예외 처리
1. JPA 표준 예외 정리
- JPA 표준 예외들은 javax.persistence.PersistenceException의 자식 클래스이며 해당 예외 클래스는 RuntimeException의 자식
- 따라서 JPA 예외는 모두 UncheckedException
- JPA는 표준 예외는 크게 두 가지로 나눌 수 있음
- 트랜잭션 롤백을 표시하는 예외
- 트랜잭션 롤백을 표시하지 않는 예외
- 트랜잭션 롤백을 표시하는 예외는 심각한 예외이므로 복구해서는 안됨
- 해당 예외가 발생하면 트랜잭션을 강제로 커밋해도 트랜잭션이 커밋되지 않고 대신 javax.persistence.RollbackException 예외가 발생함

- 반면, 트랜잭션 롤백을 표시하지 않는 예외는 심각한 예외가 아님
- 따라서 개발자가 트랜잭션을 커밋할지 롤백할지 판단하면 됨

2. 스프링 프레임워크의 JPA 예외 변환
- 서비스 계층에서 데이터 접근 계층의 구현 기술에 직접 의존하는 것은 좋은 설계라 할 수 없음
- 이것은 예외도 마찬가지
- 서비스 계층에서 JPA의 예외를 직접 사용하면 JPA에 의존하게 되므로 스프링 프레임워크는 해당 문제를 해결하기 위해 데이터 접근 계층에 대한 예외를 추상화해서 개발자에게 제공

- 추가로 아래 표를 보면 JPA 표준 명세상 발생할 수 있는 다음 두 예외도 추상화해서 제공함

3. 스프링 프레임워크에 JPA 예외 변환기 적용
- JPA 예외를 스프링 프레임워크가 제공하는 추상화된 예외로 변경하려면 PersistenceExceptionTranslationPostProcessor를 스프링 빈으로 등록하면 됨
- 해당 빈은 @Repository 어노테이션을 사용한 곳에 예외 변환 AOP를 적용해서 JPA 예외를 스프링 프레임워크가 추상화된 예외로 변환해 줌
부연 설명
- 조회된 결과가 없어 javax.persistence.NoResultException 발생
- 해당 예외가 findMember() 메서드를 빠져나갈 때 PersistenceExceptionTranslationPostProcessor에서 등록한 AOP 인터셉터가 동작해서 해당 예외를 org.springframework.dao.EmptyResultDataAccessException 예외로 변환해서 반환함
4. 트랜잭션 롤백 주의사항
- 트랜잭션을 롤백하는 것은 DB의 반영사항만 롤백하는 것이지 수정한 자바 객체까지 원상태로 복구해주지 않음
- ex) 엔티티를 조회한 뒤 수정하는 중 문제가 발생하여 트랜잭션을 롤백하면 DB의 데이터는 원래대로 복구되지만 객체는 수정된 상태로 영속성 컨텍스트에 남아 있음
- 따라서 트랜잭션이 롤백된 영속성 컨텍스트를 그대로 사용하는 것은 위험
- 트랜잭션 롤백한 뒤 새로운 영속성 컨텍스트를 생성해서 사용하거나 EntityManager.clear()를 호출해서 영속성 컨텍스트를 초기화한 후 사용하는 것을 권장
- 스프링 프레임워크는 위 문제를 예방하기 위해 영속성 컨텍스트의 범위에 따라 다른 방법을 사용함
- 기본 전략인 트랜잭션 당 영속성 컨텍스트 전략: 문제가 발생하면 트랜잭션 AOP 종료 시점에 트랜잭션을 롤백하면서 영속성 컨텍스트도 함께 종료하므로 문제가 발생하지 않음
- OSIV: 영속성 컨텍스트의 범위를 트랜잭션 범위보다 넓게 사용해서 여러 트랜잭션이 하나의 영속성 컨텍스트를 사용할 때 트랜잭션 롤백 시 영속성 컨텍스트에 이상이 발생해도 다른 트랜잭션에서 해당 영속성 컨텍스트를 그대로 사용하는 문제 발생, 스프링 프레임워크는 영속성 컨텍스트의 범위를 트랜잭션의 범위보다 넓게 설정하면 트랜잭션 롤백 시 영속성 컨텍스트를 초기화해서 잘못된 영속성 컨텍스트를 사용하는 문제를 예방
엔티티 비교
- 영속성 컨텍스트 내부에는 엔티티 인스턴스를 보관하기 위한 1차 캐시가 있으며 1차 캐시는 영속성 컨텍스트와 생명주기를 같이 함
- 영속성 컨텍스트를 통해 데이터를 저장하거나 조회하면 1차 캐시에 엔티티가 저장되며 해당 캐시 덕분에 변경 감지 기능도 동작하고 캐시로 사용되어서 DB를 통하지 않고 데이터를 빠르게 조회 가능
- 영속성 컨텍스트를 정확히 이해하기 위해서는 1차 캐시의 가장 큰 장점인 애플리케이션 수준의 반복 가능한 읽기를 이해해야 함
- 같은 영속성 컨텍스트에서 엔티티를 조회하면 항상 같은 엔티티 인스턴스를 반환함
- 단순히 동등성 (equals) 비교 수준이 아니라 정말 주소값이 같은 인스턴스를 반환함
1. 영속성 컨텍스트가 같을 때 엔티티 비교

부연 설명
- 테스트 클래스에 @Transactional이 선언되어 있으면 트랜잭션을 먼저 시작하고 테스트 메서드를 실행하므로 회원가입() 메서드는 이미 트랜잭션 범위에 들어 있고 메서드가 끝나면 트랜잭션이 종료됨
- 회원가입()에서 사용된 코드는 위 사진처럼 항상 같은 트랜잭션과 같은 영속성 컨텍스트에 접근함
- 위 코드에서 흥미로운 점은 저장한 회원과 회원 레포지토리에서 조회한 엔티티가 완전히 같은 인스턴스라는 점
- 같은 트랜잭션 범위에 있으므로 같은 영속성 컨텍스트를 사용하기 때문에 완전히 같은 인스턴스
- 영속성 컨텍스트가 같으면 엔티티를 비교할 때 다음 세 가지 조건을 모두 만족함
- 동일성 (Identical): == 비교가 같음
- 동등성 (Equinalent): equals() 비교가 같음
- 데이터베이스 동등성: @Id인 데이터베이스 식별자가 같음
2. 영속성 컨텍스트가 다를 때 엔티티 비교
- 테스트 클래스에 @Transactional이 없고 서비스에만 @Transactional이 있을 경우 트랜잭션 범위와 영속성 컨텍스트 범위를 가지게 됨
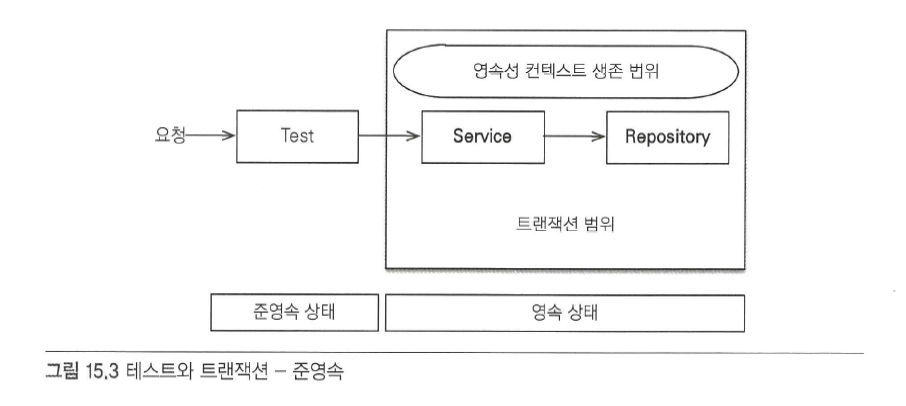
코드 실행 결과
- 테스트 코드에서 memberService.join(member)를 호출해서 회원가입을 시도하면 서비스 계층에서 트랜잭션이 시작되고 영속성 컨텍스트1이 생성됨
- memberRepository에서 em.persist()를 호출해서 member 엔티티를 영속화
- 서비스 계층이 끝날 때 트랜잭션이 커밋되면서 영속성 컨텍스트가 flush 됨
- 이때 트랜잭션과 영속성 컨텍스트가 종료되므로 member 엔티티 인스턴스는 준영속 상태가 됨
- 테스트 코드에서 memberRepository.findOne(saveId)를 호출해서 저장한 엔티티를 조회하면 레포지토리 계층에서 새로운 트랜잭션이 시작되면서 새로운 영속성 컨텍스트2가 생성됨
- 저장된 회원을 조회하지만 새로 생성된 영속성 컨텍스트2에는 찾은 회원이 존재하지 않으므로 데이터베이스에서 회원을 찾아옴
- 데이터베이스에서 조회된 회원 엔티티를 영속성 컨텍스트에 보관하고 반환함
- memberRepository.findOne() 메서드가 끝나면서 트랜잭션이 종료되고 영속성 컨텍스트2도 종료됨

3. 정리
- 같은 영속성 컨텍스트를 보장하면 동일성 비교만으로 충분하므로 OSIV처럼 요청의 시작부터 끝까지 같은 영속성 컨텍스트를 사용할 때 동일성 비교 성공
- 하지만 앞선 예제처럼 영속성 컨텍스트가 달라지면 동일성 비교는 실패하므로 다음과 같은 방법을 권장
- 데이터베이스 동등성 비교: 엔티티를 영속화하기 전에는 식별자 값이 null이므로 엔티티를 영속화해야 식별자를 얻을 수 있다는 문제가 있음
- equals()를 사용한 동등성 비교: 엔티티를 비교할 때는 비즈니스 키를 활용한 동등성 비교 권장 (단, 비즈니스 키가 되는 필드는 중복되지 않고 거의 변하지 않는 데이터베이스 기본 키 후보들)
프록시 심화 주제
- 프록시는 원본 엔티티를 상속받아서 만들어지므로 엔티티를 사용하는 클라이언트는 엔티티가 프록시인지 아니면 원본 엔티티인지 구분하지 않고 사용 가능
- 이에 따라 원본 엔티티를 사용하다가 지연 로딩을 하려고 프록시를 변경해도 클라이언트의 비즈니스 로직을 수정하지 않아도 됨
- 하지만 프록시를 사용하는 방식의 기술적인 한계로 인해 예상하지 못한 문제들이 발생하기도 하므로 어떤 문제가 발생하고 해당 문제를 어떻게 해결하는지 익힐 필요가 있음
1. 영속성 컨텍스트와 프록시
- 앞서 설명했다시피 영속성 컨텍스트는 자신이 관리하는 영속 엔티티의 동일성을 보장함
- 영속성 컨텍스트는 프록시로 조회된 엔티티에 대해서 같은 엔티티를 찾는 요청이 오면 원본 엔티티가 아닌 처음 조회된 프록시를 반환함
- 따라서 프록시로 조회해도 영속성 컨텍스트는 영속 엔티티의 동일성을 보장함
부연 설명
- member1을 em.getReference() 메서드를 사용해서 프록시로 조회했으므로 refMember은 프록시
- 다음으로 member1을 em.find()를 사용해서 조회했으므로 findMember는 원본 엔티티
- 앞서 설명했다시피 영속성 컨텍스트는 프록시로 조회된 엔티티에 대해 같은 엔티티를 찾는 요청이 오면 원본 엔티티가 아닌 처음 조회된 프록시를 반환함
- 위 코드에서 member1 엔티티를 프록시로 처음 조회했기 때문에 이후에 em.find()를 사용해서 같은 member1 엔티티를 찾아도 영속성 컨텍스트는 원본이 아닌 프록시를 반환함
- 로그로 찍힌 타입을 보면 끝에 `$$_jvst843_0`가 붙어있으므로 프록시가 조회된 것을 확인 가능
부연 설명
- 앞선 예제와 달리 원본 엔티티를 먼저 조회하고 나서 프록시를 조회
- 원본 엔티티를 먼저 조회하면 영속성 컨텍스트는 원본 엔티티를 이미 DB에서 조회했으므로 프록시를 반환할 이유가 없음
- 따라서 em.getReference()를 호출해도 프록시가 아닌 원본을 반환
- 출력 결과를 보면 프록시가 아닌 원본 엔티티가 반환된 것을 확인할 수 있으며 이때도 동등성이 보장되는 것을 확인 가능
2. 프록시 타입 비교
- 프록시는 원본 엔티티를 상속받아서 생성되므로 프록시로 조회한 엔티티의 타입을 비교할 때는 == 비교를 하면 안 되고 instanceof를 사용해야 함
부연 설명
- refMember의 타입을 출력해 보면 프록시로 조회했으므로 출력 결과 끝에 프록시라는 의미의 `_$$_jvsteXXX`가 붙어 있는 것을 확인 가능
- Member.class == refMember.getClass() 비교는 부모 클래스와 자식 클래스를 == 비교한 것이 되므로 결과는 false
- 앞서 설명했다시피 프록시는 원본 엔티티의 자식 타입이므로 instanceof 연산을 사용해야 함
3. 프록시 동등성 비교
- 엔티티의 동등성을 비교하려면 비즈니스 키를 사용해서 equals() 메서드를 오버라이딩하고 비교하면 됨
- 하지만 IDE나 외부 라이브러리를 사용해서 구현한 equals() 메서드로 엔티티를 비교할 때, 비교 대상이 원본 엔티티면 문제가 없지만 프록시면 문제가 발생할 수 있음
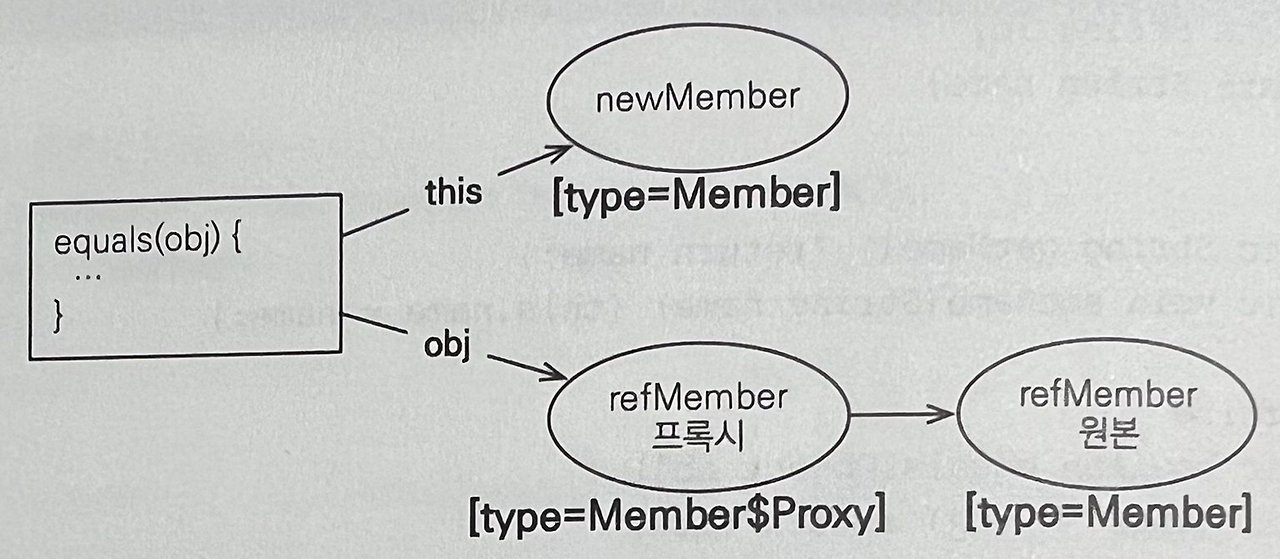
부연 설명
- 새로 생성한 회원 newMember와 프록시로 조회한 회원 refMember의 name 속성은 둘 다 회원1로 같으므로 동등성 비교 성공을 예상했지만 실패하며 테스트 실패
- 프록시가 아닌 원본 엔티티를 조회해서 비교하면 성공함
- 프록시와 equals() 비교를 할 때는 몇 가지 주의점이 있음
- equals() 메서드 내 `if (this.getClass() != obj.cgetClass())`와 같이 ==으로 동등성 비교를 하는 코드가 있는데 앞서 이야기했다시피 프록시는 원본을 상속받은 자식 타입이므로 프록시의 타입을 비교할 때는 == 비교가 아닌 instanceof를 사용해야 함
- 메서드를 구현할 때는 일반적으로 멤버변수를 직접 비교하는데, 프록시의 경우는 문제가 됨, 프록시는 실제 데이터를 가지고 있지 않으므로 member.name과 같이 멤버변수에 직접 접근하면 아무값도 조회할 수 없음
- 따라서 getName()과 같은 Getter 메서드를 통해 데이터를 조회해야 함
주의점을 숙지하고 equals() 메서드를 수정한 결과는 다음과 같습니다.
4. 상속관계와 프록시
- 프록시를 부모 타입으로 조회하면 문제가 발생함
- 프록시를 부모 타입으로 조회할 경우 부모의 타입을 기반으로 프록시가 생성되므로 다음과 같은 문제 발생
- instanceof 연산을 사용할 수 없음
- 하위 타입으로 다운캐스팅 할 수 없음

문제가 발생하는 이유
- em.getReference() 메서드를 사용해서 Item 엔티티를 프록시로 조회했는데 실제 조회된 엔티티는 Book이므로 Book 타입을 기반으로 원본 엔티티 인스턴스가 생성됨
- 그런데 em.getReference() 메서드에서 Item 엔티티를 대상으로 조회했으므로 프록시인 proxyItem은 Item 타입을 기반으로 만들어지므로 프록시 클래스는 원본 엔티티로 Book 엔티티를 참조함
- 로그와 위 그림을 보면 proxyItem이 Book이 아닌 Item 클래스를 기반으로 생성된 것을 확인 가능
- 프록시인 proxyItem은 Item$Proxy 타입이고 해당 타입은 Book 타입과 관계가 없기 때문에 예상과 달리 저자가 출력이 안됨
- 또, proxyItem은 Book 타입이 아닌 Item 타입을 기반으로 한 Item$Proxy 타입이기 때문에 직접 다운캐스팅을 했다면 ClassCastException 예외가 발생했을 것
상속관계에서 발생하는 프록시 문제를 해결하는 방법은 다음과 같습니다.
- JPQL로 대상 직접 조회
- 프록시 벗기기
- 기능을 위한 별도 인터페이스 제공
- 비지터 패턴 사용
가. JPQL로 대상 직접 조회
- 가장 간단한 방법은 처음부터 자식 타입을 직접 조회해서 필요한 연산을 하면 됨
- 대신 해당 방법을 사용하면 다형성을 활용할 수 없음
나. 프록시 벗기기
- 하이버네이트가 제공하는 기능을 사용하면 프록시에서 원본 엔티티를 가져올 수 있음
- 영속성 컨텍스트는 영속 엔티티의 동일성 보장을 위해 그리고 클라이언트가 조회한 엔티티가 프록시 여부와 상관없이 사용할 수 있도록 한 번 프록시로 노출한 엔티티는 계속 프록시로 노출시킴
- 하지만 해당 방법은 프록시에서 원본 엔티티를 직접 꺼내기 때문에 프록시와 원본 엔티티의 동일성 비교가 실패한다는 문제점이 있음
- 이 방법을 사용할 때는 원본 엔티티가 꼭 필요한 곳에서 잠깐 사용하고 다른 곳에서 사용되지 않도록 하는 것이 중요
다. 기능을 위한 별도의 인터페이스 제공
다음과 같은 클래스가 있다고 가정하고 특정 기능을 제공하는 인터페이스를 사용해 보겠습니다.

부연 설명
- TitleView라는 공통 인터페이스를 만들고 자식 클래스들은 인터페이스의 getTitle() 메서드를 각각 구현
- 따라서 OrderItem에서 Item.getTitle()을 호출하면 Item의 구현체에 따라 각각 다른 getTitle() 메서드가 호출됨
- 이처럼 인터페이스를 제공하고 각각의 클래스가 자신에 맞는 기능을 구현하는 것은 다형성을 활용하는 좋은 방법
- 이후 다양한 상품이 추가되어도 Item을 사용하는 OrderItem의 코드는 수정하지 않아도 됨
- 해당 방법은 클라이언트 입장에서 대상 객체가 프록시인지 아닌지를 고민하지 않아도 되는 장점이 있음
- 해당 방법을 사용할 때는 프록시의 특징 때문에 프록시의 대상이 되는 타입에 인터페이스를 적용해야 함
- Item이 프록시의 대상이므로 Item이 인터페이스를 받아야 함
라. 비지터 패턴 사용
- 비지터 패턴은 Visitor와 Visitor를 받아들이는 대상 클래스로 구성됨
- 여기서는 Item이 accept(visitor) 메서드를 사용해서 Visitor를 받아들임
- 그리고 Item은 단순히 Visitor를 받아들이기만 하고 실제 로직은 Visitor가 처리함
- 각각의 자식 클래스들은 부모에 정의한 accept(visitor) 메서드를 구현했는데, 구현 내용은 단순히 파라미터로 넘어온 Visitor의 visit(this) 메서드를 호출하면서 자식(this)을 파라미터로 넘기는 것이 전부
- 즉, 실제 로직 처리를 visitor에 위임함

비지터 패턴 실행
부연 설명
- 먼저 item.accept() 메서드를 호출하면서 파라미터로 PrintVisitor를 넘겨주었음
- item은 프록시이므로 먼저 프록시 (ProxyItem)가 accept() 메서드를 받고 원본 엔티티 (book)의 accept()를 실행
- 원본 엔티티는 `visitor.visit(this);`를 실행해서 자신을 visitor에 파라미터로 넘겨줌
- visitor가 PrintVisitor 타입이므로 PrintVisitor.visit(this) 메서드가 실행되는데 이때 this가 Book 타입이므로 visit(Book book) 메서드가 실행됨
비지터 패턴과 확장성
- PrintVisitor 대신 TitleVisitor를 파라미터로 넘기면 출력 결과는 다음과 같음
- book.class = com.tistory.jaimemin.item.Book
- TITLE=[제목:jpabook 저자:kim]
- 이처럼 비지터 패턴은 새로운 기능이 필요할 때 Visitor만 추가하면 됨
- 따라서 기존 코드의 구조를 변경하지 않고 기능을 추가할 수 있는 장점이 있음
비지터 패턴 정리
비지터 패턴의 장점을 정리하면 다음과 같습니다.
- 프록시에 대한 걱정 없이 안전하게 원본 엔티티에 접근할 수 있음
- instanceof와 타입캐스팅 없이 코드 구현 가능
- 알고리즘과 객체 구조를 분리해서 구조를 수정하지 않고 새로운 동작을 추가할 수 있음
비지터 패턴의 단점을 정리하면 다음과 같습니다.
- 너무 복잡하고 더블 디스패치를 사용하기 때문에 이해하기 어려움
- 객체가 두 번의 메서드 호출을 통해 자신에게 적합한 메서드를 결정하고 실행한다는 것을 의미
- 객체 구조가 변경되면 모든 Visitor를 수정해야 함
성능 최적화
1. N + 1 문제
- JPA로 애플리케이션을 개발할 때 성능상 가장 주의해야 하는 것이 N + 1 문제
N + 1 문제 관련해서는 다음 예제를 통해 설명하겠습니다.
- 회원과 주문정보는 1:N, N:1 양방향 연관관계
- 회원이 참조하는 주문정보인 Member.orders는 즉시 로딩으로 설정
1.1 즉시 로딩과 N + 1
- 즉시 로딩으로 설정했기 때문에 특정 회원 하나를 em.find() 메서드로 조회하면 주문정보도 함께 조회됨
- 여기서 함께 조회하는 방법이 중요한데 SQL을 두 번 실행하는 것이 아니라 조인을 사용해서 한 번의 SQL로 회원과 주문정보를 함께 조회함
- 이렇게 보면 즉시 로딩이 좋아 보이지만 문제는 JPQL을 사용할 때 발생함
- JPQL을 실행하면 JPA는 이것을 JPQL을 분석해서 SQL을 생성하는데 이때 즉시 로딩과 지연 로딩에 대해서 상관하지 않고 JPQL만 사용해서 SQL을 생성함
문제점
- 조회된 회원이 하나일 경우 총 두 번의 SQL을 실행하지만
- 조회된 회원이 N명일 경우 회원 조회 SQL로 N명의 회원 엔티티를 조회한 뒤 조회한 각각의 회원 엔티티와 연관된 주문 컬렉션을 즉시 조회하기 위해 총 N번의 SQL을 추가로 실행
- 이처럼 처음 실행한 SQL의 결과 수만큼 추가로 SQL을 실행하는 것을 N + 1 문제라고 지칭
이처럼 즉시 로딩은 JPQL을 실행할 때 N + 1 문제를 발생시킬 수 있습니다.
1.2 지연 로딩과 N + 1
- 앞서 회원과 주문 관계를 지연 로딩으로 설정하면 N + 1 문제가 해결될 것 같지만 이 역시 N + 1 문제에서 자유로울 수 없음
- 지연 로딩으로 설정하면 JPQL에서는 N + 1 문제가 발생하지 않음
- 하지만 이후 비즈니스 로직에서 주문 컬렉션을 실제 사용할 때 지연 로딩이 발생함
문제점
- 지연 로딩으로 설정하면 JPQL에서는 N + 1 문제가 발생하지 않지만 이후 비즈니스 로직에서 주문 컬렉션을 초기화하는 수만큼 SQL이 실행될 수 있음
- 회원이 N명이면 회원에 따른 주문도 N번 조회됨
- 이것도 결국 N + 1 문제
1.3 N + 1 문제의 해결책: 페치 조인
- N + 1 문제를 해결하는 가장 일반적인 방법은 페치 조인을 사용하는 것
- 페치 조인은 SQL 조인을 사용해서 연관된 엔티티르 함께 조회하므로 N + 1 문제가 발생하지 않음
1.4 N + 1 문제의 해결책: 하이버네이트 @BatchSize
- 하이버네이트가 제공하는 org.hibernate.annotations.Batchsize 어노테이션을 사용하면 연관된 엔티티를 조회할 때 지정한 size만큼 SQL의 IN 절을 사용해서 조회함
- 만약 조회한 회원이 10명인데 size를 5로 설정하면 두 번의 SQL만 추가로 실행함
부연 설명
- 즉시 로딩으로 설정 시 조회 시점에 10건의 데이터를 모두 조회해야 하므로 SQL이 두 번 실행됨
- 지연 로딩으로 설정 시 지연 로딩된 엔티티를 최초 사용하는 시점에 SQL을 실행해서 다섯 건의 데이터를 미리 로딩해 둠
- 여섯 번째 데이터를 사용하면 SQL을 추가로 실행
1.5 N + 1 문제의 해결책: 하이버네이트 @Fetch(FetchMode.SUBSELECT)
- 하이버네이트가 제공하는 org.hibernate.annotations.Fetch 어노테이션에 FetchMode를 SUBSELECT로 사용하면 연관된 데이터를 조회할 때 서브 쿼리를 사용해서 N + 1 문제를 해결함
1.6 N + 1 정리
- 즉시 로딩과 지연 로딩 중 권장하는 방법은 즉시 로딩을 사용하지 말고 지연 로딩만 사용하는 것
- 즉시 로딩 전략은 그럴듯해 보이지만 N + 1 문제는 물론이고 비즈니스 로직에 따라 필요하지 않은 엔티티를 로딩해야 하는 상황이 자주 발생함
- 즉시 로딩의 가장 큰 문제는 성능 최적화가 어렵다는 점
- 따라서 모두 지연 로딩으로 설정하고 성능 최적화가 꼭 필요한 곳에는 JPQL 페치 조인을 사용하는 것을 권장
2. 읽기 전용 쿼리의 성능 최적화
- 엔티티가 영속성 컨텍스트에 관리되면 1차 캐시부터 변경 감지까지 얻을 수 있는 혜택이 많음
- 그러나 영속성 컨텍스트는 변경 감지를 위해 스냅샷 인스턴스를 보관하기 때문에 더 많은 메모리를 사용하는 단점이 있음
- DB에서 찾은 내용을 출력하는 단순한 조회 화면이 있다고 가정했을 때 조회한 엔티티를 다시 조회할 일도 없고 수정할 일도 없이 딱 한 번만 읽어서 화면에 출력하면 됨
- 이때는 읽기 전용으로 엔티티를 조회하면 메모리 사용량을 최적화할 수 있음
다음 JPQL 쿼리를 최적화한다고 가정하고 설명하겠습니다.
SELECT o FROM Order o2.1 스칼라 타입으로 조회
- 가장 확실한 방법은 엔티티가 아닌 스칼라 타입으로 모든 필드를 조회하는 것
- 스칼라 타입은 영속성 컨텍스트가 결과를 관리하지 않음
SELECT o.id, o.name, o.price FROM Order o2.2 읽기 전용 쿼리 힌트 사용
- 하이버네이트 전용 힌트인 org.hibernate.readOnly를 사용하면 엔티티를 읽기 전용으로 조회 가능
- 읽기 전용이므로 영속성 컨텍스트는 스냅샷을 보관하지 않고 메모리 사용량을 최적화 가능
- 단, 스냅샷이 없으므로 엔티티를 수정해도 변경 감지가 동작하지 않아 DB에 반영되지 않음
2.3 읽기 전용 트랜잭션 사용
- 스프링 프레임워크를 사용하면 트랜잭션을 읽기 전용 모드로 설정 가능
- @Transactional(readOnly = true)
- 트랜잭션에 readOnly = true 옵션을 부여하면 스프링 프레임워크가 하이버네이트 세션의 플러시 모드를 MANUAL로 설정
- 이렇게 하면 강제로 flush를 호출하지 않는 한 flush가 일어나지 않으므로 트랜잭션을 커밋해도 영속성 컨텍스트를 flush하지 않음
- 영속성 컨텍스트를 flush 하지 않으니 엔티티의 등록, 수정 및 삭제는 당연히 동작하지 않고 flush 할 때 일어나는 스냅샷 비교와 같은 무거운 로직들을 수행하지 않으므로 성능이 향상됨
- 영속성 컨텍스트를 flush 하지 않을 뿐 트랜잭션을 시작했으므로 트랜잭션 시작, 로직 수행, 그리고 트랜잭션 커밋의 과정은 이루어짐
2.4 트랜잭션 밖에서 읽기
- 트랜잭션 밖에서 읽는다는 것은 트랜잭션 없이 엔티티를 조회했다는 뜻
- 데이터 변경을 위해서는 트랜잭션이 필수이므로 반드시 조회에서만 사용해야 함
- 스프링 프레임워크를 사용하면 다음처럼 설정해야 함
- @Transactional(propagation = Propagation.NOT_SUPPORTED)
- 이렇게 트랜잭션을 사용하지 않으면 flush가 일어나지 않으므로 조회 성능이 향상됨
2.5 정리
- 스프링 프레임워크를 사용하면 읽기 전용 트랜잭션을 사용하는 것이 편리함
- 따라서 읽기 전용 트랜잭션과 읽기 전용 쿼리 힌트를 동시에 사용하는 것이 가장 효과적
3. 배치 처리
- 수백만 건의 데이터를 배치 처리해야 하는 상황이 있다고 가정
- 일반적인 방식으로 엔티티를 지속적으로 조회할 경우 영속성 컨텍스트에 아주 많은 엔티티가 쌓이면서 OOM 에러가 발생할 것
- 따라서 이런 배치 처리는 적절한 단위로 영속성 컨텍스트를 초기화해야 하며 2차 캐시를 사용 중이라면 2차 캐시에서 엔티티를 보관하지 않도록 주의해야 함
3.1 JPA 등록/수정 배치
- 수만 건 이상의 엔티티를 한 번에 등록할 때 주의할 점은 영속성 컨텍스트에 엔티티가 계속 쌓이지 않도록 일정 단위마다 영속성 컨텍스트의 엔티티를 DB에 flush 하고 영속성 컨텍스트를 초기화해야 함
- 수정 배치 처리의 경우 아주 많은 데이터를 조회해서 수정을 진행하는데 이때 수많은 데이터를 한 번에 메모리에 올려둘 수 없어서 주로 두 가지 방법을 사용
- 페이징 처리: 데이터베이스 페이징 기능 사용
- 커서: 데이터베이스가 지원하는 커서 기능 사용
3.2 JPA 페이징 배치 처리
부연 설명
- 한 번에 100건씩 페이징 쿼리로 조회하면서 상품의 가격을 100원씩 증가시키며 페이지 단위마다 영속성 컨텍스트를 flush하고 초기화
3.3 하이버네이트 sroll 사용
- JPA는 JDBC 커서를 지원하지 않으므로 커서를 사용하기 위해서는 하이버네이트 세션을 사용해야 함
- 하이버네이트는 scroll이라는 이름으로 JDBC 커서를 지원
부연 설명
- scroll은 하이버네이트 전용 기능이므로 먼저 em.unwrap() 메서드를 사용해서 하이버네이트 세션을 구한 뒤 쿼리를 조회하면서 scroll() 메서드로 ScrollableResults 객체를 반환받음
- 해당 객체의 next() 메서드를 호출하면 엔티티를 하나씩 조회 가능
3.4 하이버네이트 무상태 세션 사용
- 무상태 세션은 영속성 컨텍스트를 만들지 않고 심지어 2차 캐시도 사용하지 않음
- 무상태 세션은 영속성 컨텍스트가 없음
- 따라서 엔티티를 수정하려면 무상태 세션이 제공하는 update() 메서드를 직접 호출해야 함
4. 트랜잭션을 지원하는 쓰기 지연과 성능 최적화
4.1 트랜잭션을 지원하는 쓰기 지연과 JDBC 배치
- SQL을 직접 다루는 경우 네트워크 호출 한 번은 단순한 메서드를 수만 번 호출하는 것보다 더 큰 비용이 듦
- 따라서 네트워크 호출을 최대한 줄여야 함
- INSERT SQL이 여러 번 호출되는 메서드일 경우 INSERT SQL을 모아서 한 번에 DB로 보내면 됨
- JDBC가 제공하는 SQL 배치 기능을 사용하면 SQL을 모아서 DB에 한 번에 보낼 수 있지만 해당 기능을 JPA를 사용하는 애플리케이션에 적용하려면 코드의 많은 부분을 수정해야 함
- 그래서 보통은 수백 수천 건 이상의 데이터를 변경하는 특수한 상황에 SQL 배치 기능을 사용함
- JPA는 flush 기능이 있으므로 SQL 배치 기능을 효과적으로 사용 가능
- SQL 배치 최적화 전략은 구현체마다 조금씩 다름
- 하이버네이트에서 SQL 배치를 적용하려면 `<property name = hibernate.jdbc.batch_size", value="50" />`과 같이 설정하면 되며 이렇게 설정할 경우 데이터를 등록, 수정, 그리고 삭제할 때 하이버네이트가 SQL 배치 기능을 사용함
- 예시와 같이 hibernate.jdbc.batch_size 속성의 값을 50으로 부여하면 최대 50건씩 모아서 SQl 배치를 실행하지만 SQL 배치는 같은 SQL일 때만 유효함 (중간에 다른 처리가 들어가면 SQL 배치를 다시 시작함)
주의: 엔티티가 영속 상태가 되기 위해서는 식별자가 필요한데 IDENTITY 식별자 생성 전략은 엔티티를 DB에 저장해야 식별자를 구할 수 있기 때문에 em.persist()를 호출하는 즉시 INSERT SQL이 데이터베이스에 전달됨, 따라서 쓰기 지연을 활용한 성능 최적화를 할 수 없습니다.
4.2 트랜잭션을 지원하는 쓰기 지연과 애플리케이션 확장성
- 트랜잭션을 지원하는 쓰기 지연과 변경 감지 기능 덕분에 성능과 개발 편의성이라는 두 마리 토끼를 모두 잡을 수 있었음
- 하지만 진짜 장점은 DB 테이블 로우에 락이 걸리는 시간을 최소화한다는 점
- 해당 기능은 트랜잭션을 커밋해서 영속성 컨텍스트를 flush 하기 전까지는 DB에 데이터를 등록, 수정, 삭제하지 않으므로 커밋 직전까지 DB 로우에 락을 걸지 않음
위 로직을 통해 부연 설명을 진행하겠습니다.
- JPA를 사용하지 않고 SQL을 직접 다룰 경우 `update(memberA)`를 호출할 때 UPDATE SQL을 실행하면서 DB 테이블 로우에 락을 검
- 해당 락은 businessLogicA()와 businessLogicB()를 모두 수행하고 commit()을 호출할 때까지 유지됨
- 트랜잭션 격리 수준에 따라 다르지만 통상적으로 사용하는 Read Committed 격리 수준이나 그 이상에서는 DB에 현재 수정 중인 데이털르 수정하려는 다른 트랜잭션은 락이 풀릴 때까지 대기함
- JPA는 커밋을 해야 flush를 호출하고 DB에 수정 쿼리를 보냄
- 예제에서 commit()을 호출할 때 UPDATE SQL을 실행하고 바로 DB 트랜잭션을 커밋함
- 쿼리를 보내고 바로 트랜잭션을 커밋하므로 결과적으로 DB에 락이 걸리는 시간을 최소화함
참고
자바 ORM 표준 JPA 프로그래밍 - 김영한 저
'DB > 자바 ORM 표준 JPA 프로그래밍' 카테고리의 다른 글
| [16장] 트랜잭션과 락 (0) | 2025.03.22 |
|---|---|
| [14장] 컬렉션과 부가 기능 (0) | 2025.03.19 |
| [13장] 웹 애플리케이션과 영속성 관리 (0) | 2025.03.18 |
| [12장] 스프링 데이터 JPA (0) | 2025.03.15 |
| [10장] 객체지향 쿼리 언어 (0) | 2025.03.09 |