개요
여태까지 엑셀 생성 및 다운로드 기능을 구현할 때 Apache Poi 라이브러리를 사용했었고 이와 관련하여 게시글을 여러 번 남겼습니다.
https://jaimemin.tistory.com/2069
[SpringBoot] 대용량 엑셀 파일 생성 및 다운로드 삽질기
개요 작년에 이어 올해도 엑셀 파일 생성 및 다운로드 기능을 담당하게 되었습니다. https://jaimemin.tistory.com/1889 [SpringBoot] 대용량 엑셀 다운로드를 위한 SXSSFWorkbook 개요 기존에 Excel 생성 및 다운..
jaimemin.tistory.com
Apache Poi 라이브러리가 보편적으로 사용됨에 따라 레퍼런스도 많고 주기적인 버전업이 이루어졌기 때문에 지금까지 해당 라이브러리를 사용해왔는데 몇 가지 단점이 발견됨과 동시에 현재 맡게 된 프로젝트 구조 변경을 논의하기 시작하면서 fastexcel 라이브러리를 도입하는 것을 고려하게 됐습니다.
이번 게시글에서는 fastexcel 라이브러리의 장단점, Apache Poi 라이브러리의 장단점, 각각의 샘플 코드, 그리고 현재 프로젝트 구조의 경우 어떤 라이브러리를 쓰는 것이 적합한지에 대해 정리하겠습니다.
1. 프로젝트 구조 및 fastexcel을 고려하게 된 계기
기존에는 OOM(Out Of Memory Exception)을 확실하게 방지하기 위해 파일 관련 처리를 별도 인스턴스에서 진행했습니다.
그리고 NAS가 마운트 되어 있어 파일을 자유롭게 저장하고 불러올 수 있었습니다.
이해를 돕기 위해 기존 프로젝트 구조를 개요에서 언급한 게시글에서 가지고 왔습니다.
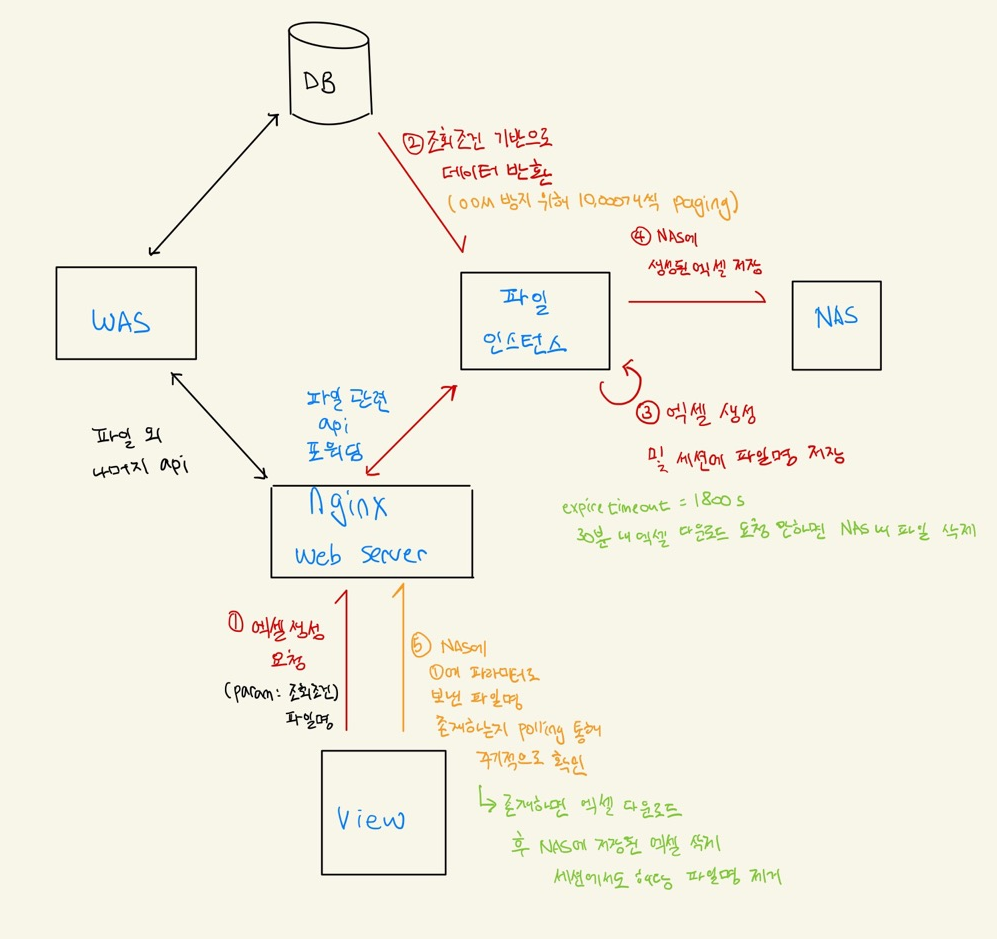
기존 프로젝트에서 대용량 엑셀 다운로드하는 방법을 간략하게 설명하자면 아래와 같습니다.
- Apache Poi 라이브러리의 경우 sheet.xml 파일을 임시 파일에 쓰기 때문에 response stream에 바로 XLSX 파일을 작성할 수 없고 Workbook을 생성 완료한 뒤 response stream에 내려줘야 하는 단점이 있습니다.
- 따라서, 대용량 엑셀 파일을 생성할 경우 default gateway timeout인 5분을 넘길 수 있으므로 동기식으로 처리하기 힘듭니다.
- 이에 따라 비동기 방식으로 처리하였고 클라이언트가 엑셀 다운로드 요청을 한 이후 long polling을 진행하는 동안 서버에서는 엑셀을 생성하고 NAS에 저장한 뒤, polling 요청이 올 때 파일이 생성 완료되었다고 응답을 보내고 파일 다운로드를 진행하는 방식으로 진행했습니다.
실제 서비스를 모니터링해보니 위와 같은 방식에는 크게 세 가지 단점이 있었습니다.
- long polling을 진행하기 때문에 클라이언트가 페이지를 벗어날 경우 polling 요청이 끊겨 엑셀 다운로드가 진행되지 않습니다.
- 또한, response stream에 바로 XLSX 파일을 작성할 수 없기 때문에 대용량 엑셀 다운로드 요청이 들어올 경우 다운로드 창이 나타나기까지 상당한 시간이 걸려 클라이언트가 현재 다운로드를 진행하고 있는지 파악하기 어려웠습니다.
- 다운로드가 안 되는 줄 알고 한 번 더 다운로드 버튼을 클릭하는 사용자도 있어 서버에 원치 않은 부하가 발생하기도 했습니다.
- 별도 storage가 없을 경우 WAS에 엑셀을 저장한 뒤 long polling 요청이 오면 다운로드를 진행해야 하는데 서버가 이중화되어 있을 경우 NFS, 리눅스 rsync, 혹은 FTP를 통해 파일을 동기화해줘야 하는 문제가 발생합니다.
- 동기화해주지 않을 경우 L4 Load Balancing에 의해 어떤 서버로 요청이 갈지 몰라 엑셀 다운로드 소요 시간이 길어질 수 있습니다.
- 프로젝트가 XaaS(Anything as a Service)여서 컨테이너에 올라가 있을 경우 컨테이너가 임의로 내려갔다 올라갈 수 있으므로 이와 같은 케이스에서는 비동기 방식을 사용할 수 없습니다. 컨테이너가 내려갔다 올라가는 과정에서 주소도 바뀌고 내부 데이터도 날아가기 때문에 생성된 엑셀 파일이 요청이 오기 전에 삭제되는 문제가 발생할 수 있습니다.
따라서, 저는 동기 방식으로 엑셀 생성 및 다운로드를 진행할 수 있게끔 response stream에 바로 XLSX 파일을 작성할 수 있는 라이브러리를 검색해봤고 dhatim님이 작성하신 fastexcel 라이브러리를 찾을 수 있었습니다.
https://github.com/dhatim/fastexcel
GitHub - dhatim/fastexcel: Generate and read big Excel files quickly
Generate and read big Excel files quickly. Contribute to dhatim/fastexcel development by creating an account on GitHub.
github.com
fastexcel의 경우 OutputStream을 매개변수로 받는 생성자가 있어 data streaming을 지원하여 엑셀 다운로드 요청이 오면 응답을 즉시 한 뒤 stream을 열어 엑셀에 데이터를 채우는 방식으로 진행되기 때문에 gateway timeout이 발생할 일이 없고 다운로드 창이 바로 나타나 더 나은 사용성을 제공합니다.

fastexcel을 이용한 엑셀 다운로드

Apache Poi를 이용한 엑셀 다운로드
2. fastexcel과 Apache Poi 성능 비교
fastexcel이 더 나은 사용성을 제공하지만 성능이 너무 떨어질 경우 현실적으로 사용하기 어렵습니다.
따라서, 저는 fastexcel 성능 체크를 위해 prometheus와 grafana를 연동하여 JVM Heap Memory 사용량 및 CPU 사용량을 체크했습니다.
row 개수는 10만, 50만, 100만 그리고 150만 기준으로 테스트했으며 칼럼 개수는 6개 그리고 20개 기준으로 테스트를 진행했고 할 때마다 결과가 조금씩 달라 각각 5번씩 테스트하여 평균값을 기준으로 결과를 도출하는 식으로 진행했습니다.
또한, 현재 코드 재사용을 위해 java.util.Map 객체를 사용하고 있는데 알고리즘 문제를 풀 때 Map이 메모리를 많이 먹는 것을 알고 있기 때문에 Map을 사용하는 버전과 사용하지 않는 버전에 대해 테스트를 진행했습니다.
prometheus와 grafana 연동 방법은 아래 게시글을 확인해주세요.
[SpringBoot] Prometheus, Grafana 연동하는 방법
개요 기존에 엑셀 다운로드 기능을 Apache POI 라이브러리를 통해 구현했는데 메모리도 많이 먹는 것 같고 non streaming 방식이라 streaming 방식인 fastexcel 라이브러리로 변경하려고 합니다. 기존 코드
jaimemin.tistory.com
JVM Heap Memory는 다운로드할 때 기준 최대 메모리를 GB 단위로 측정하였고 CPU 사용량은 다운로드할 때 기준 최대 system cpu 사용량을 기준으로 측정했습니다. 정리하고 보니 process cpu 사용량 기준으로 측정했어야 하는 것이 맞는 것 같지만... 전체적인 추이는 비슷하므로 넘어가겠습니다.
JVM Heap Memory Dashboard 예시
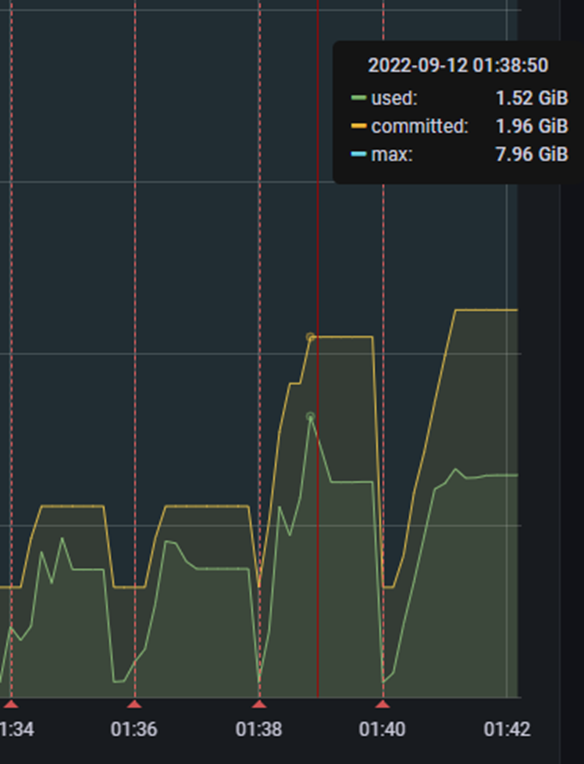
CPU 사용량 Dashboard 예시
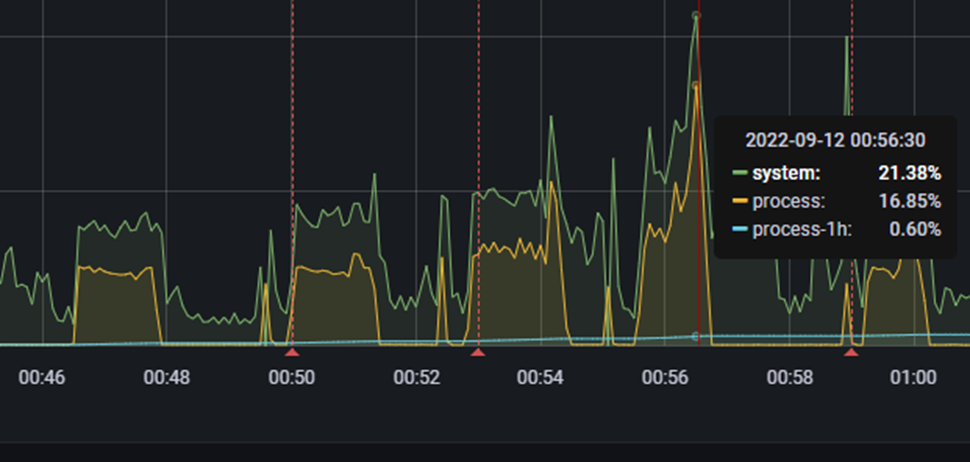
* 주의: 테스트 환경에 따라 결과가 상이할 수 있습니다. 아래 결과들은 제 로컬 pc에서 테스트한 결과입니다.
2.1 칼럼 6개 기준
우선, 칼럼 6개 기준 결과는 아래와 같습니다.
2.1.1 10만 row
map을 사용한 fastexcel
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 4 | 4 | 4 | 4 | 4 | 4 |
| Heap Memory | 0.24 | 0.27 | 0.2 | 0.25 | 0.28 | 0.25 |
| CPU 사용량 | 7.17 | 4.61 | 8.31 | 7.8 | 8.37 | 7.25 |
map을 사용하지 않은 fastexcel
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 4 | 4 | 4 | 4 | 4 | 4 |
| Heap Memory | 0.2 | 0.13 | 0.27 | 0.16 | 0.28 | 0.21 |
| CPU 사용량 | 8.15 | 7.37 | 7.26 | 8.09 | 7.1 | 7.6 |
map을 사용한 apache poi
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 4 | 4 | 5 | 4 | 4 | 4.2 |
| Heap Memory | 0.31 | 0.3 | 0.14 | 0.37 | 0.37 | 0.3 |
| CPU 사용량 | 3.56 | 2.76 | 4 | 2.78 | 3.38 | 3.3 |
map을 사용하지 않은 apache poi
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 5 | 4 | 4 | 4 | 4 | 4.2 |
| Heap Memory | 0.35 | 0.18 | 0.25 | 0.31 | 0.29 | 0.28 |
| CPU 사용량 | 5.3 | 5.2 | 6.76 | 5.54 | 4.54 | 5.47 |
2.1.2 50만 row
map을 사용한 fastexcel
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 22 | 27 | 23 | 22 | 22 | 23.2 |
| Heap Memory | 0.66 | 0.55 | 0.63 | 0.59 | 0.72 | 0.63 |
| CPU 사용량 | 8.82 | 6.61 | 8.46 | 9.3 | 8.64 | 8.37 |
map을 사용하지 않은 fastexcel
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 21 | 21 | 21 | 21 | 21 | 21 |
| Heap Memory | 0.68 | 0.47 | 0.63 | 0.55 | 0.65 | 0.6 |
| CPU 사용량 | 8.96 | 10.62 | 8.54 | 8.23 | 8.38 | 8.95 |
map을 사용한 apache poi
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 22 | 23 | 22 | 22 | 28 | 23.4 |
| Heap Memory | 0.42 | 0.41 | 0.5 | 0.56 | 0.43 | 0.46 |
| CPU 사용량 | 7.5 | 9.5 | 8.13 | 12.51 | 12.15 | 9.96 |
map을 사용하지 않은 apache poi
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 30 | 22 | 22 | 22 | 22 | 23.6 |
| Heap Memory | 0.61 | 0.58 | 0.86 | 0.6 | 0.65 | 0.66 |
| CPU 사용량 | 8.24 | 9.09 | 8.49 | 7.55 | 7.59 | 8.19 |
2.1.3 100만 row
map을 사용한 fastexcel
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 98 | 117 | 99 | 100 | 122 | 107.2 |
| Heap Memory | 0.94 | 0.94 | 0.91 | 0.96 | 0.88 | 0.93 |
| CPU 사용량 | 11.96 | 17.1 | 13.19 | 15.69 | 15.78 | 14.74 |
map을 사용하지 않은 fastexcel
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 98 | 95 | 96 | 98 | 99 | 97.2 |
| Heap Memory | 0.68 | 0.65 | 0.69 | 0.69 | 0.61 | 0.66 |
| CPU 사용량 | 9.88 | 12.01 | 12.38 | 12.66 | 11.1 | 11.61 |
map을 사용한 apache poi
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 96 | 100 | 98 | 98 | 99 | 98.2 |
| Heap Memory | 0.6 | 0.72 | 0.59 | 0.61 | 0.63 | 0.63 |
| CPU 사용량 | 12.6 | 10.6 | 7.2 | 8.49 | 9.12 | 9.60 |
map을 사용하지 않은 apache poi
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 98 | 98 | 99 | 98 | 98 | 98.2 |
| Heap Memory | 0.64 | 0.67 | 0.63 | 0.58 | 0.6 | 0.62 |
| CPU 사용량 | 9.24 | 9.11 | 13.19 | 10.37 | 9.94 | 10.37 |
2.1.4 150만 row (멀티 시트)
map을 사용한 fastexcel
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 162 | 162 | 126 | 127 | 125 | 140.4 |
| Heap Memory | 1.28 | 1.33 | 1.24 | 1.36 | 1.33 | 1.31 |
| CPU 사용량 | 15.7 | 15.99 | 22.01 | 18.14 | 17.17 | 17.8 |
map을 사용하지 않은 fastexcel
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 158 | 157 | 124 | 124 | 121 | 136.8 |
| Heap Memory | 0.94 | 0.95 | 0.96 | 0.96 | 1 | 0.96 |
| CPU 사용량 | 16.08 | 12.08 | 13.78 | 18 | 14.87 | 14.96 |
map을 사용한 apache poi
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 167 | 165 | 162 | 128 | 127 | 149.8 |
| Heap Memory | 0.87 | 0.87 | 0.87 | 0.87 | 0.83 | 0.86 |
| CPU 사용량 | 14.07 | 9.38 | 12.33 | 14.14 | 14.5 | 12.88 |
map을 사용하지 않은 apache poi
| 1회차 | 2회차 | 3회차 | 4회차 | 5회차 | 평균 | |
| 소요시간 | 162 | 163 | 178 | 128 | 129 | 152 |
| Heap Memory | 0.87 | 0.89 | 0.85 | 1.04 | 0.86 | 0.9 |
| CPU 사용량 | 14.99 | 9.75 | 13.4 | 11.74 | 18.02 | 13.58 |
2.1.5 평균값 추이
소요시간
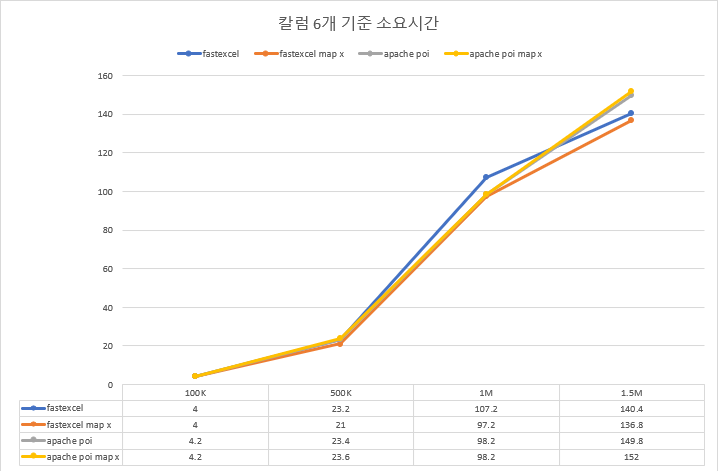
JVM Heap Memory
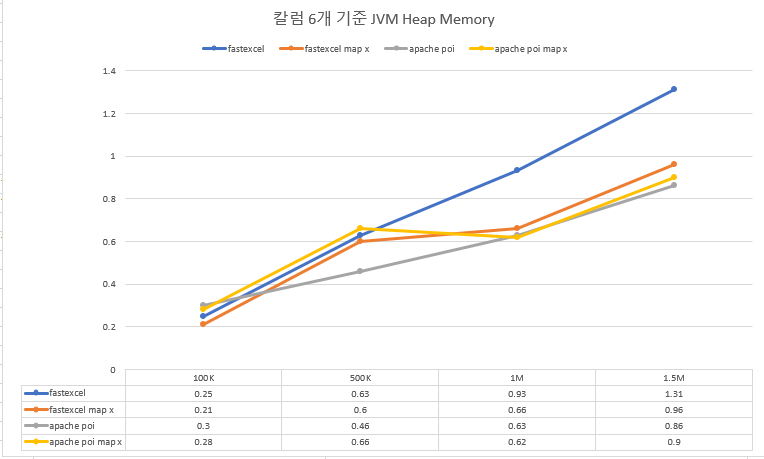
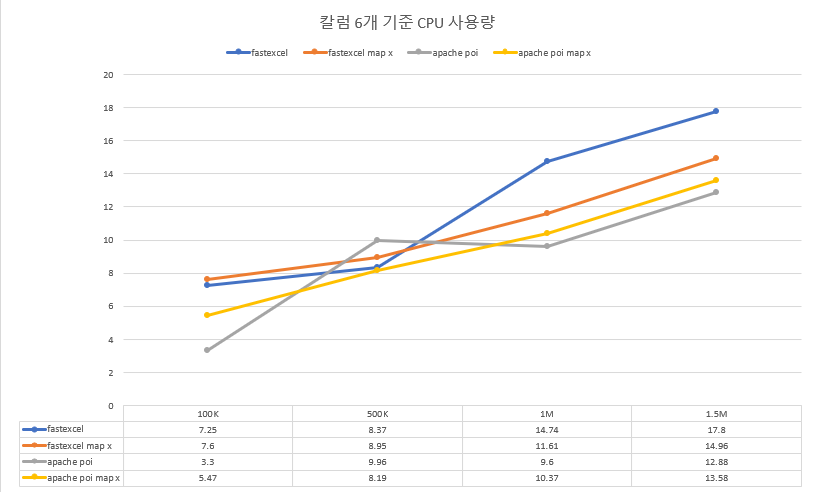
CPU 사용량
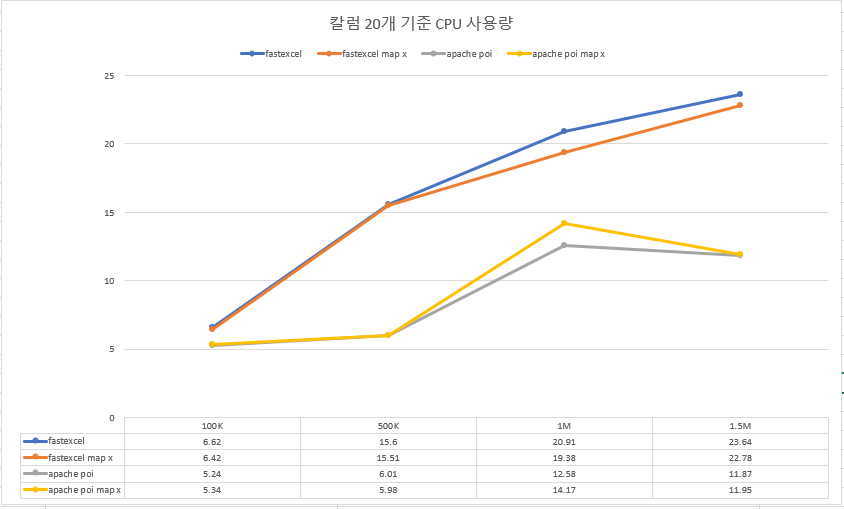
2.2 칼럼 20개 기준
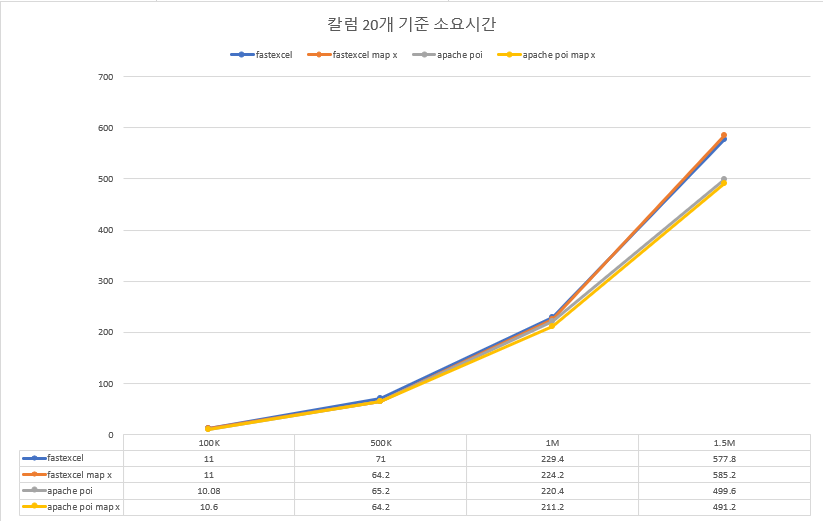
반복되는 내용이므로 칼럼 20개에 대해서는 평균값 추이만 확인하도록 하겠습니다.
소요시간
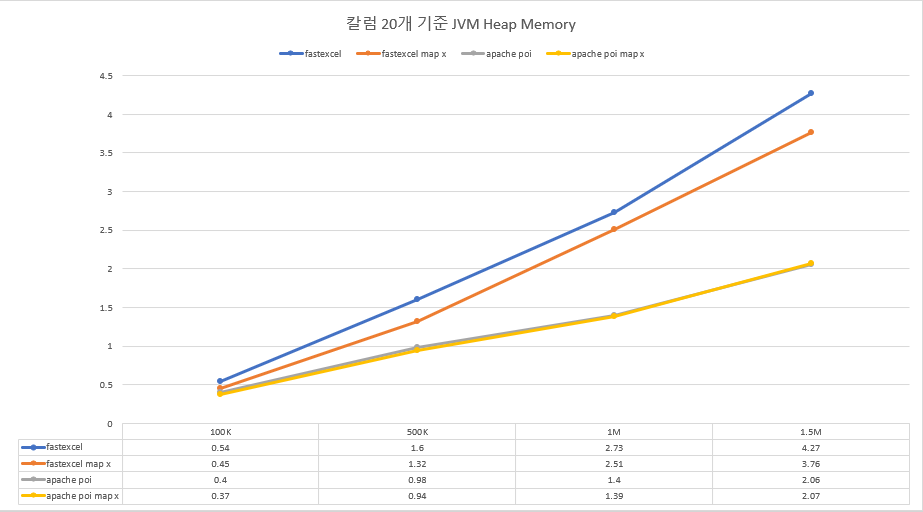
JVM Heap Memory
CPU 사용량
2.3 총 정리
여태까지의 내용을 정리하자면 아래와 같습니다.
- 작성하는 cell의 개수가 늘어나면 늘어날수록 Apache POI가 fastexcel보다 더 나은 성능을 보입니다.
- 특히, JVM 힙 메모리와 CPU 사용량 측면에서 Apache POI가 fastexcel보다 거의 두 배 나은 퍼포먼스를 보였습니다.
- Apache POI의 경우 Map 사용 여부와 관계없이 비슷한 성능을 보이는 반면 fastexcel의 경우 Map을 사용할 경우 사용하지 않은 경우보다 메모리, CPU 사용량 측면에서 열세를 보이는 것으로 확인할 수 있었으나 유의미한 차이인지는 잘 모르겠습니다.
2.4 fastexcel과 Apache POI 장단점
fastexcel 장점
- HTTP 요청에 대한 응답을 바로 내려주므로 gateway timeout error 발생하지 않습니다.
- response stream에 XLSX를 바로 작성하기 때문에 다운로드 창이 바로 뜹니다. (높은 사용성)
fastexcel 단점
- Apache POI보다 전체적인 성능에 열세를 보입니다.
- 버전이 아직 1점대가 아니고 업데이트 속도가 느립니다.
Apache POI 장점
- 버전업이 꾸준히 됩니다. (현재 5점대)
- JVM Heap Memory 관리를 잘하며 소요시간 및 CPU 사용량 측면에서도 성능이 우세합니다.
Apache POI 단점
- Workbook을 생성 완료한 뒤 response stream에 내려줄 수 있으므로 대용량 엑셀의 경우 default gateway timeout 시간을 늘려줘야 합니다.
- 다운로드 창이 늦게 뜨므로 사용성 측면에서 fastexcel에 비해 열세입니다.
3. 샘플 코드
fastexcel 깃헙 레포지토리 README에 잘 작성이 되어 있지만 자주 사용될 것 같은 기능 위주로 작성한 샘플 코드를 간단하게 작성해봤습니다.
전체 소스코드는 github에 올라와 있기 때문에 핵심적인 부분만 발췌해서 포스팅했습니다.
Controller
Service
보시면 알 수 있다시피 기존의 Apache POI와 다르게 fastexcel의 경우 AbstractXlsView를 상속받는 별도 View를 생성하지 않아도 되며 Row, Cell 객체를 생성할 필요 없이 좌표로 (x, y) 위치에 value를 넣으면 되는 방식으로 코드를 작성하면 됩니다.
또한, cell들을 range로 묶은 후 일괄적으로 style을 부여할 수 있어 코드를 보다 깔끔하게 작성할 수 있다는 장점이 있습니다.
그리고 앞서 언급했듯이 OutputStream을 인자로 받는 생성자가 있어 response stream에 XLSX를 바로 작성할 수 있어 사용성 측면에서 장점을 갖습니다.
성능을 비교하기 위해 fastexcel과 함께 Apache POI 그리고 csv 관련 소스도 작성했으므로 전체 소스 코드는 아래 레포지토리를 확인해주시면 감사하겠습니다.
https://github.com/jaimemin/SampleExcelDownloadProject
GitHub - jaimemin/SampleExcelDownloadProject
Contribute to jaimemin/SampleExcelDownloadProject development by creating an account on GitHub.
github.com
4. 결론
fastexcel이 Apache POI보다 코드를 작성하기 쉽고 보다 높은 사용성을 보이지만 전체적인 성능 측면에서는 Apache POI보다 열세를 보이는 것을 확인할 수 있었습니다.
특히 fastexcel이 작성하는 cell 개수가 늘어날수록 Apache POI보다 많은 메모리를 사용하기 때문에 별도 파일 인스턴스가 존재하는지 여부에 따라 라이브러리를 사용하는 것이 적합한지 판단할 수 있을 것 같습니다.
4.1 파일 인스턴스가 존재할 경우
- 파일 IO 관련된 처리만 하는 별도 인스턴스가 존재하므로 칼럼 개수와 데이터가 많더라도 특별한 제한 없이 fastexcel 적용 가능합니다.
- 물론, 별도 인스턴스가 있다고 해도 몇 천만 건에 대한 엑셀 다운로드는 지양해야 합니다.
- HTTP 요청에 대한 응답을 바로 내려주므로 L4 default gateway timeout을 건드리지 않아도 됩니다.
4.2 별도 파일 인스턴스가 존재하지 않을 경우
- 런타임 중 OOM이 발생할 경우 엄청난 장애이므로 fastexcel을 사용할 경우 범위 혹은 내려받을 수 있는 데이터 개수를 제한하는 방식으로 접근해야 합니다.
- OOM이 걱정되어 Apache POI를 사용할 경우 non-streaming 방식이므로 L4 default gateway timeout을 늘려줘야 합니다. 또한, 사용자에게 다운로드가 진행 중인 것을 알리기 위해 SSE를 적용하여 progress bar를 보여주는 것이 사용성에 좋을 것 같습니다.
- 하지만 gateway timeout을 무한정 늘릴 수 없기 때문에 Apache POI를 사용하더라도 범위 혹은 내려받을 수 있는 데이터 개수를 제한해야 할 것 같습니다.
- 위 방법들이 마음에 안 들 경우 csv를 response stream에 바로 작성하는 방식으로 접근해도 됩니다.
- 간단한 성능 테스트 결과 csv의 경우 row 개수 제한이 없고 sheet 단위로 나누지 않아도 되므로 소요시간은 Apache POI보다 우세하고 memory나 cpu 사용량은 Apache POI와 유사한 것을 확인할 수 있었습니다.
- 하지만 excel의 경우 한 sheet당 약 104만 칼럼만 작성할 수 있으므로 row 개수가 104만을 넘어갈 경우 다운로드한 csv를 notepad++ 혹은 gigasheet와 같은 툴을 통해 오픈해야 한다는 단점이 있습니다.
- 금융권과 같이 허가된 툴 사용만 가능할 경우 csv를 다운로드하더라도 excel을 통해 열 수 없는 단점이 존재하기 때문에 csv 다운로드 기능은 범용적으로 쓰기 어려울 것 같습니다.
개인적으로 결론을 내자면 저는 성능이 좀 떨어지더라도 사용성 측면에서 보다 뛰어난 fastexcel을 도입하는 것이 낫다고 생각합니다.
Naver D2 게시글을 보면 Naver 또한 Apache POI보다 퍼포먼스는 안 나오지만 보다 나은 사용성을 보이는 Excel.js를 사용하는 것을 확인할 수 있습니다.
Naver의 경우 Web Flux를 사용하여 Frontend node.js 서버에 DB 데이터를 스트리밍한 뒤 Excel.js 라이브러리를 통해 XLSX Streaming을 하는 것을 확인할 수 있습니다.

한 가지 차이점이라면 네이버의 경우 Flux를 사용하여 대용량 데이터라도 한번의 쿼리를 통해 데이터를 전부 가져오는 방식이지만 저 같은 경우 아직 Web Flux를 도입하지 못해 paging을 통해 여러 차례 쿼리를 호출해 데이터를 가져온다는 차이점이 있습니다.
Web Flux를 배워야하는 이유가 생긴 것 같습니다.
5. 참고
https://d2.naver.com/helloworld/9423440
https://github.com/dhatim/fastexcel
GitHub - dhatim/fastexcel: Generate and read big Excel files quickly
Generate and read big Excel files quickly. Contribute to dhatim/fastexcel development by creating an account on GitHub.
github.com
https://stackoverflow.com/questions/62201150/apache-poi-sxssf-streaming-output-response
Apache POI SXSSF streaming output response
I have a Java Jersey service with an endpoint that generates a CSV file on request, and streams it back as StreamingOutput. Something like this: return Response.ok((StreamingOutput) outputStream -...
stackoverflow.com
https://github.com/SuperSwanz/spring-boot-csv-download
GitHub - SuperSwanz/spring-boot-csv-download: Streaming large result set from MySQL using Java 8 and then download data as large
Streaming large result set from MySQL using Java 8 and then download data as large CSV file - GitHub - SuperSwanz/spring-boot-csv-download: Streaming large result set from MySQL using Java 8 and th...
github.com
https://stackoverflow.com/questions/23757991/maximum-number-of-rows-of-csv-data-in-excel-sheet
Maximum number of rows of CSV data in excel sheet
It is known that Excel sheets can display a maximum of 1 million rows. Is there any row limit for csv data, i.e. does Excel allow more than 1 million rows in csv format? One more question: About t...
stackoverflow.com
'리서치' 카테고리의 다른 글
| [Springboot] 멀티 데이터소스 (MyBatis, JPA) (11) | 2023.03.25 |
|---|---|
| [MSA] CQRS 패턴과 실제 적용 사례 (4) | 2022.10.31 |
| [MSA] 11번가 Spring Cloud 기반 MSA로의 전환 정리 (2) | 2022.10.29 |
| [MSA] 우아콘 2020 배달의민족 마이크로서비스 여행기 정리 (4) | 2022.10.27 |
| [tus protocol] 재개 가능한 파일 업로드를 위한 오픈 프로토콜 (8) | 2022.10.06 |