1. 도큐먼트 삽입
- 삽입은 몽고DB에 데이터를 추가하는 기본 방법이며 도큐먼트를 삽입하기 위해 컬렉션의 insertOne 메서드를 사용
- 그러면 도큐먼트에 "_id" 키가 추가되고 도큐먼트가 몽고DB에 저장됨
1.1 insertMany
- 여러 도큐먼트를 컬렉션에 삽입하려면 insertMany로 도큐먼트 배열을 데이터베이스에 전달해야 함
- 코드가 삽입된 각 도큐먼트에 대해 데이터베이스로 왕복하지 않고
- 도큐먼트를 bulk insert 하므로 훨씬 더 효율적

- insertMany는 여러 도큐먼트를 단일 컬렉션에 삽입할 때 유용함
- 데이터를 몽고DB에 저장하기 전에 날짜를 날짜형으로 바꾸거나 별도로 생성한 "_id"를 추가하는 식으로 가공해 두면 편리하게 insertMany 사용 가능
- 몽고DB의 4.2.X 버전은 48MB보다 큰 메시지를 허용하지 않으므로 한 번에 일괄 삽입 할 수 있는 데이터의 크기에 제한이 있음
- 48MB보다 큰 삽입을 시도하면 많은 드라이버는 삽입된 데이터를 48MB 크기의 bulk insert 여러 개로 분할시킴
- insertMany를 사용해 bulk insert할 때 배열 중간에 있는 도큐먼트에서 특정 유형의 오류가 발생하는 경우, 정렬 연산을 선택했는지 혹은 비정렬 연산을 선택했는지에 따라 발생하는 상황이 달라짐
- insertMany의 두 번째 매개변수로 옵션 도큐먼트를 지정할 수 있으며 true일 경우 도큐먼트가 제공된 순서대로 삽입이 되고 false일 경우 몽고DB가 자체적으로 성능 개선을 위해 도큐먼트들을 재배열시켜 저장함
- 정렬된 삽입 (두 번째 매개변수 true)의 경우 오류가 발생한 도큐먼트 직전까지만 저장됨
- 정렬되지 않은 삽입 (두 번째 매개변수 false)의 경우 몽고DB는 우선 모든 도큐먼트 삽입을 시도하며 이중 오류가 발생하는 도큐먼트만 저장 안됨

부연 설명
- 두 번째 매개변수는 true가 디폴트 값이므로 도큐먼트가 제공된 순서대로 삽입됨
- _id가 unique여야 하는데 세 번째 도큐먼트가 이를 위반하므로 세 번째 도큐먼트부터 삽입이 안됨

부연 설명
- 두 번째 매개변수가 false이므로 몽고DB가 자체적으로 성능 개선을 위해 도큐먼트들을 재배열 시킴
- 앞선 예제와 달리 제공된 순서가 오류가 발생하는 도큐먼트 뒤에 위치한 도큐먼트도 삽입된 것을 확인 가능
1.2 삽입 유효성 검사
- 몽고DB는 삽입된 데이터에 최소한의 검사를 수행함
- 도큐먼트의 기본 구조를 검사해 "_id" 필드가 존재하지 않으면 새로 추가하고
- 모든 도큐먼트는 16MB보다 작아야 하므로 크기 검사를 시행 (4.2.X 버전 기준)
- doc라는 도큐먼트의 Binary JSON (BSON) 크기를 보려면 셸에서 object.bsonsize(doc)를 실행
- 최소한의 검사를 하는 이유는 유효하지 않은 데이터가 입력되기 쉽기 때문
- 따라서 애플리케이션 서버와 같은 신뢰성 있는 소스만 데이터베이스에 연결해야 함
- 모든 주요 언어용 드라이버와 대부분의 비주류 언어용 드라이버는 데이터를 데이터베이스에 보내기 전에 다양한 유효성 검증을 진행
- ex) 도큐먼트가 너무 크지 않은지, UTF-8이 아닌 문자열을 쓰는지, 인식할 수 없는 데이터형을 포함하는지 등을 확인
1.3 삽입
- 몽고DB 3.0 이전 버전에서는 도큐먼트를 몽고DB에 삽입하는 주된 방법이 insert
- 현재는 insertOne과 insertMany 사용하는 것을 권장
2. 도큐먼트 삭제
- CURD API는 deleteOne과 deleteMany를 제공
- 두 메서드 모두 필터 도큐먼트를 첫 번째 매개변수로 사용
- 필터는 도큐먼트를 제거할 때 비교할 일련의 기준을 지정

- 위 예제에서는 "_id"와 같이 컬렉션에서 고유하기 때문에 여기서는 하나의 도큐먼트만 일치시킬 수 있는 필터를 사용
- 컬렉션 내 여러 도큐먼트와 일치하는 필터도 지정 가능
- 이때 deleteOne은 필터와 일치하는 첫 번째 도큐먼트를 삭제
- 어떤 도큐먼트가 먼저 발견되는지는 도큐먼트가 삽입된 순서, 도큐먼트에 어떤 갱신이 이뤄졌는지, 그리고 어떤 인덱스를 지정하는지 등 몇 가지 요인에 따라 달라짐
- 필터와 일치하는 모든 도큐먼트를 삭제하기 위해서는 deleteMany를 사용
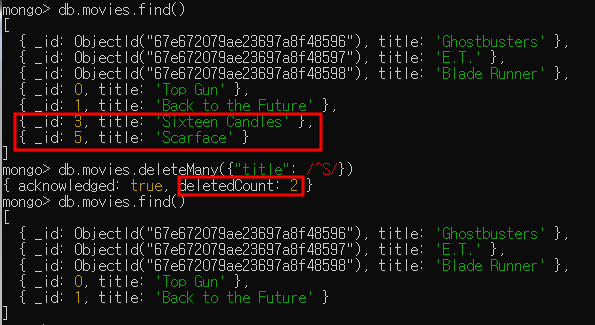
부연 설명
- title이 S로 시작하는 도큐먼트 삭제하도록 필터링 설정
2.1 drop
- deleteMany를 사용해 컬렉션의 모든 도큐먼트를 제거 가능
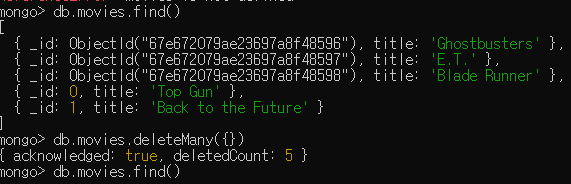
- 일반적으로 도큐먼트를 제거하는 작업은 꽤 빠르지만 전체 컬렉션을 삭제하려면 다음과 같이 drop을 사용하는 편이 더 빠름
- drop을 사용한 뒤 빈 컬렉션에 인덱스를 재생성함
db.movies.drop()
- 데이터는 한 번 제거하면 영원히 사라짐
- 이전에 백업된 데이터를 복원하는 방법 외에 delete 또는 drop 작업을 취소하거나 삭제된 도큐먼트를 복구하는 방법은 없음
3. 도큐먼트 갱신
- 도큐먼트를 데이터베이스에 저장한 후에는 updateOne, updateMany, replaceOne과 같은 갱신 메서드를 사용해 변경 가능
- updateOne과 updateMany는 필터 도큐먼트를 첫 번째 매개변수로, 변경 사항을 설명하는 수정자 도큐먼트를 두 번째 매개변수로 사용
- replaceOne도 첫 번째 매개변수로 필터를 사용하지만 두 번째 매개변수는 필터와 일치하는 도큐먼트를 교체할 도큐먼트
- 갱신은 원자적으로 이루어짐
- 갱신 요청 두 개가 동시에 발생하면 서버에 먼저 도착한 요청이 적용된 후 다음 요청이 적용됨
- 따라서 여러 개의 갱신 요청이 빠르게 발생하더라도 결국 마지막 요청이 최종적으로 적용되므로 도큐먼트는 변질 없이 안전하게 처리됨
- 기본 동작을 원치 않을 ㄱ여우 도큐먼트 버저닝 패턴 (The Document Versioning Pattern)을 고려해야 함
3.1 도큐먼트 치환
- replaceOne은 도큐먼트를 새로운 것으로 완전히 치환시키며 이는 대대적인 스키마 마이그레이션에 유용함
- i.g. 사용자 도큐먼트 내 "friends"와 "enemies" 필드를 "relationships"라는 서브 도큐먼트로 옮긴다고 가정
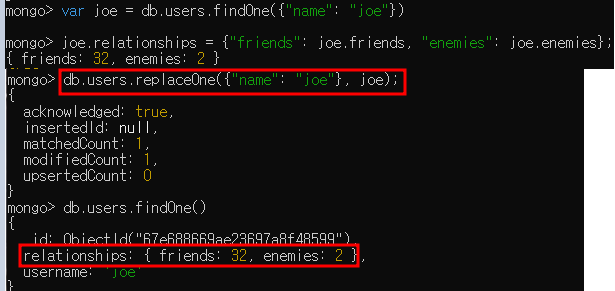
- 흔히 하는 실수로, 조건절로 두 개 이상의 도큐먼트가 일치되게 한 후 두 번째 매개변수로 중복된 "_id" 값을 갖는 도큐먼트를 생성하는 경우가 있는데 이때 데이터베이스는 오류를 반환하고 아무것도 변경하지 않음
- `E1101 dupicate key on update` 예외 발생
- 이런 상황을 피하기 위해서는 "_id" 키로 일치하는 고유한 도큐먼트를 조회한 뒤 해당 도큐먼트를 갱신 대상으로 지정하는 것을 권장 ("_id"는 고유한 값)
- "_id" 값이 컬렉션 기본 인덱스의 기초를 형성하므로 필터에 "_id"를 사용하는 것이 효율적이며 권장하는 방법
db.people.replaceOne({"_id": ObjectId("4b2b9f67a1f631733d917a7c")}, joe)3.2 갱신 연산자
- 일반적으로 도큐먼트의 특정 부분만 갱신하는 경우가 많으며 부분 갱신에는 원자적 갱신 연산자를 사용
- 갱신 연산자는 키를 변경, 추가, 제거하고, 심지어 배열과 내장 도큐먼트를 조작하는 복잡한 갱신 연산을 지정하는 데 사용하는 특수 키
- 연산자를 사용할 때 "_id" 값은 변경할 수 없음
- 그 외 다른 키 값은 모두 변경 가능
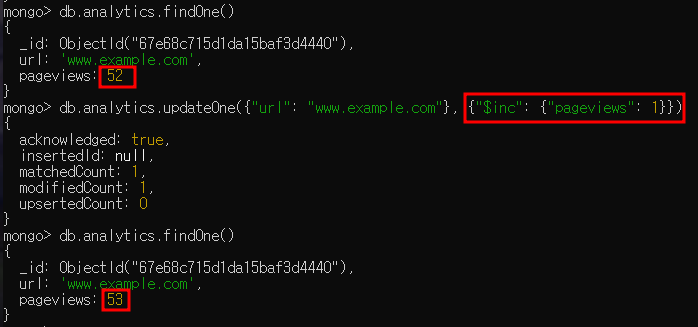
다음은 컬렉션에 웹사이트 분석 데이터를 저장한 뒤 유저가 페이지를 방문할 때마다 카운터를 증가시키는 예제입니다.
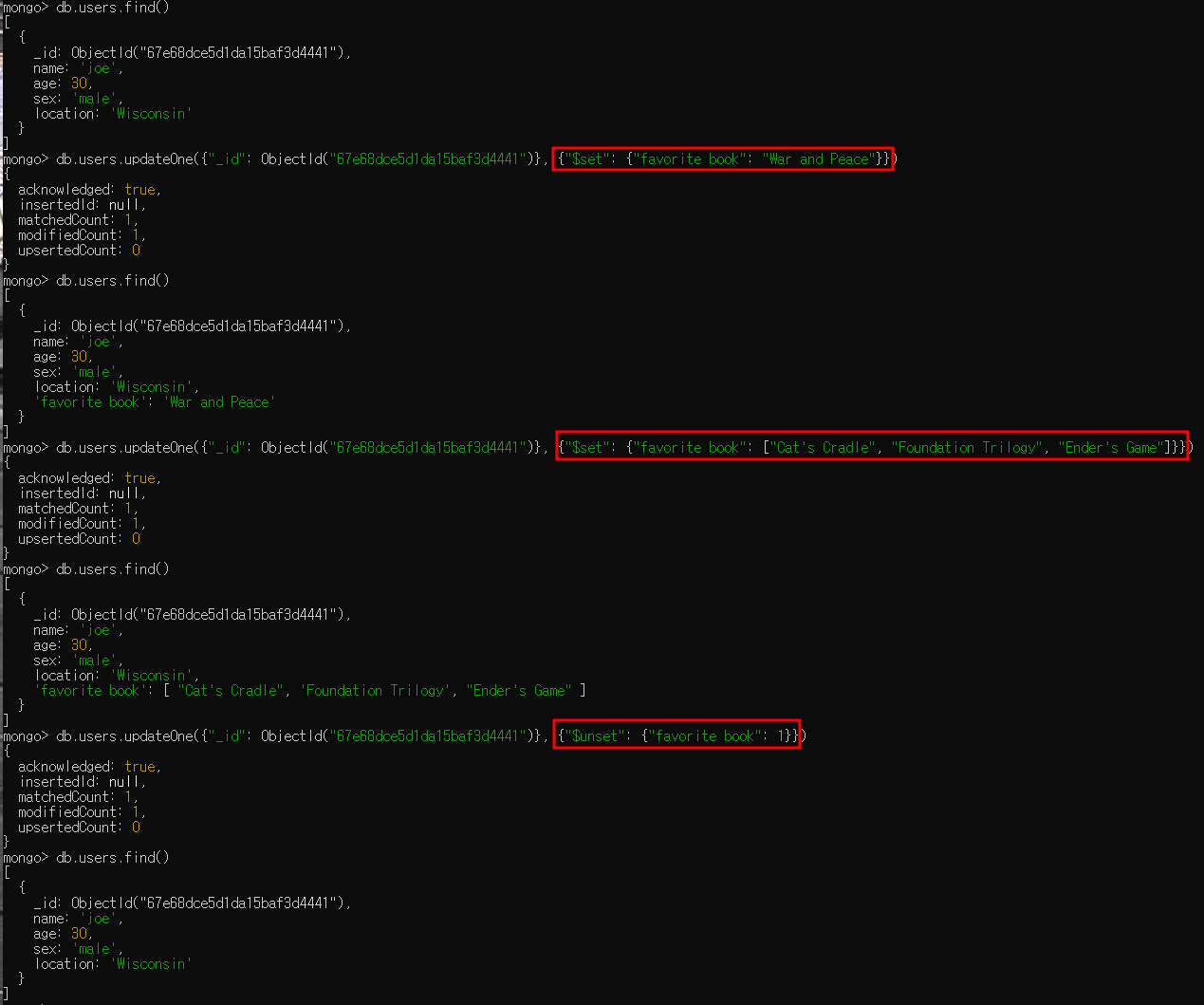
가. "$set" 제한자 사용하기
- "$set"은 필드 값을 설정하며 필드가 존재하지 않을 경우 새 필드가 생성됨
- 해당 기능은 스키마를 갱신하거나 사용자 정의 키를 추가할 때 편리함
- 키를 추가, 변경, 삭제할 때는 항상 $ 제한자를 사용해야 함
다음은 $set 제한자를 통해 사용자가 `제일 좋아하는 책`을 추가한 뒤 "$unset" 키를 통해 추가한 `제일 좋아하는 책`을 제거하는 예제입니다.
나. 증가와 감소
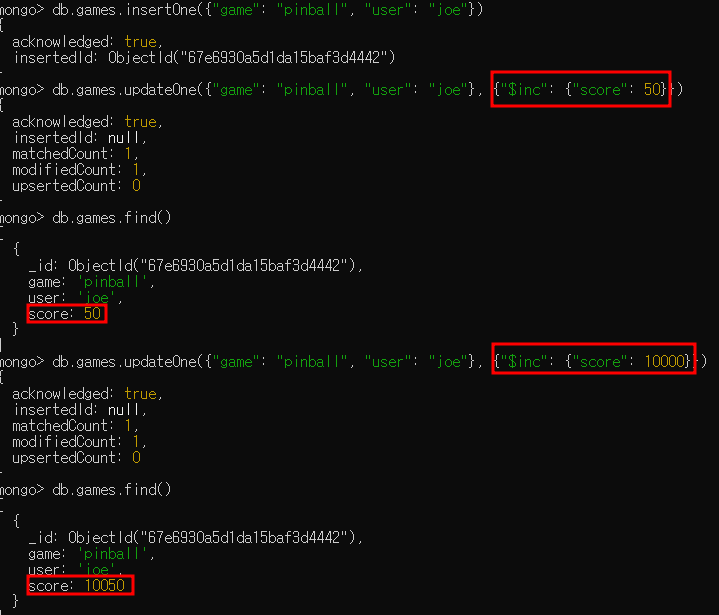
- "$inc" 연산자는 이미 존재하는 키의 값을 변경하거나 새 키를 생성하는 데 사용하며 분석, 분위기, 투표 등과 같이 자주 변하는 수치 값을 갱신하는 데 매우 유용함
- "$inc"는 "$set"과 비슷하지만 숫자를 증감하기 위해 설계됨
- "$inc"는 int, long, double, decimal 타입 값에만 사용 가능
- 문자, 배열 등 숫자가 아닌 값은 증감할 수 없기 때문에 "$inc"의 키 값은 반드시 숫자여야 함
- null, 불리언, 문자열로 나타낸 숫자와 값이 여러 언어에서 숫자로 자동 변환되는 데이터형의 값에는 사용 불가
- 숫자가 아닌 값으로 증감을 시도하면 `Modifier "$inc" allowed for number only`라는 오류 메시지가 뜸
- 다른 데이터형을 반환하려면 "$set"이나 배열 연산자를 사용
다음은 플레이어의 게임 점수를 증가시키는 예제입니다.
다. 배열 연산자
- 배열을 다루는 데 갱신 연산자를 사용할 수 있음
- 배열은 일반적이고 강력한 데이터 구조
- 연산자는 리스트에 대한 인덱스를 지정할 수 있을 뿐 아니라 set처럼 이중으로 사용 가능
요소 추가하기
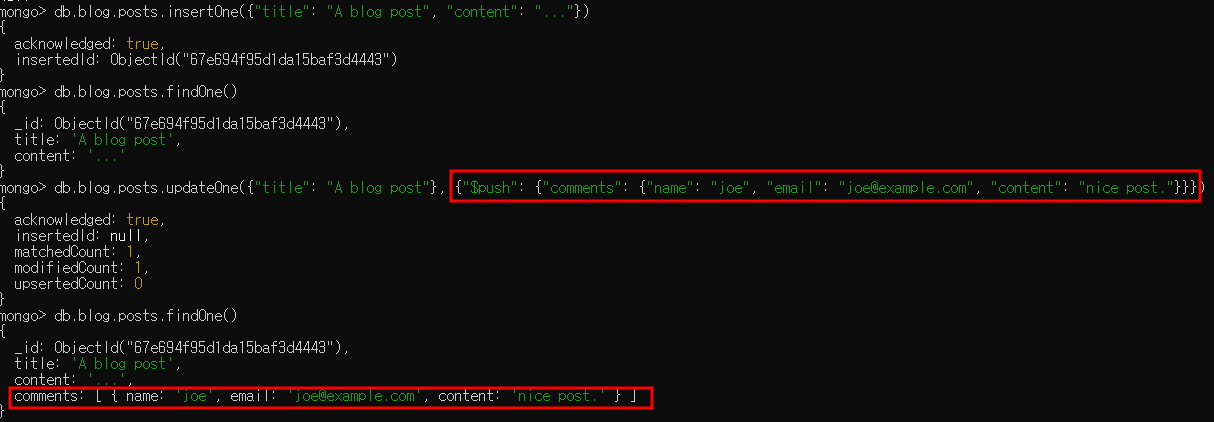
- "$push"는 배열이 이미 존재하면 배열 끝에 요소를 추가하고, 존재하지 않으면 새로운 배열을 생성
- i.g. 블로그 게시물에 배열 형태의 "comments" 키를 삽입한다고 가정했을 때 존재하지 않던 "comments" 배열이 생성되고 댓글이 추가됨
- 댓글을 더 추가하려면 "$push"를 다시 사용하면 됨
- 몽고DB 쿼리 언어는 "$push"를 포함해 일부 연산자에 제한자를 제공
- "$push"에 "$each" 제한자를 사용하면 작업 한 번으로 값을 여러 개 추가할 수 있음

- 배열을 특정 길이로 늘이려면 "$slice"를 "$push"와 결합해 사용
- 배열이 특정 크기 이상으로 늘어나지 않게 하고 효과적으로 'top N' 목록을 만들 수 있음
- i.g. 배열에 추가할 수 있는 요소의 개수를 10개로 제한
- 추가 후에 배열 요소의 개수가 10보다 작으면 모든 요소가 유지
- 10보다 크면 마지막 10개 요소만 유지
- 따라서 "$"slice"는 도큐먼트 내 큐를 생성하는 데 사용 가능
- 마지막으로 트리밍 하기 전에 "$sort" 제한자를 "$push" 작업에 적용 가능
- i.g. "rating" 필드로 배열의 모든 요소를 정렬한 뒤 처음 10개 요소를 유지, "$slice"나 "$sort"를 배열상에서 "$push"와 함께 사용하려면 반드시 "$each"도 사용해야 함
배열을 집합으로 사용하기
- 특정 값이 배열에 존재하지 않을 때 해당 값을 추가하면서, 배열을 집합처럼 처리하기 위해 쿼리 도큐먼트에 "$ne"를 사용
- i.g. 인용 목록에 저자가 존재하지 않을 때만 해당 저자를 추가
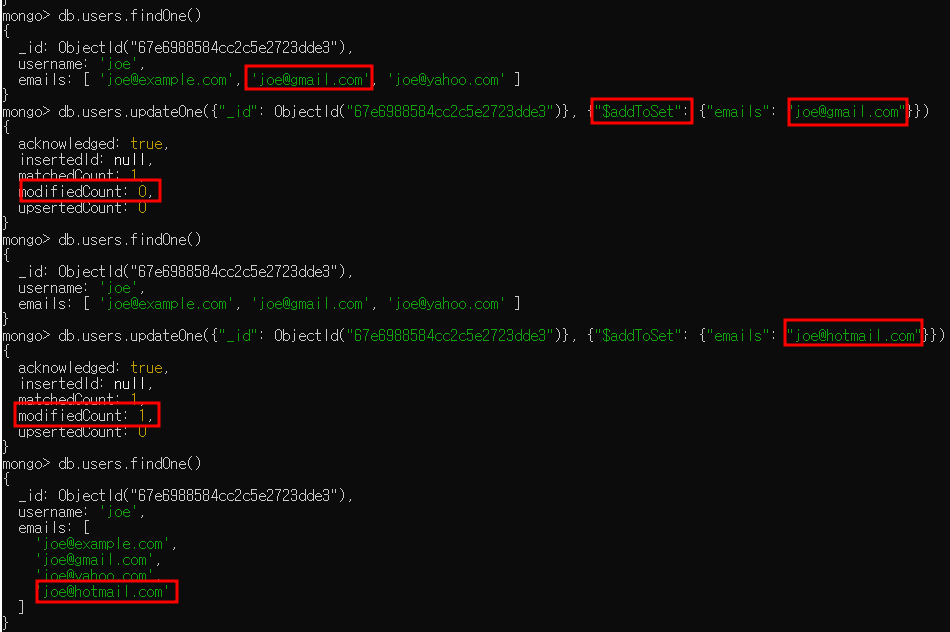
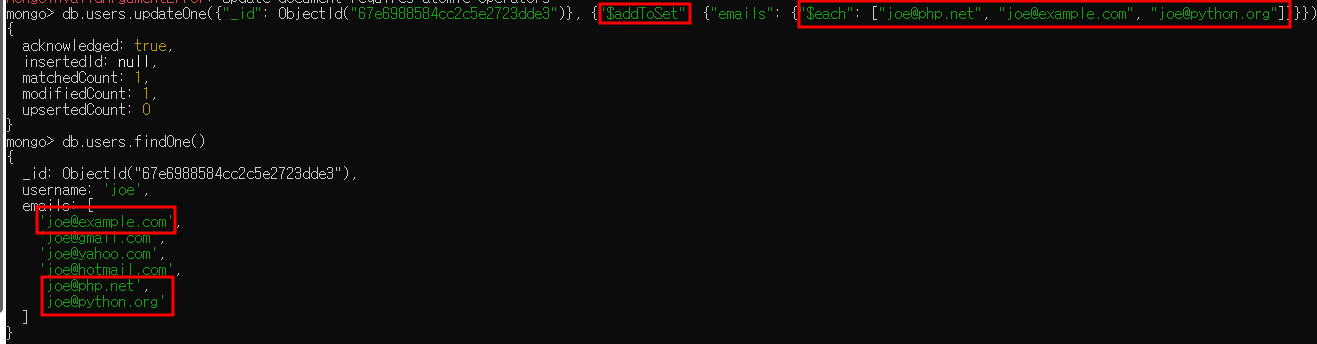
- "$addToSet"을 사용할 수도 있음
- "$addToSet"은 "$ne"가 작동하지 않을 때나 "$addToSet"을 사용하면 무슨 일이 일어났는지 더 잘 알 수 있을 때 유용
- i.g. 사용자 정보 도큐먼트가 있고 도큐먼트 내 사용자가 입력한 이메일 주소 셋이 있을 때 "$addToSet"을 통해 중복된 주소를 추가하는 것을 피할 수 있음
- "$addToSet"과 "$each"를 결합해 사용하면 unique 한 값을 여러 개 추가 가능
- 이는 "$ne"와 "$push" 조합으로는 할 수 없는 작업
- i.g. 이메일 주소를 두 개 이상 추가하려면 다음과 같이 연산자를 사용
요소 제거하기
- 배열에서 요소를 제거하는 방법에는 몇 가지 있음
- 배열을 큐나 스택처럼 사용하려면 배열의 양쪽 끝에서 요소를 제거하는 "$pop"을 사용 i.g. {"$pop": {"key": 1}}은 배열의 마지막부터 요소를 제거하고, {"$pop": {"key": -1}}은 배열의 처음부터 요소를 제거
- "$pull"은 주어진 조건에 맞는 배열 요소를 제거하는 데 사용
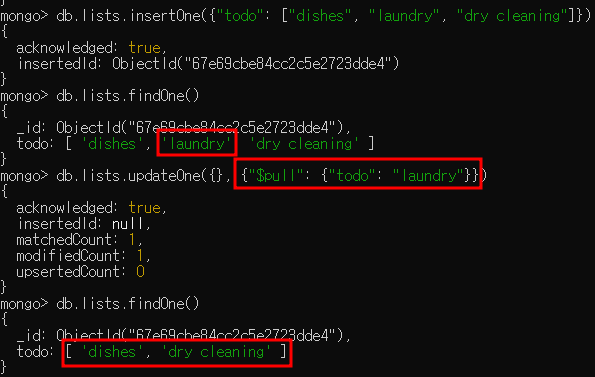
- "$pull"은 도큐먼트에서 조건과 일치하는 요소를 모두 제거함
- i.g. [1, 1, 2, 1]과 같은 배열에서 1을 뽑아내면 배열에는 [2] 하남나 남음
- 배열 연산자는 배열을 값으로 갖는 키에만 사용
- 따라서 정수형에 데이터를 넣거나 문자열형에서 데이터를 빼내는 작업은 할 수 없음
- 스칼라값을 변경하려면 "$set"이나 "$inc"를 사용
배열의 위치 기반 변경
- 배열 내 여러 값을 다루는 방법은 두 가지가 있음
- 위치를 이용하거나
- 위치 연산자 ("$" 문자)를 사용
- 배열 인덱스 기준은 0이며, 배열 요소는 인덱스를 도큐먼트의 키처럼 사용
- 보통 도큐먼트를 쿼리 해서 검사해보지 않고는 배열의 몇 번째 요소를 변경할지 알 수 없음
- 해당 문제를 해결하기 위해 몽고DB에서는 쿼리 도큐먼트와 일치하는 배열 요소 및 요소의 위치를 알아낸서 갱신하는 위치 연산자 "$"를 제공
- i.g. John이라는 사용자가 이름을 Jim으로 갱신하려고 할 때, 위치 연산자를 사용해서 댓글 내 해당 항목 ("author")를 갱신
db.blog.updateOne({"comments.author": "John"}, {"$set": {"comments.$.author": "Jim"}})
부연 설명
- 위치 연산자는 첫 번째로 일치하는 요소만 갱신
- 따라서 John이 댓글을 두 개 이상 남겼다고 가정할 경우 처음 남긴 댓글의 작성자명만 변경됨
배열 필터를 이용한 갱신
- 몽고DB 3.6에서는 개별 배열 요소를 갱신하는 배열 필터인 arrayFilters를 도입해 특정 조건에 맞는 배열 요소를 갱신 가능
- i.g. 반대표가 5표 이상인 댓글을 숨기는 예제
부연 설명
- "comments" 배열의 각 일치 요소에 대한 식별자로 elem을 정의
- elem이 식별한 댓글의 투표값이 -5 이하면 "comments" 도큐먼트에 "hidden" 필드를 추가하고 값을 true로 설정
3.3 갱신 입력
- 갱신 입력은 특수한 형태를 갖는 갱신
- 갱신 조건에 맞는 도큐먼트가 존재하지 않을 때는 쿼리 도큐먼트와 갱신 도큐먼트를 합쳐서 새로운 도큐먼트를 생성
- 조건에 맞는 도큐먼트가 발견되면 일반적인 갱신을 수행
- 컬렉션 내 시드 도큐먼트가 필요 없어 매우 편리하며, 같은 코드로 도큐먼트를 생성하고 갱신할 수도 있음
앞서 3.2 절에서 다룬 "웹사이트 분석 데이터를 저장한 뒤 유저가 페이지를 방문할 때마다 카운터를 증가시키는 예제"를 자바스크립트 코드로 작성하면 다음과 같습니다.
- 해당 코드를 여러 프로세스에서 실행할 경우 주어진 URL에 두 개 이상의 도큐먼트가 동시에 삽입되는 race condition이 발생할 수 있음
갱신 입력을 사용하면 코드를 줄이고 경쟁 상태를 피할 수 있습니다.
- updateOne과 updateMany의 세 번째 매개변수는 옵션 도큐먼트로, 갱신 입력을 지정
- 단 한 줄로 이전 코드 블록과 동일한 동작을 처리하며, 심지어 더 빠르고 원자적
- 새로운 도큐먼트는 조건 도큐먼트에 도큐먼트 제한자를 적용해 생성됨
db.analytics.updateOne({"url": "/blog"}, {"$inc": {"pageviews": 1}}, {"upsert": true})
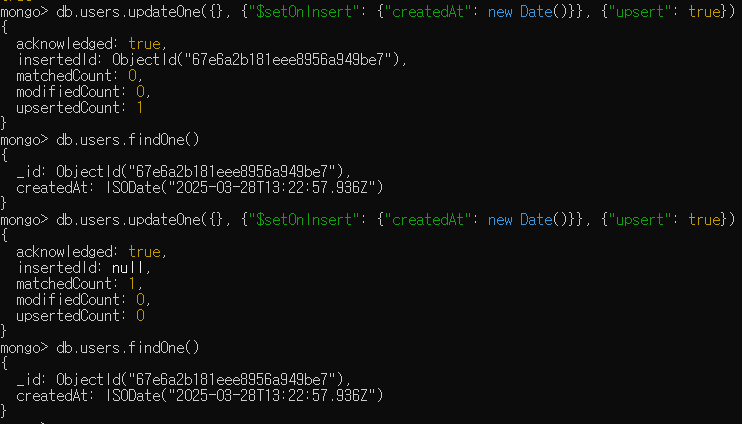
- 도큐먼트가 생성될 때 필드가 설정돼야 할 때가 종종 있는데, 이후 갱신에서는 변경되지 않아야 함
- 이때 "$setOnInsert"를 사용
- "$setOnInsert"는 도큐먼트가 삽입될 때 필드값을 설정하는 데만 사용하는 연산자
부연 설명
- "$setOnInsert"를 사용했으므로 다시 갱신할 경우 기존 도큐먼트를 조회하고, 아무것도 입력되지 않으며, "createdAt" 필드는 변경되지 않음
- "$setOnInsert"는 패딩을 생성하고 카운터를 초기화하는데 쓰이며, ObjectId를 사용하지 않는 컬렉션에 유용함
저장 셸 보조자
- save는 도큐먼트가 존재하지 않으면 도큐먼트를 삽입하고, 존재하면 도큐먼트를 갱신하게 하는 셸 함수
- 셸 함수는 매개변수가 하나이며 도큐먼트를 넘겨받음
- 도큐먼트가 "_id" 키를 포함하면 save는 갱신 입력을 실행하고, 포함하지 않으면 삽입을 실행
- save는 개발자가 셸에서 도큐먼트를 빠르게 수정하게 해주는 편리한 함수
3.4 다중 도큐먼트 갱신
- updateOne은 필터 조건에 맞는 첫 번째 도큐먼트만 갱신하고 조건에 맞는 도큐먼트가 더 있더라도 변경되지 않고 그대로 유지됨
- 조건에 맞는 도큐먼트를 모두 수정하려면 updateMany를 사용해야 함
- updateMany는 updateOne과 같은 의미론을 따르며 동일한 매개변수를 취하지만 변경할 수 있는 도큐먼트 개수가 다르다는 중용한 차이점이 있음
- updateMany는 스키마를 변경하거나 특정 사용자에 새로운 정보를 추가할 때 사용하기 좋음
- i.g. 특정 날짜에 생일을 맞이하는 모든 사용자에게 선물을 준다고 가정했을 때 updateMany를 사용해 계정에 "gift"를 추가
3.5 갱신한 도큐먼트 반환
- 몽고DB 3.2에서는 findOneAndDelete, findOneAndReplace, 그리고 findOneAndUpdate를 셸에 도입함
- updateOne과 같은 메서드와의 주요 차이점은 사용자가 수정된 도큐먼트의 값을 원자적으로 얻을 수 있다는 점
- 몽고DB 4.2는 갱신을 위한 집계 파이프라인을 수용하도록 findOneAndUpdate를 확장했으며 파이프라인은 $addFields (별칭 $set), $project (별칭 $unset), $replaceRoot (별칭 $replaceWith)로 구성될 수 있음
특정 순서대로 실행하는 프로세스 컬렉션이 있다고 가정하고 각각은 아래와 같은 형식의 도큐먼트로 표현한다고 가정하겠습니다.
- "status"는 문자열이며 "READY", "RUNNING", 또는 "DONE"이 될 수 있음
다음 요구사항이 들어왔을 때 findOneAndUpdate가 적합합니다.
- 상태가 "READY"인 프로세스를 찾아 우선순위가 가장 높은 프로세스의 상태를 "RUNNING"으로 갱신
부연 설명
- findOneAndUpdate 메서드는 기본적으로 도큐먼트의 상태를 수정하기 전에 반환하므로, 반환된 도큐먼트에서 상태가 여전히 "READY"
- 옵션 도큐먼트의 "returnNewDocument" 필드를 true로 설정하면 갱신된 도큐먼트를 반환
- 옵션 도큐먼트는 findOneAndUpdate의 세 번째 매개변수로 전달됨
- 이외에도 두 가지 메서드를 알아두면 유용함
- findOneAndReplace는 동일한 매개변수를 사용하며, returnNewDocument의 값에 따라 교체 전이나 후에 필터와 일치하는 도큐먼트를 반환
- findOneAndDelete도 유사하지만 갱신 도큐먼트를 매개변수로 사용하지 않으며 다른 두 메서드의 옵션을 부분적으로 가짐
- findOneAndDelete는 삭제된 도큐먼트를 반환
참고
몽고DB 완벽 가이드 3판 - 한빛미디어
'DB > 몽고DB 완벽 가이드 3판' 카테고리의 다른 글
| [6장] 특수 인덱스와 컬렉션 유형 (0) | 2025.04.10 |
|---|---|
| [5장] 인덱싱 (0) | 2025.04.04 |
| [4장] 쿼리 (0) | 2025.03.29 |
| [2장] 몽고DB 기본 (0) | 2025.03.27 |
| [1장] 몽고DB 소개 (0) | 2025.03.26 |