회하지 않음
- 만약 회원 컬렉션을 지연 로딩으로 설정할 경우 프록시나 아직 초기화하지 않은 컬렉션 래퍼를 반환함
- 즉시 로딩으로 설정하면 회원 컬렉션을 즉시 로딩하기 위해 쿼리를 한 번 더 실행함
| // 일반 조인 JPQL | |
| SELECT t FROM Team t JOIN t.members m WHERE t.name = '팀A' | |
| // 실행된 SQL | |
| SELECT | |
| T.* | |
| FROM | |
| TEAM T | |
| INNER JOIN | |
| MEMBER M | |
| ON | |
| T.ID = M.TEAM_ID | |
| WHERE | |
| T.NAME = '팀A' |
- 반면, 페치 조인을 사용하면 연관된 엔티티도 함께 조회함
| // 컬렉션 페치 조인 JPQL | |
| SELECT t FROm Team t JOIN FETCH t.members WHERE t.name = '팀A' | |
| // 실행된 SQL | |
| SELECT | |
| T.*, | |
| M.* | |
| FROM | |
| TEAM T | |
| INNER JOIN | |
| MEMBER M | |
| ON | |
| T.ID = M.TEAM_ID | |
| WHERE | |
| T.NAME = '팀A' |
7.5 페치 조인의 특징과 한계
- 페치 조인을 사용하면 SQL 한 번으로 연관된 엔티티들을 함께 조회할 수 있어서 SQL 호출 횟수를 줄여 성능 최적화 가능
- 페치 조인은 글로벌 로딩 전략보다 우선함
- 엔티티에 직접 적용하는 로딩 전략은 애플리케이션 전체에 영향을 미치므로 글로벌 로딩 전략이라고 부름
- ex) 글로벌 로딩 전략을 지연 로딩으로 설정해도 JPQL에서 페치 조인을 사용하면 페치 조인을 적용해서 함께 조회
- 최적화를 위해 글로벌 로딩 전략을 즉시 로딩으로 설정할 경우 애플리케이션 전체에서 항상 즉시 로딩이 일어나는데 이렇게 설정할 경우 일부는 빠를 수 있지만 전체로 보면 사용하지 않는 엔티티를 자주 로딩하므로 오히려 악영향을 미칠 수 있음
- 따라서 글로벌 로딩 전략은 될 수 있으면 지연 로딩을 사용하고 최적화가 필요할 경우 페치 조인을 적용하는 것이 효과적
- 페치 조인을 사용하면 연관된 엔티티를 쿼리 시점에 조회하므로 지연 로딩이 발생하지 않기 때문에 준영속 상태에서도 객체 그래프를 탐색 가능
- 페치 조인 대상에는 별칭을 줄 수 없음
- 둘 이상의 컬렉션을 페치할 수 없음
- 구현체에 따라 되기도 하는데 컬렉션 * 컬렉션 카테시안 곱이 만들어지므로 주의해야 함
- 두 개 이상의 OneToMany 관계를 Fetch Join 할 때는 List 컬렉션 대신 Set 컬렉션으로 연관관계를 설정해야 MultipleBagFetchException이 발생하지 않음
- 컬렉션 페치 조인하면 페이징 API를 사용할 수 없음
- 컬렉션이 아닌 단일 값 연관 필드들은 페치 조인을 사용해도 페이징 API 사용 가능
- hibernate에서 컬렉션을 페치 조인하고 페이징 API를 사용하면 경고 로그를 남기면서 메모리에서 페이징 처리를 하는데 데이터가 적으면 상관없겠지만 데이터가 많으면 성능 이슈와 메모리 초과 예외가 발생할 수 있어서 위험함
8. 경로 표현식
- 경로 표현식이라는 것은 쉽게 이야기해서 . (점)을 찍어 객체 그래프르 탐색하는 것
| // m.username, m.team, m.orders, t.name이 모두 경로 표현식 | |
| SELECT m.username FROM Member m JOIN m.team t JOIN m.orders o WHERE t.name = '팀A' |
8.1 경로 표현식의 용어 정리
경로 표현식을 이해하려면 우선 다음 용어들을 알아야 합니다.
- 상태 필드 (state field): 단순히 값을 저장하기 위한 필드
- 연관 필드 (association field): 연관관계를 위한 필드, 임베디드 타입 포함
- 단일 값 연관 필드: @ManyToOne, @OneToOne, 대상이 엔티티
- 컬렉션 값 연관 필드: @OneToMany, @ManyToMany, 대상이 컬렉션
| @Entity | |
| public class Member { | |
| @Id | |
| @GeneratedValue | |
| private Long id; | |
| @Column(name = "name") | |
| private String username; // 상태 필드 | |
| private Integer age; // 상태 필드 | |
| @ManyToOne(..) | |
| private Team team; // 연관 필드 (단일 값 연관 필드) | |
| @OneToMany(..) | |
| private List<Order> orders; // 연관 필드 (컬렉션 값 연관 필드) | |
| } |
8.2 경로 표현식과 특징
JPQL에서 경로 표현식을 사용해서 경로 탐색을 하려면 다음 세 가지 경로에 따라 어떤 특징이 있는지 이해해야 합니다.
- 상태 필드 경로: 경로 탐색의 끝, 더는 탐색 불가
- 단일 값 연관 경로: 묵시적으로 INNER JOIN이 일어나며 단일 값 연관 경로는 계속 탐색 가능
- 컬렉션 값 연관 경로: 묵시적으로 INNER JOIN이 일어나며 더는 탐색할 수 없음, 단 FROM 절에서 조인을 통해 별칭을 얻으면 별칭을 통해 탐색 가능
| // 상태 필드 경로 탐색 | |
| SELECT m.username, m.age FROM Member m | |
| // 상태 필드 경로 탐색으로 인해 실행된 SQL | |
| SELECT | |
| m.name, | |
| m.age | |
| FROM | |
| Member m | |
| // 단일 값 연관 경로 탐색 | |
| SELECT o.member FROM Order o | |
| // 단일 값 연관 경로 탐색으로 인해 실행된 SQL | |
| SELECT | |
| m.* | |
| FROM | |
| Orders o | |
| INNER JOIN | |
| Member m | |
| ON | |
| o.member_id = m.id | |
| // 컬렉션 값 연관 경로 탐색 성공 사례 | |
| SELECT t.members FROM Team t | |
| // 컬렉션 값 연관 경로 탐색 실패 사례 | |
| SELECT t.members.username FROM Team t | |
| // 실패한 사례를 성공시키고 싶다면 | |
| SELECT m.username FROM Team t JOIN t.members m |
8.3 경로 탐색을 사용한 묵시적 조인 시 주의사항
경로 탐색을 사용하면 묵시적 조인이 발생해서 SQL에서 INNER JOIN이 일어날 수 있고 이에 따른 주의사항은 다음과 같습니다.
- 항상 INNER JOIN
- 컬렉션은 경로 탐색의 끝, 컬렉션에서 추가로 경로 탐색을 하려면 명시적으로 조인해서 별칭을 얻어야 함
- 경로 탐색은 주로 SELECT, WHERE 절에서 사용하지만 묵시적 조인으로 인해 SQL의 FROM 절에 영향을 줌
- 조인이 성능상 차지하는 부분은 아주 큰데 묵시적 조인은 조인이 일어나는 상황을 한눈에 파악하기 어렵다는 단점 존재
정리하면 묵시적 조인은 분석이 어려우므로 성능이 중요한 상황에서는 분석이 쉬운 명시적 조인을 사용하는 것을 권장합니다.
9. 서브 쿼리
JPQL도 SQL처럼 서브 쿼리를 지원하지만 몇 가지 제약이 존재합니다.
- 서브 쿼리를 WHERE, HAVING 절에서만 사용할 수 있고
- SELECT, FROM 절에서는 사용 불가
| // 나이가 평균보다 많은 회원 조회 | |
| SELECT m FROM Member m WHERE m.age > (SELECT avg(m2.age) FROM Member m2) | |
| // 한 건이라도 주문한 고객 조회 | |
| SELECT m FROM Member m WHERE (SELECT COUNT(o) FROM Order o WHERE m = o.member) > 0 |
9.1 서브 쿼리 함수
서브 쿼리는 다음 함수들과 같이 사용할 수 있습니다.
- [NOT] EXISTS (subquery): 서브 쿼리에 결과가 존재하면 참, NOT은 반대
- {ALL | ANY | SOME} (subquery): 비교 연산자와 같이 사용하며 ALL은 조건을 모두 만족하면 참, ANY 혹은 SOME의 경우 조건을 하나라도 만족하면 참
- [NOT] IN (subquery): 서브 쿼리의 결과 중 하나라도 같은 것이 있으면 참, IN은 서브 쿼리가 아닌 곳에서도 사용
| // 팀A 소속인 회원 | |
| SELECT m FROM Member m WHERE EXISTS (SELECT t FROM m.team t WHERE t.name = '팀A') | |
| // 전체 상품 각각의 재고보다 주문량이 많은 주문들 | |
| SELECT o FROM Order o WHERE o.orderAmount > ALL (SELECT p.stockAmount FROM Product p) | |
| // 어떤 팀이든 팀에 소속된 회원 | |
| SELECT m FROM Member m WHERE m.team = ANY (SELECT t FROM Team t) | |
| // 20세 이상을 보유한 팀 | |
| SELECT t FROM Team t WHERE t IN (SELECT t2 FROM Team t2 JOIN t2.members m2 WHERE m2.age >= 20) |
10. 다형성 쿼리
JPQL로 부모 엔티티를 조회하면 자식 엔티티도 함께 조회됩니다.
| @Entity | |
| @DiscriminatorColumn(name = "DTYPE") | |
| @Inheritance(strategy = InheritanceType.SINGLE_TABLE) | |
| public abstract class Item {...} | |
| @Entity | |
| @DiscriminatorValue("B") | |
| public class Book extends Item { | |
| // 중략 | |
| private String author; | |
| } | |
| // Album, Movie 생략 |
다음과 같이 조회하면 Item의 자식도 함께 조회됩니다.
| List resultList = em.createQuery("SELECT i FROM Item i").getResultList(); | |
| // 단일 테이블 전략을 사용할 때 실행되는 SQL | |
| SELECT | |
| * | |
| FROM | |
| ITEM | |
| // 조인 전략을 상요할 때 실행되는 SQL | |
| SELECT | |
| i.ITEM_ID, i.DTYPE, i.name, i.price, i.stockQuantity, | |
| b.author, b.isbn, | |
| a.artist, a.etc, | |
| m.actor, m.director | |
| FROM | |
| Item i | |
| LEFT OUTER JOIN | |
| Book b | |
| ON | |
| i.ITEM_ID = b.ITEM_ID | |
| LEFT OUTER JOIN | |
| Album a | |
| ON | |
| i.ITEM_ID = a.ITEM_ID | |
| LEFT OUTER JOIN | |
| Movie m | |
| ON | |
| i.ITEM_ID = m.ITEM_ID |
10.1 TYPE
TYPE은 엔티티의 상속 구조에서 조회 대상을 특정 자식 타입으로 한정할 때 주로 사용합니다.
| // JPQL | |
| SELECT i FROM Item i WHERE TYPE(i) IN (Book, Movie) | |
| // SQL | |
| SELECT i FROM Item i WHERe i.DTYPE in ('B', 'M') |
10.2 TREAT
TREAT는 JPA 2.1에 추가된 기능인데 자바의 타입 캐스팅과 비슷합니다.
- 상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용
- JPA 표준은 FROM, WHERE 절에서 사용할 수 있지만, hibernate는 SELECT 절에서도 TREAT를 사용할 수 있음
| // JPQL | |
| SELECT i FROM Item i WHERE TREAT(i AS Book).author = 'kim' | |
| // SQL | |
| SELECT | |
| i.* | |
| FROM | |
| Item i | |
| WHERE | |
| i.DTYPE = 'B' | |
| AND | |
| i.author = 'kim' |
11. 엔티티 직접 사용
11.1 기본 키 값
- 객체 인스턴스는 참조 값으로 식별하고 테이블 row는 기본 키 값으로 식별함
- 따라서 JPQL에서 엔티티 객체를 직접 사용하면 SQL에서는 해당 엔티티의 기본 키 값을 사용
| SELECT COUNT(m.id) FROM Member m // 엔티티의 아이디를 사용 | |
| SELECT COUNT(m) FROM Member m // 엔티티를 직접 사용 |
부연 설명
- 두 번째의 count(m)을 보면 엔티티의 별칭을 직접 넘겨주었는데 이렇게 엔티티를 직접 사용하면 JPQL이 SQL로 변환될 때 해당 엔티티의 기본 키를 사용함
- 따라서 두 쿼리 모두 실행된 SQL은 `SELECT COUNT(m.id) AS cnt FROM Member m`으로 같음
- JPQL의 COUNT(m)이 SQL에서 COUNT(m.id)로 변환된 것을 확인 가능
| // JPQL | |
| String qlString = "SELECT m FROM Member m WHERE m = :member"; | |
| List resultList = em.createQuery(qlString) | |
| .setParameter("member", member) | |
| .getResultList(); | |
| // 실행된 SQL | |
| SELECT | |
| m.* | |
| FROM | |
| Member m | |
| WHERE | |
| m.id = ? |
부연 설명
- JPQL과 SQL을 비교해보면 JPQL에서 `WHERE m = :member`로 엔티티를 직접 사용하는 부분이 SQL에서 `WHERE m.id =?`로 기본 키 값을 사용하도록 변환된 것을 확인 가능
11.2 외래 키 값
| // JPQL | |
| Team team = em.find(Team.class, 1L); | |
| String qlString = "SELECT m FROM Member m WHERE m.team = :team"; | |
| List resultList = em.createQuery(qlString) | |
| .setParameter("team", team) | |
| .getResultList(); | |
| // 실행되는 SQL | |
| SELECT | |
| m.* | |
| FROM | |
| Member m | |
| WHERE | |
| m.team_id = ? (팀 파라미터의 ID 값) |
부연 설명
- m.team.id를 보면 Member와 Team 간에 묵시적 조인이 일어날 것 같지만 MEMBER 테이블이 team_id 외래 키를 가지고 있으므로 묵시적 조인은 일어나지 않음
- 물론 m.team.name을 호출하면 묵시적 조인이 일어남
12. Named 쿼리: 정적 쿼리
- JPQL 쿼리는 크게 동적 쿼리와 정적 쿼리로 구분 가능
- 동적 쿼리: em.createQuery("select .."처럼 JPQL을 문자로 완성해서 직접 넘기는 쿼리, 런타임에 특정 조건에 따라 JPQL을 동적으로 구성 가능
- 정적 쿼리: 미리 정의한 쿼리에 이름을 부여해서 필요할 때 사용할 수 있는데 이것을 Named 쿼리라고 부름, Named 쿼리는 한 번 정의하면 변경할 수 없는 정적인 쿼리
- Named 쿼리는 애플리케이션 로딩 시점에 JPQL 문법을 체크한 뒤 미리 파싱해 둠
- 이에 따라 오류를 빨리 확인할 수 있고, 사용하는 시점에는 파싱 된 결과를 재사용하므로 성능상 이점 존재
- Named 쿼리는 변하지 않는 정적 SQL이 생성되므로 데이터베이스의 조회 성능 최적화에도 도움이 됨
- Named 쿼리는 @NamedQuery 어노테이션을 사용해서 자바 코드에 작성 가능
12.1 NamedQuery 어노테이션
| @Target({ElementType.TYPE}) | |
| @Retention(RetentionPolicy.RUNTIME) | |
| public @interface NamedQuery { | |
| String name(); // Named 쿼리 이름 (필수) | |
| String query(); // JPQL 정의 (필수) | |
| LockModeType lockMode() default LockModeType.NONE; // 쿼리 실행 시 락모드를 설정할 수 있음 | |
| QueryHint[] hints() default {}; // JPA 구현체에 쿼리 힌트를 줄 수 있음 | |
| } |
12.2 Named 쿼리를 어노테이션에 정의
- Named 쿼리는 이름 그대로 쿼리에 이름을 부여해서 사용하는 방법
| @Entity | |
| @NamedQuery ( | |
| name = "Member.findByUsername", | |
| query = "SELECT m FROM Member m WHERE m.username = :username") | |
| public class Member { | |
| // 중략 | |
| } | |
| public List<Member> namedQueryFunction() { | |
| List<Member> resultList = em.createQuery("Member.findByUsername", Member.class) | |
| .setParameter("username", "회원1") | |
| .getResultList(); | |
| return resultList; | |
| } |
- 하나의 엔티티에 두 개 이상의 Named 쿼리를 정의하려면 @NamedQueries 어노테이션을 사용하면 됨
| @Entity | |
| @NamedQueries ({ | |
| @NamedQuery( | |
| name = "Member.findByUsername", | |
| query = "SELECT m FROM Member m WHERE m.username = :username"), | |
| @NamedQuery( | |
| name = "Member.count", | |
| query = "SELECT COUNT(m) FROM Member m") | |
| }) | |
| public class Member { | |
| // 중략 | |
| } |
Criteria
- Criteria 쿼리는 JPQL을 자바 코드로 작성하도록 지원하는 빌더 클래스 API
- Criteria를 사용하면 문자가 아닌 코드로 JPQL을 작성하므로 문법 오류를 컴파일 단계에서 잡을 수 있고 문자 기반의 JPQL보다 동적 쿼리를 안전하게 생성할 수 있음
- 하지만 실제 Criteria를 사용해서 개발해 보면 코드가 복잡하고 장황해서 직관적으로 이해하기 힘듦
1. Criteria 기초
모든 회원 엔티티를 조회하는 단순한 JPQL을 Criteria로 작성하면 아래와 같습니다.
| // JPQL: SELECT m FROM Member m | |
| // Criteria 쿼리 빌더 | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| // Criteria 생성, 반환 타입 지정 | |
| CriteriaQuery<Member> cq = cb.createQuery(Member.class); | |
| Root<Member> m = cq.from(Member.class); | |
| cq.select(m); | |
| TyupeQuery<Member> query = em.createQuery(cq); | |
| List<Member> members = query.getResultList(); |
이렇게 Criteria 쿼리를 완성하고 나면 다음 순서는 JPQL과 같으며 em.createQuery(cq)에 완성된 Criteria 쿼리를 넣어주기만 하면 됩니다.
검색 조건과 정렬을 추가한 예제는 아래와 같습니다.
| // JPQL | |
| // SELECT m FROM Member m | |
| // WHERE m.username = '회원1' | |
| // ORDER BY m.age DESC | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| CriteriaQuery<Member> cq = cb.createQuery(Member.class); | |
| Root<Member> m =cq.from(Member.class); | |
| // 검색 조건 정의 | |
| Predicate usernameEqual = cb.equal(m.get("username", "회원1")); | |
| // 정렬 조건 정의 | |
| javax.persistence.criteria.Order ageDesc = cb.desc(m.get("age")); | |
| // 쿼리 생성 | |
| cq.select(m) | |
| .where(usernameEqual) | |
| .orderBy(ageDesc); | |
| List<Member> resultList = em.createQuery(cq).getResultList(); |
부연 설명
- Criteria는 검색 조건부터 정렬까지 CriteriaBuilder를 사용해서 코드를 완성
- Root<Member> m = cq.from(Member.class); 여기서 m이 쿼리 루트이며 쿼리 루트는 조회의 시작점
2. Criteria 쿼리 생성
Criteria를 사용하려면 아래와 같이 CriteriaBuilder.createQuery() 메서드로 CriteriaQuery를 생성하면 됩니다.
| public interface CriteriaBuilder { | |
| // 조회값 반환 타입: Object | |
| CriteriaQuery<Object> createQuery(); | |
| // 조회값 반환 타입: 엔티티, 임베디드 타입, 기타 | |
| <T> CriteriaQuery<T> createQuery(Class<T> var1); | |
| // 조회값 반환 타입: Tuple | |
| CriteriaQuery<Tuple> createTupleQuery(); | |
| // 중략 | |
| } |
Criteria 쿼리를 생성할 때 파라미터로 쿼리 결과에 대한 반환 타입을 지정할 수 있습니다.
아래 코드와 같이 CriteriaQuery를 생성할 때 Member.class를 반환 타입으로 지정할 경우 em.createQuery(cq)에서 반환 타입을 지정하지 않아도 됩니다.
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| // Member를 반환 타입으로 지정 | |
| CriteriaQuery<Member> cq = cb.craeteQuery(Member.class); | |
| // 위에서 Member를 타입으로 지정했으므로 지정하지 않아도 Member 타입을 반환 | |
| List<Member> resultList = em.createQuery(cq).getResultList(); |
반환 타입을 지정할 수 없거나 반환 타입이 둘 이상이면 아래와 같이 타입을 지정하지 않고 Object로 반환받으면 됩니다.
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| CriteriaQuery<Object> cq = cb.createQuery(); // 조회값 반환 타입: Object | |
| List<Object> resultList = em.createQuery(cq).getResultList(); |
물론 반환 타입이 둘 이상일 경우 아래와 같이 Object[]를 사용하는 것이 편리합니다.
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| // 조회값 반환 타입: Object[] | |
| CriteriaQuery<Object[]> cq = cb.createQuery(Object[].class); | |
| List<Object[]> resultList = em.crateQuery(cq).getResultList(); |
반환 타입을 튜플로 받고 싶을 경우 아래와 같이 튜플을 사용하면 됩니다.
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| // 조회값 반환 타입: Tuple | |
| CriteriaQuery<Tuple> cq = cb.createTupleQuery(); | |
| TypeQuery<Tuple> query = em.craeteQuery(cq); |
3. 조회
3.1 조회 대상을 한 건, 여러 건 지정
- 조회 대상으로 하나만 지정하려면 select를 사용하면 되고
- 조회 대상을 여러 건을 지정하려면 multiselect를 사용하면 됨
- 여러 건 지정은 cb.array를 사용하면 됨
| // 한 건 조회 | |
| // JPQL: select m | |
| cq.select(m); | |
| // 여러 건 조회 | |
| // JPQL: select m.username, m.age | |
| cq.multiselect(m.get("username"), m.get("age")); | |
| // 여러 건 지정 | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| // JPQL: SELECT m.username, m.age | |
| cq.select(cb.array(m.get("username"), m.get("age"))); |
3.2 DISTINCT
- distinct는 select, multiselect 이후 distinct(true)를 사용하면 됨
| // JPQL: SELECT DISTINCE m.username, m.age FROM Member m | |
| CriteriaQuery<Object[]> cq = cb.createQuery(Object[].class); | |
| Root<Member> m = cq.from(Member.class); | |
| // cq.select(cb.array(m.get("username"), m.get("age"))).distinct(true); | |
| cq.multiselect(m.get("username"), m.get("age")).distinct(true); | |
| TypedQuery<Object[]> query = em.createQuery(cq); | |
| List<Object[]> resultList = query.getResultList(); |
3.3 NEW, construct()
- JPQL에서 select, new 생성자 구문을 Criteria에서는 cb.construct(클래스 타입, ...)로 사용
- JPQL에서는 생성자에 com.tistory.jaimemin.MemberDTO.class와 같이 패키지명까지 작성해야 하는 반면, Criteria는 코드를 직접 다루므로 MemberDTO.class처럼 패키지명 생략 가능
| // JPQL: SELECT new com.tistory.jaimemin.MEmberDTO(m.username, m.age) FROM Member m | |
| CriteriaQuery<MemberDTO> cq = cb.createQuery(MemberDTO.class); | |
| Root<Member> m = cq.from(Member.class); | |
| cq.select(cb.construct(MemberDTO.class, m.get("username"), m.get("age"))); | |
| TypeQuery<MemberDTO> query = em.createQuery(cq); | |
| List<MemberDTO> resultList = query.getResultList(); |
3.4 튜플
- Criteria는 Map과 비슷한 튜플이라는 특별한 반환 객체를 제공함
- 튜플은 이름 기반이므로 순서 기반의 Object[]보다 안전
- 또한 tuple.getElements() 같은 메서드를 사용해서 현재 튜플의 별칭과 자바 타입도 조회 가능
- 튜플을 사용하려면 cb.createTupleQuery() 또는 cb.createQuery(Tuple.class)로 Criteria를 생성해야 함
| CriteriaQuery<Tuple> cq = cb.createTupleQuery(); | |
| Root<Member> m = cq.from(Member.class); | |
| cq.select(cb.tuple( | |
| m.alias("m"), // 회원 엔티티, 별칭 m | |
| m.get("username").alias("name") // 별칭 username | |
| )); | |
| TypedQuery<Tuple> query = em.createQuery(cq); | |
| List<Tuple> resultList = query.getResultList(); | |
| for (Tuple tuple : resultList) { | |
| Member member = tuple.get("m", Member.class); | |
| String username = tuple.get("username", String.class); | |
| } |
4. 집합
4.1 GROUP BY
아래 예제는 팀 이름별로 나이가 가장 많은 사람과 가장 적은 사람을 구하는 코드입니다.
| // JPQL: SELECT m.team.name, max(m.age), min(m.age) FROM Member m GROUP BY m.team.name | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| CriteriaQuery<Object[]> cq = cb.createQuery(Object[].class); | |
| Root<Member> m = cq.from(Member.class); | |
| Expression maxAge = cb.max(m.<Integer>get("age")); | |
| Expression minAge = cb.min(m.<Integer>get("age")); | |
| cq.multiselect(m.get("team").get("name"), maxAge, minAge); | |
| cq.groupBy(m.get("team").get("name")); // GROUP BY | |
| TypedQuery<Object[]> query = em.craeteQuery(cq); | |
| List<Object[]> resultList = query.getResultList(); |
4.2 HAVING
앞선 GROUP BY 예제에서 팀에 가장 나이 어린 사람이 10살을 초과하는 팀을 조회한다는 조건을 추가하면 아래와 같습니다.
| cq.multiselect(m.get("team").get("name"), maxAge, minAge) | |
| .groupBy(m.get("team").get("name")) | |
| .having(cb.gt(minAge, 10)); // HAVING |
5. 정렬
- 정렬 조건도 Criteria 빌더를 통해서 생성됨
- cb.desc(...) 또는 cb.asc(...)로 생성 가능
| cq.select(m) | |
| .where(ageGt) | |
| .orderBy(cb.desc(m.get("age"))); // JPQL: ORDER BY m.age DESC |
6. 조인
- 조인은 join() 메서드와 JoinType 클래스를 사용
| // JPQL: SELECT m, t FROM Member m INNER JOIN m.team t WHERE t.name = '팀A' | |
| Root<Member> m = cq.from(Member.class); | |
| Join<Member, Team> t = m.join("team", JoinType.INNER); | |
| cq.multiselect(m, t) | |
| .where(cb.equal(t.get("name"), "팀A")); |
부연 설명
- 쿼리 루트(m)에서 바로 m.join("team") 메서드를 사용해서 회원과 팀을 조인했고 조인 team에 t라는 별칭을 부여
- 여기서는 JoinType.INNER를 설정해 INNER JOIN을 사용함
- OUTER JOIN은 JoinType.LEFT로 설정하면 됨
FETCH JOIN은 아래와 같이 사용하면 됩니다.
| Root<Member> m = cq.from(Member.class); | |
| m.fetch("team", JoinType.LEFT); | |
| cq.select(m); |
7. 서브 쿼리
7.1 간단한 서브 쿼리
아래 코드는 평균 나이 이상의 회원을 구하는 서브 쿼리입니다.
| // JPQL: SELECT m FROM Member m WHERE m.age >= (SELECT AVG(m2.age) FROM Member m2) | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| CriteriaQuery<Member> mainQuery = cb.createQuery(Member.class); | |
| // 서브 쿼리 생성 | |
| Subquery<Double> subQuery = mainQuery.subquery(Double.class); | |
| Root<Member> m2 = subQuery.from(Member.class); | |
| subQuery.select(cb.avg(m2, <Integer>get("age"))); | |
| // 메인 쿼리 생성 | |
| Root<Member> m = mainQuery.from(Member.class); | |
| mainQuery.select(m) | |
| .where(cb.ge(m, <Integer>get("age"), subQuery)); |
7.2 상호 관련 서브 쿼리
- 서브 쿼리에서 메인 쿼리의 정보를 사용하려면 메인 쿼리에서 사용한 별칭을 얻어야 함
- 서브 쿼리는 메인 쿼리의 Root나 Join을 통해 생성된 별칭을 받아서 다음과 같이 사용 가능
- .where(cb.equal(subM.get("username"), m.get("username")));
아래 예제는 팀A에 소속된 회원을 찾는 코드입니다.
조인이 더 효과적인 해결책이겠지만 상호 관련 서브 쿼리에 초점을 두고 코드를 작성했습니다.
| // JPQL: SELECT m FROM Member m WHERE EXISTS (SELECT t FROM m.team t WHERE t.name = '팀A') | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| CriteriaQuery<Member> mainQuery = cb.createQuery(Member.class); | |
| // 서브 쿼리에서 사용되는 메인 쿼리의 lm | |
| Root<Member> m = mainQuery.from(Member.class); | |
| // 서브 쿼리 생성 | |
| Subquery<Team> subQuery = mainQuery.subquery(Team.class); | |
| Root<Member> subM = subQuery.correlate(m); // 메인 쿼리의 별칭을 가져옴 | |
| Join<Member, Team> t = subM.join("team"); | |
| subQuery.select(t) | |
| .where(cb.equal(t.get("name"), "팀A")); | |
| // 메인 쿼리 생성 | |
| mainQuery.select(m) | |
| .where(cb.exists(subQuery)); | |
| List<Member> resultList = em.createQuery(mainQuery).getResultList(); |
8. IN 식
- IN 식은 CriteriaBuilder에서 in(,..) 메서드를 사용
| // JPQL: SELECT m FROM Member m WHERE m.username IN ("회원1", "회원2") | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| CriteriaQuery<Member> cq = cb.craeteQuery(Member.class); | |
| Root<Member> m = cq.from(Member.class); | |
| cq.select(m) | |
| .where(cb.in(m.get("username")) | |
| .value("회원1") | |
| .value("회원2")); |
9. CASE 식
- CASE 식에는 selectCase() 메서드와 when(), otherwise() 메서드를 사용
| // JPQL | |
| /** | |
| SELECT m.username, | |
| CASE | |
| WHEN m.age >= 60 THEN 600 | |
| WHEN m.age <= 15 THEN 500 | |
| ELSE 1000 | |
| END | |
| FROM Member m | |
| **/ | |
| Root<Member> m = cq.from(Member.class); | |
| cq.multiselect( | |
| m.get("username"), | |
| cb.selectCase() | |
| .when(cb.ge(m, <Integer>get("age"), 60), 600) | |
| .when(cb.le(m, <Integer>get("age"), 15), 500) | |
| .otherwise(1000) | |
| ); |
10. 파라미터 정의
- JPQL에서 :PARAM1처럼 파라미터를 정의했듯이 Criteria도 파라미터를 정의할 수 있음
| // JPQL: SELECT m FROM Member m WHERE m.username = :usernameParam | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| CriteriaQuery<Member> cq = cb.createQuery(Member.class); | |
| Root<Member> m = cq.from(Member.class); | |
| // 정의 | |
| cq.select(m) | |
| .where(cb.equal(m.get("username"), cb.parameter(String.class, "usernameParam"))); | |
| List<Member> resultList = em.createQuery(cq) | |
| .setParameter("usernameParam", "회원1") // 바인딩 | |
| .getResultList(); |
11. 네이티브 함수 호출
- 네이티브 SQL 함수를 호출하기 위해서는 cb.function(...) 메서드를 사용하면 됨
아래 코드는 native sql을 통해 전체 회원의 나이 합을 구하는 코드입니다.
| Root<Member> m = cq.from(Member.class); | |
| Expression<Long> function = cb.function("SUM", Long.class, m.get("age")); | |
| cq.select(function); |
12. 동적 쿼리
- 다양한 검색 조건에 따라 실행 시점에 쿼리를 생성하는 것을 동적 쿼리라 부름
- 동적 쿼리는 문자 기반인 JPQL보다는 코드 기반인 Criteria로 작성하는 것이 더 편리함
비교를 위해 JPQL로 만든 동적 쿼리와 Criteria로 구성한 동적 쿼리 예제를 모두 작성해 보겠습니다.
12.1 JPQL 동적 쿼리
- JPQL로 동적 쿼리를 구성하는 것이 아슬아슬한 줄타기와 같음
- 아래처럼 단순한 동적 쿼리 코드를 개발하더라도 문자 더하기로 인해, 휴먼 에러에 여러 번 노출됨
- 특히 문자 사이에 공백을 입력하지 않아서 age=:ageandusername=:username처럼 되는 것은 다들 한 번씩 겪는 문제
| // 검색 조건 | |
| Integer age = 10; | |
| String username = null; | |
| String teamName = "팀A"; | |
| // JPQL 동적 쿼리 생성 | |
| StringBuilder jpql = new StringBuilder("SELECT m FROM Member m JOIN m.team t"); | |
| List<String> criteria = new ArrayList<>(); | |
| if (age != null) { | |
| criteria.add(" m.age = :age "); | |
| } | |
| if (username != null) { | |
| criteria.add(" m.username = :username "); | |
| } | |
| if (teamName != null) { | |
| criteria.add(" t.name = :teamName "); | |
| } | |
| if (criteria.size() > 0) { | |
| jpql.append(" where "); | |
| } | |
| for (int i = 0; i < criteria.size(); i++) { | |
| if (i > 0) { | |
| jpql.append(" and "); | |
| } | |
| jpql.append(criteria.get(i)); | |
| } | |
| TypeQuery<Member> query = em.createQuery(jpql.toString(), Member.class); | |
| if (age != null) { | |
| query.setParameter("age", age); | |
| } | |
| if (username != null) { | |
| query.setParameter("username", username); | |
| } | |
| if (teamName != null) { | |
| query.setParameter("teamName", teamName); | |
| } | |
| List<Member> resultList = query.getResultList(); |
12.2 Criteria로 구성한 동적 쿼리
- Criteria로 동적 쿼리를 구성하면 최소한 공백이나 where, and의 위치로 인해 에러가 발생하지는 않음
- 이런 장점에도 불구하고 Criteria의 장황하고 복잡함으로 인해 코드가 읽기 힘들다는 단점은 여전히 남아 있음
| // 검색 조건 | |
| Integer age = 10; | |
| String username = null; | |
| String teamName = "팀A"; | |
| // Criteria 동적 쿼리 생성 | |
| CriteriaBuilder cb = em.getCriteriaBuilder(); | |
| CriteriaQuery<Member> cq = cb.createQuery(Member.class); | |
| Root<Member> m = cq.from(Member.class); | |
| Join<Member, Team> t = m.join("team"); | |
| List<Predicate> criteria = new ArrayList<>(); | |
| if (age != null) { | |
| criteria.add(cb.equal(m, <Integer>get("age"), cb.parameter(Integer.class, "age"))); | |
| } | |
| if (username != null) { | |
| criteria.add(cb.equal(m.get("username"), cb.parameter(String.class, "username"))); | |
| } | |
| if (teamName != null) { | |
| criteria.add(cb.equal(t.get("name"), cb.parameter(String.class, "teamName"))); | |
| } | |
| cq.where(cb.and(criteria.toArray(new Predicate[0]))); | |
| TypeQuery<Member> query = em.createQuery(cq); | |
| if (age != null) { | |
| query.setParameter("age", age); | |
| } | |
| if (username != null) { | |
| query.setParameter("username", username); | |
| } | |
| if (teamName != null) { | |
| query.setParameter("teamName", teamName); | |
| } | |
| List<Member> resultList = query.getResultList(); |
13. Criteria 메타 모델 API
- Criteria는 코드 기반이므로 컴파일 시점에 오류를 발견할 수 있지만 m.get("age")에서 age는 문자
- 'age' 대신 실수로 'ageaaa' 이렇게 잘 못 적어도 컴파일 시점에 에러를 발견하지는 못 함
- 따라서 완벽한 코드 기반이라 할 수 없음
- 이런 부분까지 코드로 작성하려면 메타 모델 API를 사용해야 함
아래 코드는 메타 모델 API를 적용한 간단한 예제입니다.
| // 메타 모델 API 적용 전 | |
| cq.select(m) | |
| .where(cb.gt(m.<Integer>get("age"), 20)) | |
| .orderBy(cb.desc(m.get("age"))); | |
| // 메타 모델 API 적용 후 | |
| cq.select(m) | |
| .where(cb.gt(m.get(Member_.age), 20)) | |
| .orderBy(cb.desc(m.get(Member_.age))); |
부연 설명
- m.<Integer>get("age")를 보면 문자 기반에서 m.get(Member_.age)처럼 정적인 코드 기반으로 변경된 것을 확인 가능
- 이렇게 하려면 Member_ 클래스가 필요한데 이것을 메타 모델 클래스라고 부름
- 이런 클래스를 표준(CANONICAL) 메타 모델 클래스라 하는데 줄여서 메타 모델이라 부름
- Member_ 메타 모델 클래스는 Member 엔티티를 기반으로 만들어야 함
- 개발자가 직접 작성하지 않고 코드 자동 생성기가 엔티티 클래스를 기반으로 메타 모델 클래스들을 생성해 줌
- 하이버네이트 구현체를 사용하면 코드 생성기는 org.hibernate.jpamodelgen.JPAMetaModelEntityProcessor를 사용하면 됨
- 코드 생성기는 모든 엔티티 클래스를 찾아서 {엔티티명_}.java 모양의 메타 모델 클래스를 생성해줌
QueryDSL
- QueryDSL은 쿼리를 문자가 아닌 코드로 작성해도, 쉽고 간결하며 그 모양도 쿼리와 비슷하게 개발할 수 있는 프로젝트
- QueryDSL도 Criteria처럼 JPQL 빌더 역할을 수행하므로 JPA Criteria를 대체할 수 있음
- QueryDSL은 오픈소스 프로젝트
- 업데이트 속도가 느려 SpringBoot 3.X 버전부터 QueryDSL을 사용하지 않는 조직들도 꽤 있음
- https://www.youtube.com/watch?v=-JgHKQMMFrQ&t=1s
1. QueryDSL 설정
- QueryDSL을 JPA와 함께 사용하기 위해서는 두 가지 설정이 필요
- 첫 번째는 런타임에 사용할 QueryDSL 라이브러리
- 두 번째는 컴파일 타임에 엔티티를 분석해 Q-type (쿼리 타입) 클래스를 자동 생성하는 annotation processor
책이 지필 된 지 10년이 되었다 보니 버전은 구버전인 3.6.3 기준으로 설명하겠습니다.
Gradle 설정 예시
| plugins { | |
| id 'java' | |
| // 필요에 따라 Spring Boot 또는 다른 플러그인들도 함께 적용합니다. | |
| } | |
| repositories { | |
| mavenCentral() | |
| } | |
| dependencies { | |
| // JPA 관련 스타터와 QueryDSL 라이브러리 포함 | |
| implementation 'org.springframework.boot:spring-boot-starter-data-jpa' | |
| implementation 'com.querydsl:querydsl-jpa:3.6.3' | |
| // QueryDSL annotation processor (JPA 환경에 맞추어 :jpa 추가) | |
| annotationProcessor 'com.querydsl:querydsl-apt:3.6.3:jpa' | |
| testImplementation 'org.springframework.boot:spring-boot-starter-test' | |
| } | |
| // 생성된 QueryDSL 소스코드를 기본 소스셋에 포함할 수 있도록 추가 | |
| sourceSets { | |
| main { | |
| java { | |
| // annotationProcessor가 생성한 Q-type 클래스가 저장되는 디렉토리 (Gradle 버전에 따라 경로가 달라질 수 있음) | |
| srcDir "$buildDir/generated/sources/annotationProcessor/java/main" | |
| } | |
| } | |
| } |
Maven 설정 예시
| <project> | |
| <!-- 프로젝트의 기본 설정들 (groupId, artifactId, version 등) --> | |
| <dependencies> | |
| <!-- JPA와 QueryDSL 런타임 라이브러리 --> | |
| <dependency> | |
| <groupId>com.querydsl</groupId> | |
| <artifactId>querydsl-jpa</artifactId> | |
| <version>3.6.3/version> | |
| </dependency> | |
| <!-- Q-type 생성을 위한 APT 라이브러리 (컴파일 타임에만 사용되므로 provided 범위로 설정) --> | |
| <dependency> | |
| <groupId>com.querydsl</groupId> | |
| <artifactId>querydsl-apt</artifactId> | |
| <version>3.6.3</version> | |
| <scope>provided</scope> | |
| </dependency> | |
| </dependencies> | |
| <build> | |
| <plugins> | |
| <!-- QueryDSL 자동 소스 생성 플러그인 예시 --> | |
| <plugin> | |
| <groupId>com.mysema.maven</groupId> | |
| <artifactId>apt-maven-plugin</artifactId> | |
| <version>1.1.3</version> | |
| <executions> | |
| <execution> | |
| <goals> | |
| <goal>process</goal> | |
| </goals> | |
| <configuration> | |
| <!-- 생성된 Q-type 클래스 파일이 저장될 디렉토리 --> | |
| <outputDirectory>target/generated-sources/java</outputDirectory> | |
| <!-- JPA용 Annotation Processor 지정 --> | |
| <processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor> | |
| </configuration> | |
| </execution> | |
| </executions> | |
| </plugin> | |
| </plugins> | |
| </build> | |
| </project> |
2. 시작
- QueryDSL을 사용하려면 우선 com.mysema.query.jpa.impl.JPAQuery 객체를 생성해야 하는데, 이때 엔티티 매니저를 생성자에 넘겨줌
- 다음으로 사용할 쿼리 타입(Q)을 생성하는데 생성자에는 별칭을 부여하면 됨
- Q Class는 maven compile 혹은 gradle compile 시 설정한 annotation processor에 의해 생성됨
| public void queryDSL() { | |
| EntityManager em = emf.createEntityManager(); | |
| JPAQuery query = new JPAQuery(em); | |
| QMember qMember = new QMember("m"); // 생성되는 JPQL의 별칭이 m | |
| List<Member> members = query.from(qMember) | |
| .where(qMember.name.eq("회원1")) | |
| .orderBy(qMember.name.desc()) | |
| .list(qMember); | |
| } |
2.1 기본 Q 생성
- 쿼리 타입(Q)은 사용하기 편리하도록 기본 인스턴스를 보관하고 있음
- 하지만 같은 엔티티를 조인하거나 같은 엔티티를 서브 쿼리에 사용하면 같은 별칭이 사용되므로 이때는 별칭을 직접 지정해서 사용해야 함
| public class QMember extends EntityPathBase<Member> { | |
| public static final QMember member = new QMember("member1"); | |
| // 중략 | |
| } | |
| // 쿼리 타입 사용 | |
| QMember member = new QMember("m"); // 직접 지정 | |
| QMember qMember = QMember.member; // 기본 인스턴스 사용 |
3. 검색 조건 쿼리
- QueryDSL의 where 절에는 and나 or를 사용할 수 있으며 다음처럼 여러 검색 조건을 사용해도 됨
- 이때는 and 연산이 됨
where(item.name.eq("좋은상품"), item.price.gt(20000))
- 쿼리 타입의 필드는 필요한 대부분의 메서드를 명시적으로 제공함
- where()에서 사용하는 대표적인 메서드는 다음과 같음
| item.price.between(10000, 20000); // 가격이 10,000 ~ 20,000원 상품 | |
| item.name.contains("상품1"); // 상ㅍ품1이라는 이름을 포함한 상품 | |
| item.name.startsWith("고급"); // 이름이 `고급`으로 시작하는 상품 |
4. 결과 조회
- 쿼리 작성이 끝나고 결과 조회 메서드를 호출하면 실제 데이터베이스를 조회함
- 보통 uniqueResult()나 list()를 사용하고 파라미터로 프로젝션 대상을 넘겨줌
- 결과 조회 API는 com.mysema.query.ProjectTable에 정의되어 있음
- 대표적인 결과 조회 메서드는 다음과 같음
- uniqueResult(): 조회 결과가 한 건일 때 사용, 조회 결과가 없으면 null을 반환하고 결과가 하나 이상이면 NonUniqueResultException 예외 발생
- singleResult(): uniqueResult()와 같지만 결과가 하나 이상일 경우 처음 데이터를 반환
- list(): 결과가 한나 이상일 때 사용하며 결과가 없으면 빈 컬렉션 반환
5. 페이징과 정렬
- 정렬은 orderBy를 사용하는데 쿼리 타입(Q)이 제공하는 asc(), desc()를 사용
- 페이징은 offset과 limit을 적절히 조합해서 사용하면 됨
- 페이징은 restrict() 메서드에 com.mysema.query.QueryModifiers를 파라미터로 사용해도 됨
- 실제 페이징 처리를 하려면 검색된 전체 데이터 수를 알아야 하는데 이때는 list() 대신 listResults()를 사용하면 됨
| // QueryModifiers | |
| QueryModifiers queryModifiers = new QueryModifiers(20L, 10L); // limit, offset | |
| List<Item> list = query.from(list) | |
| .restrict(queryModifier) | |
| .list(item); | |
| // listResults | |
| SearchResults<Item> result = query.from(item) | |
| .where(item.price.gt(10000)) | |
| .offset(10).limit(20) | |
| .listResults(item); | |
| long total = result.getTotal(); | |
| long limit = ressult.getLimit(); | |
| long offset = result.getOffset(); | |
| List<Item> results = result.getResults(); // 조회된 데이터 |
6. 그룹
- 그룹은 groupBy를 사용하고 그룹화한 결과에 조건을 부여하려면 having을 사용하면 됨
| query.from(item) | |
| .groupBy(item.price) | |
| .having(item.price.gt(1000)) | |
| .list(item); |
7. 조인
- 조인은 innerJoin(join), leftJoin, rightJoin, 그리고 fullJoin을 사용할 수 있고 추가로 JPQL의 on과 성능 최적화를 위한 fetch 조인도 사용할 수 있음
- 조인의 기본 문법은 첫 번째 파라미터에 조인 대상을 지정하고, 두 번째 파라미터에 별칭으로 사용할 쿼리 타입을 지정하면 됨
| // 기본 조인 | |
| QOrder order = QOrder.order; | |
| QMember member = QMember.member; | |
| QOrderItem orderItem = QOrderItem.orderItem; | |
| query.from(order) | |
| .join(order.member, member) | |
| .leftJoin(order.orderItem, orderItem) | |
| .list(order); | |
| // 조인 on 사용 | |
| query.from(order) | |
| .leftJoin(order.orderItems, orderItem) | |
| .on(orderItem.count.gt(2)) | |
| .list(order); | |
| // fetch 조인 사용 | |
| query.from(order) | |
| .innerJoin(order.member, member).fetch() | |
| .leftJoin(order.orderItems, orderItem).fetch() | |
| .list(order); | |
| // from 절에 여러 조건 사용 | |
| QOrder order = QOrder order; | |
| QMember member = QMember.member; | |
| query.from(order, member) | |
| .where(order.member.eq(member)) | |
| .list(order); |
8. 서브 쿼리
- 서브 쿼리는 com.mysema.query.jpa.JPASubQuery를 생성해서 사용함
- 서브 쿼리의 결과가 하나면 unique(), 여러 건이면 list()를 사용할 수 있음
| // 서브 쿼리 - 한 건 | |
| QItem item = QItem.item; | |
| QItem itemSub = new QItem("itemSub"); | |
| query.from(item) | |
| .where(item.price.eq( | |
| new JPASubQuery().from(itemSub).unique(itemSub.price.max()) | |
| )) | |
| .list(item); | |
| // 서브 쿼리 - 여러 건 | |
| QItem item = QItem.item; | |
| QItem itemSub = new QItem("itemSub"); | |
| query.from(item) | |
| .where(item.in( | |
| new JPASubQuery().from(itemSub) | |
| .where(item.name.eq(itemSub.name)) | |
| .list(itemSub) | |
| )) | |
| .list(item); |
9. 프로젝션과 결과 반환
- select 절에 조회 대상을 지정하는 것을 프로젝션이라고 함
- 프로젝션 대상이 하나면 해당 타입으로 반환
- 프로젝션 대상으로 여러 필드를 선택하면 QueryDSL은 기본으로 com.mysema.query.Tuple이라는 Map과 비슷한 내부 타입을 사용하고 조회 결과는 tuple.get() 메서드에 조회한 쿼리 타입을 지정하면 됨
- 쿼리 결과를 엔티티가 아닌 특정 객체로 받고 싶으면 빈 생성 기능을 사용하면 되며 QueryDSL은 객체를 생성하는 다양한 방법을 제공함
- 프로퍼티 접근
- 필드 직접 접근
- 생성자 사용
| // 프로젝션 대상이 하나 | |
| QItem item = QItem.item; | |
| List<String> result = query.from(item).list(item.name); | |
| for (String name : result) { | |
| log.info("name = {}", name); | |
| } | |
| // 튜플 사용 | |
| QItem item = QItem.item; | |
| List<Tuple> result = query.from(item) | |
| .list(item.name, item.price); | |
| for (Tuple tuple : result) { | |
| log.info("name = {}", tuple.get(item.name)); | |
| log.info("price = {}", tuple.get(item.price)); | |
| } | |
| // 프로퍼티 접근 | |
| @Getter | |
| @Setter | |
| @NoArgsConstructor | |
| @AllArgsConstructor | |
| public class ItemDTO { | |
| private String username; | |
| priate int price; | |
| } | |
| QItem item = QItem.item; | |
| List<ItemDTO> result = query.from(item) | |
| .list(Projections.bean(ItemDTO.class, item.name.as("username"), item.price)); | |
| // 필드 직접 접근 | |
| QItem item = QItem.item; | |
| List<ItemDTO> result = query.from(item) | |
| .list(Projections.fields(ItemDTO.class, item.name.as("username"), item.price)); | |
| // 생성자 사용 | |
| QItem item = QItem.item; | |
| List<ItemDTO> result = query.from.item) | |
| .list(Projections.constructor(ItemDTO.class, item.name, item.price)); |
9.1 DISTINCT
distinct는 다음과 같이 사용하면 됩니다.
- query.distinct().from(item)...
10. 수정, 삭제 배치 쿼리
- QueryDSL도 수정, 삭제 같은 배치 쿼리를 지원함
- 유의할 점은 JPQL 배치 쿼리와 같이 영속성 컨텍스트를 무시하고 데이터베이스를 직접 쿼리한다는 것
| // 수정 배치 쿼리 | |
| QItem item = QItem.item; | |
| JPAUpdateClause updateClause = new JPAUpdateClause(em, item); | |
| long count = updateClause.where(item.name.eq("JPA 책")) | |
| .set(item.prices, item.price.add(100)) // 상품 가격 100원 증가 시킴 | |
| .execute(); | |
| // 삭제 배치 쿼리 | |
| QItem item = QItem.item; | |
| JPADeleteClause deleteClause = new JPADeleteClause(em, item); | |
| long count = deleteClause.where(item.name.eq("JPA 책")).execute(); |
11. 동적 쿼리
- com.mysema.query.BooleanBuilder를 사용하면 특정 조건에 따른 동적 쿼리를 편리하게 생성 가능
- 아래 예제는 상품 이름과 가격 유무에 따라 동적으로 쿼리를 생성
| SearchParam param = new SearchParam(); | |
| param.setName("jaimemin"); | |
| param.setPrice(10000); | |
| QItem item = QItem.item; | |
| BooleanBuilder builder = new BooleanBuilder(); | |
| if (StringUtils.hasText(param.getName())) { | |
| builder.and(item.name.contains(param.getName())); | |
| } | |
| if (param.getPrice() != null) { | |
| builder.and(item.price.gt(param.getPrice())); | |
| } | |
| List<Item> result = query.from(item) | |
| .where(builder) | |
| .list(item); |
12. 메서드 위임 (Delegate Methods)
- 메서드 위임 기능을 사용하면 쿼리 타입에 검색 조건을 직접 정의 가능
- 메서드 위임 기능을 사용하려면 정적 메서드를 만들고 @QueryDelegate 어노테이션에 속성으로 해당 기능을 적용할 엔티티를 지정하면 됨
- 정적 메서드의 첫 번째 파라미터에는 대상 엔티티의 쿼리 타입을 지정하고 나머지는 필요한 파라미터를 정의
| // 검색 조건 정의 | |
| public class ItemExpression { | |
| @QueryDelegate(Item.class) | |
| public static BooleanExpression isExpensive(QItem item, Integer price) { | |
| return item.price.gt(price); | |
| } | |
| } | |
| // 쿼리 타입에 생성된 결과 | |
| public class QItem extends EntityPathBase<Item> { | |
| // 중략 | |
| public com.mysema.query.types.expr.BooleanExpression isExpensive(Integer price) { | |
| return ItemExpression.isExpensive(this, price); | |
| } | |
| } | |
| // 메서드 위임 기능 사용 예제 | |
| query.from(item).where(item.isExpensive(30000)).list(item); |
13. QueryDSL 정리
- JPA를 사용하면 두 가지 고민에 봉착함
- 문자가 아닌 코드로 안전하게 쿼리를 작성할 수 있을까?
- 복잡한 동적 쿼리를 어떻게 해결해야 할까?
- JPA Criteria가 위 고민을 해결해 주기는 했지만, 막상 사용해 보면 너무 복잡해서 JPQL을 직접 사용하고 싶어짐
- 반면, QueryDSL은 두 가지를 모두 만족하면서 쉽고 단순함
네이티브 SQL
- JPQL은 표준 SQL이 지원하는 대부분의 문법과 SQL 함수들을 지원하지만 특정 데이터베이스에 종속적인 기능은 지원하지 않음
- ex) 특정 데이터베이스만 지원하는 함수, 문법, SQL 쿼리 힌트
- 인라인 뷰, UNION, INTERSECT
- 스토어 프로시저
- 때로는 특정 데이터베이스에 종속적인 기능이 필요한데 특정 데이터베이스에 종속적인 기능을 지원하는 방법은 다음과 같음
- 특정 데이터베이스만 사용하는 함수: JPQL에서 Native SQL 함수를 호출할 수 있음, 하이버네이트는 데이터베이스 방언에 각 데이터베이스에 종속적인 함수들을 정의해두었고 직접 호출할 함수 또한 정의 가능
- 특정 데이터베이스만 지원하는 SQL 쿼리 힌트: 하이버네이트를 포함한 몇몇 JPA 구현체들이 지원
- 인라인 뷰, UNION, INTERSECT: 하이버네이트는 지원하지 않지만, 일부 JPA 구현체들이 지원
- 스토어 프로시저: JPQL에서 스토어드 프로시저를 호출 가능
- 특정 데이터베이스만 지원하는 문법: 오라클의 CONNECT BY처럼 특정 데이터베이스에 너무 종속적인 SQL 문법은 지원하지 않고 이떄 Native SQL을 사용해야 함
- 다양한 이유로 JPQL을 사용할 수 없을 때 JPA는 SQL을 직접 사용할 수 있는 기능을 제공하는데 이것을 네이티브 SQL이라고 함
- JPQL을 사용하면 JPA가 SQL을 생성하는 반면, 네이티브 SQL은 이 SQL을 개발자가 직접 정의하는 것
- JPQL이 자동 모드라면 네이티브 SQL은 수동 모드
- JDBC API를 직접 사용하는 것과 달리 네이티브 SQL을 사용하면 엔티티를 조회할 수 있고 JPA가 지원하는 영속성 컨텍스트의 기능을 그대로 사용 가능
1. 네이티브 SQL 사용
네이티브 쿼리 API는 다음 세 가지가 있습니다.
| // 결과 타입 정의 | |
| public Query createNativeQuery(String sqlString, Class resultClass); | |
| // 결과 타입을 정의할 수 없을 때 | |
| public Query createNativeQuery(String sqlString); | |
| public Query createNativeQuery(String sqlString, String resultSetMapping); // 결과 매핑 사용 |
1.1 엔티티 조회
- 네이티브 SQL은 em.createNativeQuery(SQL, 결과 클래스)를 사용
- 첫 번째 파라미터는 네이티브 SQL을 입력
- 두 번째 파라미터는 조회할 엔티티 클래스의 타입을 입력
- 중요한 점은 네이티브 SQL로 SQL만 직접 사용할 뿐이지 나머지는 JPQL을 사용할 때와 같으며 조회한 엔티티도 영속성 컨텍스트에서 관리됨
| // SQL 정의 | |
| String sql = "SELECT ID, AGE, NAME, TEAM_ID FROM MEMBER WHERE AGE > ?"; | |
| Query nativeQuery = em.createNativeQuery(sql, Member.class) | |
| .setParameter(1, 20); | |
| List<Member> resultList = nativeQuery.getResultList(); |
1.2 값 조회
단순히 값으로만 조회하는 방법은 아래 예제와 같습니다.
| // SQL 정의 | |
| String sql = "SELECT ID, AGE, NAME, TEAM_ID FROM MEMBER WHERE AGE > ?"; | |
| Query nativeQuery = em.createNativeQuery(sql) | |
| .setParameter(1, 10); | |
| List<Object[]> reusltList = nativeQuery.getResultList(); | |
| for (Object[] row : resultList) { | |
| log.info("id = {}", row[0]); | |
| log.info("age = {}", row[1]); | |
| log.info("name = {}", row[2]); | |
| log.info("team_id = {}", row[3]); | |
| } |
부연 설명
- 여러 값으로 조회하려면 em.createNativeQuery(SQL)의 두 번째 파라미터를 사용하지 않으면 되고 JPA는 조회한 값들을 Object[]에 담아서 반환
- 위 예제는 스칼라 값들을 조회했을 뿐이므로 JDBC로 데이터를 조회하는 것과 같이 결과를 영속성 컨텍스트가 관리하지 않음
1.3 결과 매핑 사용
- 엔티티와 스칼라 값을 함께 조회하는 것처럼 매핑이 복잡해지면 @SqlResultSetMapping을 정의해서 결과 매핑을 사용해야 함
| @Entity | |
| @SqlResultSetMapping(name = "memberWithOrderCount", | |
| entities = {@EntityResult(entityClass = Member.class)}, | |
| columns = {@ColumnResult(name = "ORDER_COUNT")} | |
| public class Member { | |
| // 중략 | |
| } | |
| // SQL 정의 | |
| String sql = "SELECT M.ID, AGE, NAME, TEAM_ID, I.ORDER_COUNT " + | |
| "FROM MEMBER M " + | |
| "LEFT JOIN " + | |
| " (SELECT IM.ID, COUNT(*) AS ORDER_COUNT " + | |
| " FROM ORDERS O, MMEMBER IM " + | |
| " WHERE O.MEMBER_ID = IM.ID) I " + | |
| "ON M.ID = I.ID"; | |
| // 매핑 | |
| Query nativeQuery = em.createNativeQuery(sql, "memberWithOrderCount"); | |
| List<Object[]> resultList = nativeQuery.getResultList(); | |
| for (Object[] row : resultList) { | |
| Member member = (Member) row[0]; | |
| BigInteger orderCount = (BigInteger) row[1]; | |
| log.info("member = {}", member); | |
| log.info("orderCount = {}", orderCount); | |
| } |
부연 설명
- memberWithOrderCount의 결과 매핑을 잘 보면 회원 엔티티와 ORDER_COUNT 컬럼을 매핑함
- 사용한 쿼리 결과에서 ID, AGE, NAME, TEAM_ID는 Member 엔티티와 매핑하고 ORDER_COUNT는 단순히 값으로 매핑함
- 그리고 entities, columns라는 이름에서 알 수 있듯이 여러 엔티티와 여러 칼럼을 매핑할 수 있음
| @SqlResultSetMapping(name = "OrderResults", | |
| entities={ | |
| @EntityResult(entityClass=com.acme.Order.class, fieldss = { | |
| @FieldResult(name = "id", column = "order_id"), | |
| @FieldResult(name = "quantity", column = "order_quantity"), | |
| @FieldResult(name = "item", column = "order_item")})}, | |
| columns={ | |
| @ColumnResult(name = "item_name")} | |
| ) | |
| // SQL | |
| Query q = em.createNativeQuery( | |
| "SELECT o.id AS order_id, " + | |
| "o.quantity AS order_quantity, " + | |
| "o.item AS order_item, " + | |
| "i.name AS item_name, " + | |
| "FROM Order o, Item i " + | |
| "WHERE (order_quantity > 25) AND (order_item = i.id)", "OrderResults"); |
부연 설명
- @FieldResult를 사용해서 컬럼명과 필드명을 직접 매핑하며 해당 설정은 엔티티의 필드에 정의한 @Column보다 앞섬
- 단점은 @FieldResult를 한 번이라도 사용하면 전체 필드를 @FieldResult로 매핑해야 함
- 두 엔티티를 조회하는데 컬럼명이 중복될 때 컬럼명 충돌을 피하고자 @FieldResult를 사용해야 함
2. Named 네이티브 SQL
- JPQL처럼 네이티브 SQL도 Named 네이티브 SQL을 사용해서 정적 SQL을 작성할 수 있음
- JPQL Named 쿼리와 같은 createNamedQuery 메서드를 사용할 수 있으므로 TypeQuery를 사용할 수 있음
| // Named 네이티브 쿼리 등록 | |
| @Entity | |
| @NamedNativeQuery( | |
| name = "Member.memberSQL", | |
| query = "SELECT ID, AGE, NAME, TEAM_ID FROM MEMBER WHERE AGE > ?", | |
| resultClass = Member.class | |
| ) | |
| public class Member { | |
| // 중략 | |
| } | |
| // 활용 | |
| TypedQuery<Member> nativeQuery = em.createNamedQuery("Member.memberSQL", Member.class) | |
| .setParameter(1, 20); |
- Named 네이티브 SQL는 결과 매핑도 사용할 수 있음
| // resultSetMapping = "memberWithOrderCount"로 조회 결과를 매핑할 대상까지 지정 | |
| @Entity | |
| @SqlResultSetMapping(name = "membereWithOrderCount", | |
| entities = {@EntityResult(entityClass = Member.class)}, | |
| columns = {@ColumnResult(name = "ORDER_COUNT")} | |
| ) | |
| @NamedNativeQuery( | |
| name = "Member.memberWithOrderCount", | |
| query = "SELECT M.ID, AGE, NAME, TEAM_ID, I.ORDER_COUNT " + | |
| "FROM MEMBER M " + | |
| "LEFT JOIN " + | |
| " (SELECT IM.ID, COUNT(*) AS ORDER_COUNT " + | |
| " FROM ORDERS O, MEMBER IM " + | |
| " WHERE O.MEMBER_ID = IM.ID) I " + | |
| "ON M.ID = I.ID", | |
| resultSetMapping = "memberWithOrderCount" | |
| ) | |
| // Named 네이티브 쿼리를 사용하는 코드 | |
| List<Object[]> resultList = em.createQuery("Member.memberWithOrderCount") | |
| .getResultList(); | |
| public class Member { | |
| // 중략 | |
| } |
3. 네이티브 SQL 정리
- 네이티브 SQL도 JPQL을 사용할 때와 마찬가지로 Query, TypeQuery(Named 네이티브 쿼리의 경우에만)를 반환하므로 JPQL API를 그대로 사용 가능
- 또한, 네이티브 SQL은 JPQL이 자동 생성하는 SQL을 수동으로 직접 정의하는 것이므로 JPA가 제공하는 기능 대부분을 그대로 사용할 수 있음
- 다만, 네이티브 SQL은 관리하기 쉽지 않고 자주 사용하면 특정 데이터베이스에 종속적인 쿼리가 증가해 이식성이 떨어짐
- 될 수 있으면 표준 JPQL을 사용하고 기능이 부족하면 차선책으로 하이버네이트 같은 JPA 구현체가 제공하는 기능을 사용하는 것을 권장
- 현실적으로 네이티브 SQL을 사용하지 않을 수는 없지만 최후의 보루로 남겨놓는 것을 권장
4. 스토어드 프로시저
- JPA는 2.1 버전부터 스토어드 프로시저를 지원함
| // proc_multiply MySQL 프로시저 | |
| DELIMITER // | |
| CREATE PROCEDURE proc_multiply (INOUT inParam INT, INOUT outParam INT) | |
| BEGIN | |
| SET outParam = inParam * 2 | |
| END | |
| // 순서 기반 파라미터 호출 | |
| StoredProcedureQuery spq = em.createStoredProcedureQuery("proc_multiply"); | |
| spq.registerStoredProcedureParameter(1, Integer.class, ParameterMode.IN); | |
| spq.registerStoredProcedureParameter(2, Integer.class, ParameterMode.OUT); | |
| spq.setParameter(1, 100); | |
| spq.execute(); | |
| Integer out = (Integer) spq.getOutputParameterValue(2); | |
| log.info("out = {}", out); |
부연 설명
- proc_multiply는 단순히 입력값을 두 배로 증가시켜 주는 스토어드 프로시저
- 스토어드 프로시저를 사용하려면 e.createStoredProcedureQuery() 메서드에 사용할 스토어드 프로시저 이름을 입력하면 됨
- 그리고 registerStoredProcedureParameter() 메서드를 사용해서 프로시저에서 사용할 파라미터를 순서, 타입, 그리고 파라미터 모드 순으로 정의하면 됨
4.1 Named 스토어드 프로시저 사용
- Named 스토어드 프로시저는 스토어드 프로시저 쿼리에 이름을 부여해서 사용함
| // Named 스토어드 프로시저 어노테이션에 정의 | |
| @NamedStoredProcedureQuery( | |
| name = "multiply", | |
| procedureName = "proc_multiply", | |
| parameters = { | |
| @StoredProcedureParameter(name = "inParam", mode = ParameterMode.IN, type = Integer.class), | |
| @StoredProcedureParameter(name = "outParam", mode = ParameterMode.OUT, type = Integer.class) | |
| } | |
| ) | |
| @Entity | |
| public class Member { | |
| // 중략 | |
| } | |
| // Named 스토어드 프로시저 사용 | |
| StoredProcedureQuery spq = em.createNamedStoredProcedureQuery("multiply"); | |
| spq.setParameter("inParam", 100); | |
| spq.execute(); | |
| Integer out = (Integer) spq.getOutputParameterValue("outParam"); | |
| log.info("out = {}", out); |
부연 설명
- @NamedStoredProcedureQuery로 정의하고 name 속성으로 이름을 부여하면 됨
- procedureName 속성에 실제 호출할 프로시저명을 적어주고
- @StoredProcedureParameter를 사용해서 파라미터 정보를 정의하면 됨
- 둘 이상을 정의하려면 @NamedStoredProcedureQueries를 사용하면 됨
- 정의한 Named 스토어드 프로시저는 em.createNamedStoredProcedureQuery() 메서드에 등록한 Named 스토어드 프로시저 이름을 파라미터로 사용해서 찾아올 수 있음
객체지향 쿼리 심화
1. 벌크 연산
- 엔티티를 수정하려면 영속성 컨텍스트의 변경 감지 기능이나 병합을 사용하고, 삭제하려면 EntityManager.remove() 메서드를 사용
- 하지만 위 방법으로 수백개 이상의 엔티티를 하나씩 처리하기에는 시간이 너무 오래 걸림
- 여러 건을 한 번에 수정하거나 삭제하는 벌크 연산을 사용하면 시간을 단축시킬 수 있음
| String qlString = "UPDATE Product p " + | |
| "SET p.price = p.price * 1.1 " = | |
| "WHERE p.stockAmount < :stockAmount"; | |
| int resultCount = em.createQuery(qlString) | |
| .setParameter("stockAmount", 10) | |
| .executeUpdate(); // 벌크 연산 |
부연 설명
- 벌크 연산을 통해 재고가 10개 미만인 모든 상품의 가격을 10% 상승시키는 예제
- 벌크 연산은 executeUpdate() 메서드를 사용하며 해당 메서드는 벌크 연산으로 영향을 받은 엔티티 건수를 반환
- 벌크 삭제 또한 executeUpdate() 메서드를 사용
1.1 벌크 연산의 주의점
- 벌크 연산은 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리함
벌크 연산 사용 시 아래 예제와 같이 영속성 컨텍스트에 있는 상품A와 데이터베이스에 있는 상품A의 가격이 다를 수 있습니다.
| // 상품 A 조회 (상품 A의 가격은 1000원) | |
| Product productA = em.createQuery("SELECT p FROM Product p WHERE p.name = :name", Product.class) | |
| .setParameter("name", "productA") | |
| .getSingleResult(); | |
| // 출력 결과: 1000 | |
| log.info("productA 수정 전 = {}", productA.getPrice()); | |
| // 벌크 연산 수행으로 모든 상품 가격 10% 상승 | |
| em.createQuery("UPDATE Product p SET p.price = p.price * 1.1") | |
| .executeUpdate(); | |
| // 출력 결과: 1100원이 아닌 1000원 | |
| // 데이터베이스에는 1100원이 반영되었지만 영속성 컨텍스트에는 여전히 1000원 | |
| log.info("productA 수정 후 = {}", productA.getPrice()); |
위 예제와 같은 문제점의 해결책들은 다음과 같습니다.
- em.refresh() 사용: 벌크 연산을 수행한 직후 정확한 상품 A 엔티티를 사용해야 할 경우 em.refresh()를 사용해서 데이터베이스에서 상품 A를 다시 조회하면 됨 i.g. em.refresh(productA);
- 벌크 연산 먼저 실행: 가장 실용적인 해결책은 벌크 연산을 가장 먼저 실행한 뒤 변경된 상품 A를 조회하는 것 (JPA와 JDBC를 함께 사용할 때도 유용함)
- 벌크 연산 수행 후 영속성 컨텍스트 초기화: 벌크 연산을 수행한 직후 바로 영속성 컨텍스트를 초기화해서 영속성 컨텍스트에 남아 있는 엔티티를 제거하는 것도 좋은 방법
2. 영속성 컨텍스트와 JPQL
2.1 쿼리 후 영속 상태인 것과 아닌 것
- JPQL의 조회 대상은 엔티티, 임베디드 타입, 값 타입 같이 다양한 종류가 있음
- JPQL로 엔티티를 조회하면 영속성 컨텍스트에서 관리되지만 엔티티가 아니면 영속성 컨텍스트에서 관리되지 않음
- ex) 임베디트 타입은 조회해서 값을 변경해도 영속성 컨텍스트가 관리하지 않으므로 변경 감지에 의한 수정이 발생하지 않음
- 물론 엔티티를 조회하면 해당 엔티티가 가지고 있는 임베디트 타입도 함께 수정됨
2.2 JPQL로 조회한 엔티티와 영속성 컨텍스트
- JPQL로 데이터베이스에서 조회한 엔티티가 영속성 컨텍스트에 이미 있으면 JPQL로 데이터베이스에서 조회한 결과를 버리고 대신에 영속성 컨텍스트에 있던 엔티티를 반환
- 이때 식별자 값을 사용해서 비교함
- 영속성 컨텍스트 내 기존 엔티티를 새로 조회한 엔티티로 대체하지 않는 이유는 영속성 컨텍스트에서 수정 중인 데이터가 사라질 수 있는 위험이 존재하기 때문
- 영속성 컨텍스트는 엔티티의 동일성을 보장함


과정 설명
- JPQL을 사용해서 조회를 요청
- JPQL은 SQL로 변환되어 데이터베이스 조회
- 조회한 결과와 영속성 컨텍스트를 비교
- 식별자 값을 기준으로 member1은 이미 영속성 컨텍스트에 있으므로 버리고 기존에 있던 member1이 반환 대상이 됨
- 식별자 값을 기준으로 member2는 영속성 컨텍스트에 없으므로 영속성 컨텍스트에 추가
- 쿼리 결과인 member1, member2를 반환하며 여기서 member1은 쿼리 결과가 아닌 영속성 컨텍스트에 있던 엔티티
2.3 find() vs JPQL
- em.find() 메서드는 엔티티를 영속성 컨텍스트에서 먼저 찾고 없으면 데이터베이스에서 조회함
- 따라서 해당 엔티티가 영속성 컨텍스트에 있으면 메모리에서 바로 찾으므로 성능상 이점이 있
- 반면, JPQL은 항상 데이터베이스에 SQL을 실행해서 결과를 조회함
- JPA 구현체 개발자 입장에서 em.find() 메서드는 파라미터로 식별자 값을 넘기기 때문에 영속성 컨텍스트를 조회하기 쉽지만
- JPQL을 분석해서 영속성 컨텍스트를 조회하는 것은 쉬운 일이 아니었을 것

- JPQL의 특징을 정리하면 다음과 같음
- JPQL은 항상 데이터베이스를 조회
- JPQL로 조회한 엔티티는 영속 상태
- 영속성 컨텍스트에 이미 존재하는 엔티티가 있으면 기존 엔티티를 반환
3. JPQL과 플러시 모드
- flush는 영속성 컨텍스트의 변경 내역을 데이터베이스에 동기화하는 것
- JPA는 플러시가 일어날 때 영속성 컨텍스트에 등록, 수정, 그리고 삭제한 엔티티를 찾아서 INSERT, UPDATE, 그리고 DELETE SQL을 생성해서 데이터베이스에 반영함
- flush를 호출하려면 em.flush() 메서드를 직접 사용해도 되지만 보통 flushMode에 따라 커밋하기 직전이나 쿼리 실행 직전에 자동으로 flush가 호출됨
- em.setFlushMode(FlushModeType.AUTO); // 커밋 또는 쿼리 실행 시 flush (default)
- em.setFlushMode(FlushModeType.COMMIT); // 커밋시에만 플러시 (성능 최적화가 필연적일 때만 사용)
3.1 쿼리와 플러시 모드
- JPQL은 영속성 컨텍스트에 있는 데이터를 고려하지 않고 데이터베이스에서 데이터를 조회하기 때문에 JPQL을 실행하기 전에 영속성 컨텍스트의 내용을 데이터베이스에 반영해야 함
Default 설정인 FlushMode.AUTO일 경우에는 아래 예제처럼 문제가 되지 않습니다.
| // 가격을 1000 -> 2000원으로 변경 | |
| product.setPrice(2000); | |
| // 가격이 2000원인 상품 조회 | |
| Product product2 = em.createQuery("SELECT p FROM Product p WHERE p.price = 2000", Product.class) | |
| .getSingleResult(); |
부연 설명
- product.setPrice(2000)을 호출하면 영속성 컨텍스트의 상품 엔티티는 가격이 1000원에서 2000원으로 변경되지만 데이터베이스에는 1000원인 상태로 남아있음
- 다음으로 JPQL을 호출해서 가격이 2000원인 상품을 조회했는데 이때 플러시 모드를 따로 설정하지 않으면 플러시 모드가 AUTO이므로 쿼리 실행 직전에 영속성 컨텍스트가 플러시 됨
- 이에 따라 방금 2000원으로 수정한 상품을 조회할 수 있음
반면, 성능 최적화를 위해 FlushMode.COMMIT으로 변경했을 경우 주의를 하지 않으면 문제가 발생할 수 있습니다.
| em.setFlushMode(FlushModeType.COMMIT); | |
| // 가격을 1000원 -> 2000원으로 변경 | |
| product.setPrice(2000); | |
| // 1. em.flush() 직접 호출 | |
| em.flush(); | |
| // 2. 혹은 FlushMode를 AUTO로 변경한 뒤 JPQL 호출 | |
| Product product2 = em.createQuery("SELECT p FROM Product p WHERE p.price = 2000", Product.class) | |
| // .setFlushMode(FlushModeType.AUTO) | |
| .getSingleResult(); |
부연 설명
- 플러시 모드를 COMMIT으로 설정했으므로 쿼리를 실행할 때 플러시를 자동으로 호출하지 않음
- 만약 쿼리 실행 전에 플러시를 호출하고 싶을 경우
- em.flush()를 통해 수동으로 플러시 하거나
- setFlushMode()로 해당 쿼리에서만 사용할 플러시 모드를 AUTO로 변경하면 됨
3.2 플러시 모드와 최적화
- FlushModeType.COMMIT 모드는 트랜잭션을 커밋할 때만 플러시하고 쿼리를 실행할 때는 플러시하지 않으므로 JPA 쿼리를 사용할 때 영속성 컨텍스트에 있지만 아직 데이터베이스에 반영하지 않은 데이터를 조회할 수 없음
- 이런 상황은 잘못하면 데이터 무결성에 심각한 피해를 줄 수 있음
- 그럼에도 불구하고 플러시가 너무 자주 일어나는 상황에 해당 모드를 사용하면 쿼리 시 발생하는 플러시 횟수를 줄여서 성능을 최적화할 수 있음
| // FlushModeType.AUTO 비즈니스 로직 | |
| 등록(); | |
| 쿼리(); // 플러시 | |
| 등록(); | |
| 쿼리(); // 플러시 | |
| 등록(); | |
| 쿼리(); // 플러시 | |
| 커밋(); // 플러시 | |
| // FlushModeType.COMMIT 비즈니스 로직 | |
| 등록(); | |
| 쿼리(); | |
| 등록(); | |
| 쿼리(); | |
| 등록(); | |
| 쿼리(); | |
| 커밋(); // 플러시 |
JPA를 사용하지 않고 JDBC를 직접 사용해서 SQL을 실행할 때도 플러시 모드를 고민해야 합니다.
- JPA를 통하지 않고 JDBC로 쿼리를 직접 실행할 경우 JPA는 JDBC가 실행할 쿼리를 인식할 방법이 없음
- 따라서 별도의 JDBC 호출은 플러시 모드를 AUTO로 설정해도 플러시가 일어나지 않음
- 이때는 JDBC로 쿼리를 실행하기 직전에 em.flush()를 호출해서 영속성 컨텍스트의 내용을 데이터베이스에 동기화하는 것이 안전함
참고
자바 ORM 표준 JPA 프로그래밍 - 김영한 저
'DB > 자바 ORM 표준 JPA 프로그래밍' 카테고리의 다른 글
| [13장] 웹 애플리케이션과 영속성 관리 (0) | 2025.03.18 |
|---|---|
| [12장] 스프링 데이터 JPA (0) | 2025.03.15 |
| [9장] 값 타입 (0) | 2025.03.04 |
| [8장] 프록시와 연관관계 관리 (0) | 2025.03.01 |
| [7장] 고급 매핑 (0) | 2025.02.28 |