몽고DB 소개
- 몽고DB는 강력하고 유연하며 확장성 높은 범용 데이터베이스
- 보조 인덱스 (Secondary Index), 범위 쿼리 (Range Query), 정렬 (Sorting), 집계 (Aggregation), 공간 정보 인덱스 (Geospatial Index) 등을 확장 기능과 결합했음
- 몽고DB 프로젝트의 주 관심사는 확장성이 높으며 유연하고 빠른, 즉 완전한 기능을 갖춘 데이터 스토리지를 만드는 일
1. 손쉬운 사용
- 몽고DB는 도큐먼트 지향 데이터베이스 (Document-Oriented Database)
- 관계형 모델을 사용하지 않는 주된 이유는 분산 확장 (Scale-Out)을 쉽게 하기 위함이지만 다른 이점도 있음
- 도큐먼트 지향 데이터베이스에서는 행 개념을 사용하지 않고 보다 유연한 모델인 도큐먼트를 사용
- 내장 도큐먼트와 배열을 허용함으로써 도큐먼트 지향 모델은 복잡한 계층 관계를 하나의 레코드로 표현 가능하며 해당 방식은 최신 객체 지향 언어를 사용하는 개발자의 관점에 매우 적합함
- 몽고DB에서는 도큐먼트의 키와 값을 미리 정의하지 않기 때문에 RDBMS와 달리 고정된 스키마가 없음
- 따라서 필요할 때마다 쉽게 필드를 추가하거나 제거할 수 있으며 덕분에 개발 생산성을 향상함
2. 확장 가능한 설계
- 데이터베이스의 확장은 결국 더 큰 장비로 수직 확장 (Scale-Up)할지 혹은 여러 장비에 데이터를 나눠 분산 확장 (Scale-Out)하지 결정해야 하는 갈림길에 서게 함
- 일반적으로 Scale-Up이 더 편한 길이지만 대형 장비는 대체로 가격이 비싸고 결국에는 더는 확장할 수 없는 물리적 한계에 부딪힘
- 반면, 분산 확장은 저장 공간을 늘리거나 처리량을 높이고, 서버를 구매해서 클러스터에 추가하는 방법이기 때문에 경제적이고 확장이 용이하지만 수천 대의 장비를 운영해야 하기 때문에 하나의 장비만 관리할 때보다 관리가 더 어려움
- 몽고 DB는 분산 확장을 염두에 두고 설계됨
- 도큐먼트 지향 데이터 모델은 데이터를 여러 서버에 더 쉽게 분산하게 지원
- 도큐먼트를 자동으로 재분배하고 사용자 요청을 올바른 장비에 라우팅함으로써 클러스터 내 데이터 양과 부하를 조절할 수 있음
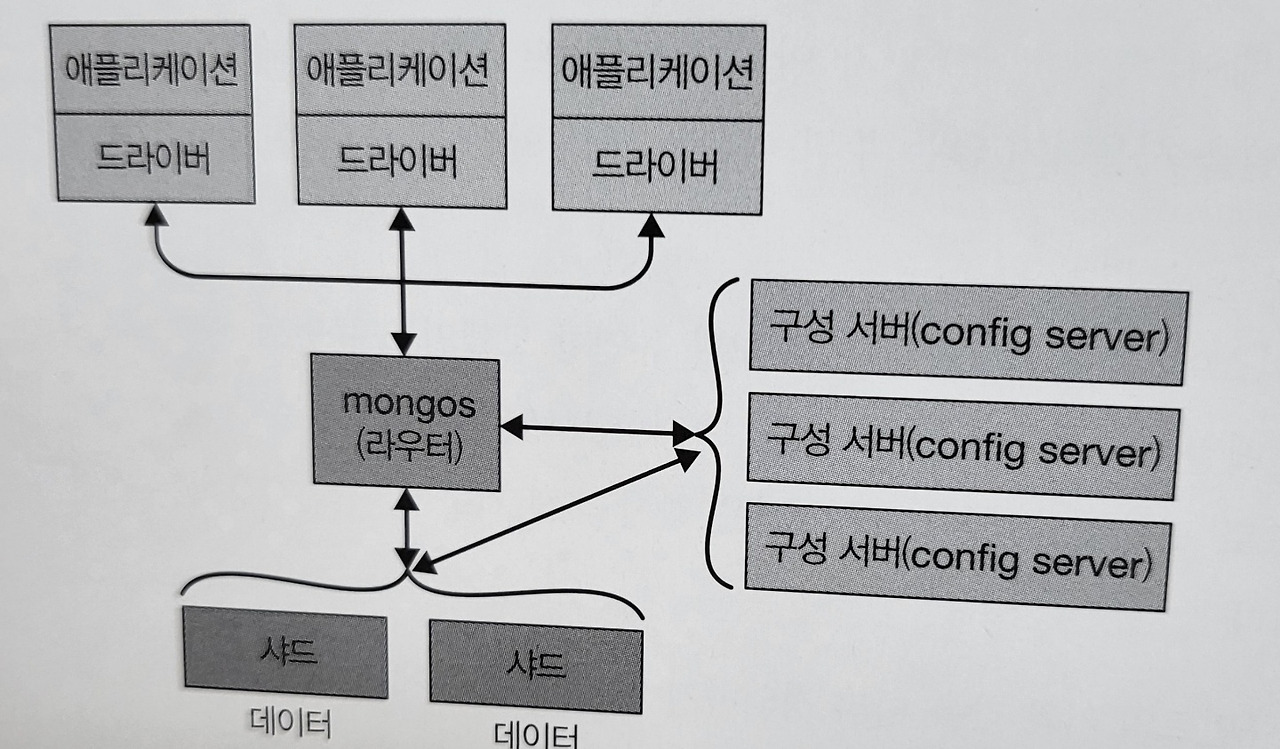
- 몽고DB 클러스터의 토폴로지나 데이터베이스 연결의 다른 쪽 끝에 단일 노드가 아닌 클러스터가 있는지는 애플리케이션에서 분명히 알 수 있기 때문에 개발자는 애플리케이션 확장이 아닌 개발에 집중할 수 있음
- 더 큰 부하를 지원하도록 기존에 배포된 애플리케이션의 토폴로지를 변경할 때도 마찬가지로 애플리케이션 로직은 그대로 유지 가능
3. 다양한 기능
- 몽고DB는 범용 데이터베이스로 만들어졌기 때문에 데이터의 생성, 읽기, 변경, 삭제 외에도 DBMS의 대부분의 기능과 더불어 다음과 같은 기능을 제공함
- 인덱싱: 몽고DB는 일반적인 보조 인덱스를 지원하며 unique, compound, 공간 정보, full-text 인덱싱 기능도 제공, nested document 및 배열과 같은 계층 구조의 보조 인덱스도 지원하며 개발자는 모델링 기능을 자신의 애플리케이션에 가장 적합한 방식으로 활용 가능
- 집계: 몽고DB는 데이터 처리 파이프라인 개념을 기반으로 한 집계 프레임워크를 제공, 집계 파이프라이니은 데이터베이스 최적화를 최대한 활용해 서버 측에서 비교적 간단한 일련의 단계로 데이터를 처리함으로써 복잡한 분석 엔진 구축 지원
- 특수한 컬렉션 유형: 몽고DB는 로그와 같은 최신 데이터를 유지하고자 세션이나 고정 크기 컬렉션과 같이 특정 시간에 만료해야 하는 데이터에 대해 TTL 컬렉션 지원, 또한 기준 필터와 일치하는 도큐먼트에 한정된 부분 인덱스를 지원함으로써 효율성을 높이고 필요한 저장 공간을 줄임
- 파일 스토리지: 몽고DB는 큰 파일과 파일 메타데이터를 편리하게 저장하는 프로토콜 지원
- 반면 RDBMS에 공통적으로 사용되는 일부 기능, 특히 복잡한 JOIN은 몽고DB에 존재하지 않음
- 몽고DB는 3.2에 도입된 $lookup 집계 연산자를 사용함으로써 매우 제한된 방식으로 JOIN 지원
- 3.6 버전에서는 관련 없는 서브 쿼리뿐만 아니라 여러 조인 조건으로 보다 복잡한 조인도 할 수 있음
- 두 가지 기능 모두 분산 시스템에서 효율적으로 제공하기 어렵기 때문에, 몽고DB의 JOIN은 더 큰 확장성을 허용하기 위한 아키텍처적인 결정
4. 고성능
- 몽고DB에서는 동시성과 처리량을 극대화하기 위해 WiredTiger 스토리지 엔진에 기회적 락 (Opportunistic Lock)을 사용
- 따라서 캐시처럼 제한된 용량의 램으로 쿼리에 알맞은 인덱스를 자동으로 선택할 수 있음
- 몽고DB는 모든 측면에서 고성능을 유지하기 위해 설계됨
- 몽고DB는 강력한 성능을 제공하면서도 관계형 시스템의 많은 기능을 포함
- 데이터베이스 서버의 일부 기능은 처리와 로직을 드라이버나 사용자의 애플리케이션 코드가 실행하는 클라이언트 측으로 위임
- 이러한 간소한 설계 덕분에 몽고DB는 뛰어난 성능을 발휘
참고
몽고DB 완벽 가이드 3판 - 한빛미디어
반응형
'DB > 몽고DB 완벽 가이드 3판' 카테고리의 다른 글
| [6장] 특수 인덱스와 컬렉션 유형 (0) | 2025.04.10 |
|---|---|
| [5장] 인덱싱 (0) | 2025.04.04 |
| [4장] 쿼리 (0) | 2025.03.29 |
| [3장] 도큐먼트 생성, 갱신, 삭제 (0) | 2025.03.28 |
| [2장] 몽고DB 기본 (0) | 2025.03.27 |