1. JOIN vs 서브 쿼리
- JOIN은 두 개 이상의 테이블을 논리적으로 연결해서, 관련된 데이터를 한 번에 조회할 수 있도록 해주는 SQL의 대표적인 기능
- i.g. 회원 테이블과 주문 테이블이 따로 있을 때, 회원의 이름과 해당 회원이 주문한 상품 목록을 함께 보고 싶다면 JOIN을 사용
- JOIN은 여러 테이블의 레코드를 조합하여 복합적인 데이터(복합 프로젝션)를 만드는 데 매우 효율적
- 여러 테이블의 데이터를 결합해야 할 때, 복합적인 결과 셋이 필요할 때, 그리고 결과에서 여러 테이블의 컬럼이 동시에 필요할 때 권장
- JOIN은 복합적인 데이터 결합에 효율적이지만, 불필요하게 사용할 경우 성능 저하나 복잡도 증가로 이어질 수 있음
- 서브 쿼리는 쿼리 안에 또 다른 쿼리가 들어 있는 구조
- 서브 쿼리는 주로 데이터의 일부를 조건으로 걸 때 사용
- i.g. 주문 테이블에서 특정 회원의 주문만 보고 싶을 때, 회원 테이블에서 ID를 먼저 찾고, 그 ID에 해당하는 주문만 조회
- 단순히 한 테이블에서 일부 데이터만 필터링하고 싶을 때, 복잡한 데이터 결합이 필요 없고 조건에 따라 데이터를 추출하고 싶을 때, 그리고 데이터의 존재 여부 또는 특정 조건에 대한 값이 필요할 때 권장
- 단순히 특정 조건에 맞는 데이터만 추출하려면, JOIN 대신 서브 쿼리를 사용하면 쿼리가 더 간단하고, 불필요한 결합 연산을 피할 수 있음
1.1 정리
- 여러 테이블의 데이터를 조합해서 결과를 만들어야 하는 복합 프로젝션이 필요하다면 JOIN을 사용
- 단순히 조건에 맞는 데이터만 추출하려면 JOIN 대신 서브 쿼리를 사용
2. JOIN 알고리즘
- 관계형 데이터베이스에서 여러 테이블을 조합할 때 사용하는 대표적인 조인 알고리즘은 다음과 같음
- Nested Join
- Hash Join
- Merge Join
2.1 Nested Join
- 가장 기본적인 조인 알고리즘
- 한 테이블의 각 행마다, 다른 테이블의 모든 행을 순차적으로 비교하여 조건에 맞는 행을 조합하며 마치 이중 for문처럼 동작
- 구현이 매우 단순하고 인덱스가 내부 테이블에 있을 경우 효율이 크게 향상될 수 있다는 장점이 있지만
- 최악의 경우 O(N * M)의 시간 복잡도를 가지므로 테이블의 크기가 커질수록 비효율적
작동 방식
- 외부 테이블(Outer Table)에서 한 행 조회
- 내부 테이블(Inner Table) 전체를 훑으면서, 조인 조건에 맞는 행 조회
- 조건에 부합하는 행이 있으면 결과로 반환
- 외부 테이블의 다음 행으로 이동해서 반복

2.2 Hash Join
- 조인 조건에 맞춰 한 테이블의 데이터를 해시 테이블로 만든 뒤, 다른 테이블의 각 행을 해시 테이블에서 빠르게 찾는 방식
- 시간복잡도가 O(N + M)이므로 주로 대용량 테이블 간 조인에 효율적
- 동등 조인(equi-join)에 매우 효율적
- 하지만 해시 테이블을 만들기 위해 메모리가 많이 필요할 수 있으며 범위 조인에는 사용할 수 없다는 단점 존재
작동 방식
- 작은 테이블(보통 인덱스가 없는 테이블)을 메모리에 올려서 해시 테이블 생성
- 해시 키는 조인 조건에 사용하는 컬럼
- 큰 테이블의 각 행을 하나씩 읽으면서, 해시 테이블에서 조인 조건에 맞는 값을 빠르게 조회
- 조건이 맞으면 결과로 반환

2.3 Merge Join
- 양쪽 테이블이 모두 조인 컬럼을 기준으로 정렬되어 있을 때 사용할 수 있는 조인 알고리즘
- 두 테이블을 나란히 비교하면서 병합하는 방식으로, 정렬된 데이터에 매우 효율적
- 정렬된 데이터(또는 인덱스 사용 시)에서 매우 빠르며 시간 복잡도가 O(nlog(n) + mlog(m))이므로 대용량 데이터를 효율적으로 처리 가능
- Hash Join과 달리 동등 조인뿐만 아니라 범위 조인도 가능
- 하지만 입력 데이터가 정렬되어 있지 않으면, 정렬 작업이 필요해 추가 비용 발생
작동 방식
- 양쪽 테이블(또는 인덱스)이 조인 컬럼을 기준으로 정렬되어 있어야 함
- 두 테이블의 포인터를 처음부터 시작해서, 조인 조건이 맞을 때까지 각각 이동
- 조건이 맞는 행을 만나면, 결과로 반환하고 다음 행으로 이동
- 포인터가 하나라도 끝에 도달하면 종료

3. 실제 예시
- 게시물 테이블(post)과 게시물에 대한 댓글 테이블(post_comment)이 있다고 가정할 때, 댓글이 가장 많은 상위 세 개의 게시물을 선별하는 상황
3.1 문제가 되는 쿼리
- 두 테이블을 JOIN한 뒤 GROUP BY를 진행하면 PostgreSQL의 경우 Hash Join 알고리즘을 적용하고 MySQL의 경우 Nested Join 알고리즘을 적용
- Nested Join 알고리즘의 경우 기본적인 시간 복잡도가 O(N * M)이므로 오래 걸리는 것이 자명
- Hash Join 알고리즘은 한 테이블(보통 더 작은 테이블)을 메모리에 해시 테이블로 만들고 다른 테이블과 비교하는 방식이지만, 데이터 양이 지나치게 많을 경우 해시 테이블 생성과 집계 처리에 시간이 오래 걸릴 수 있는 단점이 있음

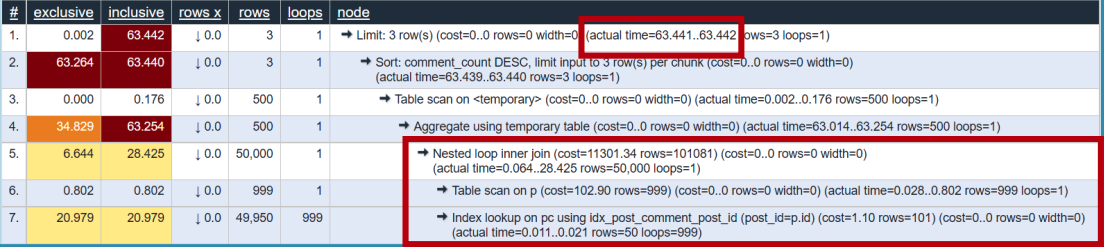
3.2 최적화
- JOIN을 수행하기 전에 GROUP BY 진행
- post_id를 사용할 수 있기 때문
- post_comment에 대해서만 GROUP BY를 진행하고 여기서 추출한 3개의 post_id에 대해서만 JOIN 진행


참고
인프런 - JPA (ORM) 개발자를 위한 고성능 SQL
반응형
'DB' 카테고리의 다른 글
| [RDBMS] 트랜잭션 (0) | 2025.05.14 |
|---|---|
| [RDBMS] 페이징 (Pagination) (0) | 2025.05.12 |
| [RDBMS] 파생 테이블과 공통 테이블 표현식 (0) | 2025.05.12 |
| LATERAL JOIN 개요 (0) | 2025.04.30 |