1. SQL Standard의 페이징
- SQL 2008 표준에서는 대용량 데이터의 일부만 선별적으로 조회할 수 있도록 페이징을 위한 구문을 도입
- FETCH FIRST N ROWS ONLY: 정렬된 결과 집합에서 상위 N개 행만 조회
- OFFSET M ROWS FETCH NEXT N ROWS ONLY: 결과 집합에서 M개 행을 건너뛴 뒤, 그다음 N개 행 조회
부연 설명
- 해당 쿼리는 post 테이블에서 created_on과 id를 내림차순으로 정렬한 뒤, 상위 5개의 title만 선택하여 조회
- 정렬 기준이 없다면, 반환되는 데이터의 순서는 DB 내부 처리 로직에 따라 비결정적이기 때문에, 정확한 페이징 결과를 얻을 수 없으므로 항상 원하는 순서대로 결과를 얻으려면 ORDER BY를 반드시 사용해야 함
부연 설명
- 6번째~10번째 결과를 조회
- OFFSET은 항상 정렬을 기반으로 동작해야 하며, 정렬 기준이 없으면 페이징은 의미가 없음
2. DBMS별 전통적 페이징 방식
2.1 Oracle
- 파생 테이블과 ROWNUM 활용
- 정렬 후 ROWNUM을 부여하고, 외부에서 원하는 구간을 WHERE로 필터링
2.2 SQL Server
- TOP N 또는 ROW_NUMBER() 윈도우 함수 활용
- ROW_NUMBER()로 각 행에 번호를 매기고, 원하는 범위의 번호만 선택
2.3 PostgreSQL/MySQL
- LIMIT과 OFFSET 문법 지원
- 가장 간결하고 직관적
3. 페이징의 성능 이슈: OFFSET 방식의 한계
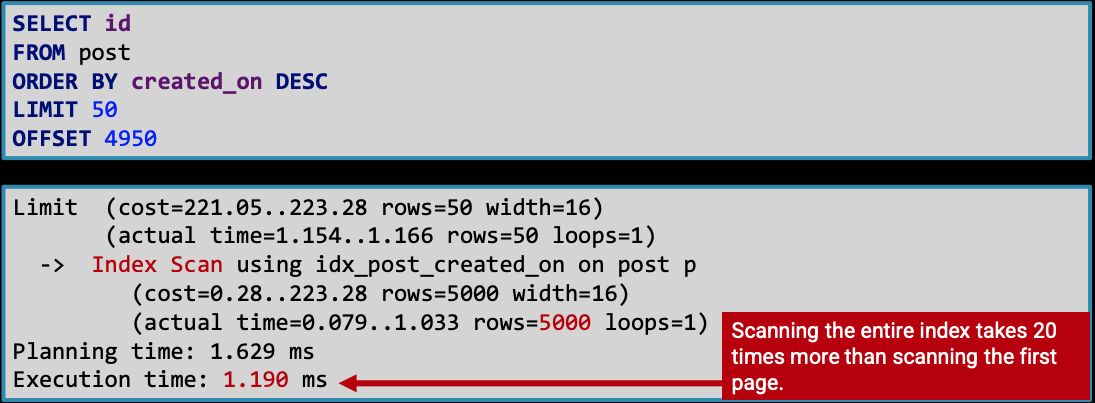
- OFFSET 방식은 결과 집합의 맨 앞부분을 건너뛰는 동안, 데이터베이스는 OFFSET 위치까지 인덱스 또는 테이블을 계속 스캔해야 함
- OFFSET이 커질수록, 즉 페이지가 뒤로 갈수록 성능 저하
- i.g. OFFSET이 4950일 때 50개를 가져오면, 인덱스를 5000개 행까지 읽고 마지막 50개만 반환

4. 인덱스 기반 고성능 페이징
- OFFSET 방식의 비효율을 극복하기 위해, Seek Pagination(키셋 페이징, 커서 페이징)을 활용
- 이전 페이지의 마지막 행의 정렬 기준을 기억해 두고, 이를 WHERE 조건에 활용해 바로 그 위치부터 데이터를 탐색
- 이런 방식은 인덱스만 활용하므로, 어떤 페이지이든 속도가 일정하게 빠름
부연 설명
- id와 created_on 컬럼에 인덱스 부여했다고 가정
- (a, b) < (c, d)는 PostgreSQL/MySQL에서 지원
- 마지막에 조회한 행의 created_on, id 값을 다음 쿼리의 기준으로 사용
- 앞서 언급했다시피 오라클은 파생 테이블과 ROWNUM 그리고 SQL Server는 ROW_NUMBER와 WHERE 절로 구현 가능
5. 실무 Best Practice
가. 정렬 기준에 항상 인덱스 적용
- 페이징 쿼리는 일반적으로 ORDER BY 절을 사용해 결과의 순서를 보장하며 이때 정렬 기준이 되는 컬럼 (i.g. created_on, id 등)에 인덱스를 반드시 생성해야 함
- 인덱스가 있으면 데이터베이스는 정렬할 때 전체 테이블을 읽지 않고, 인덱스를 따라 빠르게 필요한 행을 찾고 정렬할 수 있음
- 인덱스가 없는 컬럼으로 정렬하면, DB는 모든 데이터를 불러와 정렬 (Full Table Scan + Sort) 해야 하므로, 데이터 양이 많을수록 속도가 매우 느려짐
- 복합 정렬 (i.g. ORDER BY created_on DESC, id DESC)에는 복합 인덱스가 효과적
나. OFFSET 방식은 첫 페이지에만 사용
- OFFSET은 데이터를 건너뛰는 방식으로, OFFSET 값이 커질수록 DB는 인덱스나 테이블을 그만큼 더 많이 읽어야 하므로 속도가 급격히 느려짐
- OFFSET 0은 즉시 시작할 수 있으나, OFFSET 10000이면 앞서 10000개 행을 모두 읽고 건너뛴 후 결과를 반환해야 함
- 실시간 반응성이 중요한 경우에는 OFFSET 방식은 첫 페이지 또는 소규모 범위에서만 사용하는 것이 좋고, 이후 페이지는 다른 방식 고려 필요
다. Seek Pagination 방식 권장
- Seek Pagination (커서 방식, Keyset Pagination)은 `어디서부터 다시 시작할지`를 명확하게 지정하는 방식
- 페이지 번호가 아니라, 이전 페이지의 마지막 행의 정렬 기준 값을 기억해두었다가 해당 값보다 작은 또는 큰 데이터를 바로 조회
- i.g. PostgreSQL과 MySQL에서는 WHERE (created_on, id) < (?, ?) 와 같이 사용
- 해당 방식은 항상 인덱스를 타고 들어가므로, 첫 페이지든 마지막 페이지든 동일하게 빠른 성능 보장
- 커서 방식은 대량 데이터 처리, 무한 스크롤, 실시간 서비스 등에 특히 적합함
라. 적절한 Fetch Size, Streaming 활용
- 데이터를 한 번에 모두 메모리로 가져오는 것이 아니라, 서버와 클라이언트 사이에서 데이터를 스트리밍 전송하면 메모리 사용량과 응답 지연을 줄일 수 있음
- JDBC 기반의 Java 애플리케이션에서는 fetchSize 옵션을 조절해 한 번에 가져올 레코드 수를 지정할 수 있음
- i.g. fetchSize를 50으로 두면, 매번 50개씩 읽어온 후 다음 50개를 가져옴
- PostgreSQL, MySQL 등에서도 스트리밍/커서 기반 쿼리를 지원하며 대용량 데이터를 처리할 때 네트워크와 메모리 효율을 높여줌
마. 파생 테이블 활용
- 복잡한 페이징이나 조건부 집계, 다중 정렬이 필요할 때, 서브쿼리 또는 파생 테이블을 적극 활용하면 쿼리의 가독성과 성능을 모두 높일 수 있음
- i.g. ROW_NUMBER() 결과를 파생 테이블로 감싸고, 그 결과에서 원하는 범위만 WHERE로 추출하면 깔끔하게 페이징 처리 가능
- 파생 테이블을 통해 데이터 가공을 단계별로 나누면 유지보수도 쉬워짐
바. 실행 계획 분석
- SQL 쿼리를 작성한 뒤에는 반드시 데이터베이스의 실행 계획을 확인하는 것을 권장
- 실행 계획을 통해 인덱스가 실제로 사용되는지, 테이블 전체를 스캔하는지(Full Table Scan), 정렬 비용이 큰지 등을 체감할 수 있음
- 만약 인덱스가 사용되지 않으면, 쿼리 구조나 인덱스 설계를 재검토해야 함
- DBMS에서 제공하는 EXPLAIN 명령어를 적극 활용
사. 데이터 건수 예측
- 페이징 쿼리는 데이터의 총량, 페이지 크기, 데이터 분포에 따라 성능이 크게 달라짐
- 개발 단계에서 데이터가 적을 때는 문제가 없어 보여도, 실제 운영 환경에서 수십만~수백만 건이 쌓이면 성능 이슈가 발생할 수 있음
- 반드시 충분히 많은 데이터로 테스트 진행한 뒤, 페이징 범위가 커졌을 때도 성능이 유지되는지 점검하는 것을 권장
- 필요하다면 페이지 크기를 제한하거나, 인덱스 설계를 강화하거나, 커서 방식으로 전환하는 등의 대책 필요
참고
인프런 - JPA (ORM) 개발자를 위한 고성능 SQL
반응형
'DB' 카테고리의 다른 글
| [RDBMS] 트랜잭션 (0) | 2025.05.14 |
|---|---|
| [RDBMS] 파생 테이블과 공통 테이블 표현식 (0) | 2025.05.12 |
| [RDBMS] JOIN 성능 (0) | 2025.05.12 |
| LATERAL JOIN 개요 (0) | 2025.04.30 |