개요
- 관계형 데이터베이스에서 복잡한 쿼리를 작성할 때, 임시적으로 쿼리 결과를 재사용하거나 여러 단계로 나누어 데이터를 처리하는 방법은 다음과 같음
- 파생 테이블(Derived Table)
- 공통 테이블 표현식(CTE, Common Table Expression
1. 파생 테이블 (Derived Table)
- 파생 테이블이란, FROM절에 직접 쿼리(SELECT문)를 작성하여 만들어지는 임시 테이블을 의미
- 해당 테이블은 쿼리 실행 시점에만 존재하며, 별칭을 반드시 부여해야 함
- 파생 테이블의 특징은 다음과 같음
- 쿼리 내부에서만 사용되는 일회성 임시 테이블
- FROM절에서만 정의할 수 있고, 쿼리의 나머지 부분에서만 접근 가능
- 복잡한 쿼리를 쪼개서 읽기 쉽게 만들거나, 집계 결과를 다시 활용할 때 주로 사용
- 중첩 사용(파생 테이블 안에 또 다른 파생 테이블) 가능
- 간단한 임시 집합이 필요할 때, 쿼리 중간에 즉시 사용할 때 적합함
부연 설명
- 괄호 안의 SELECT문이 바로 파생 테이블이며, d라는 별칭을 부여
2. 파생 테이블을 사용하는 예시
- 게시물 테이블(post)과 게시물에 대한 댓글 테이블(post_comment)이 있다고 가정할 때, 댓글이 가장 많은 상위 세 개의 게시물을 선별하는 상황
2.1 문제가 되는 쿼리
- 두 테이블을 JOIN 한 뒤 GROUP BY를 진행하면 PostgreSQL의 경우 Hash Join 알고리즘을 적용하고 MySQL의 경우 Nested Join 알고리즘을 적용
- Nested Join 알고리즘의 경우 기본적인 시간 복잡도가 O(N * M)이므로 오래 걸리는 것이 자명
- Hash Join 알고리즘은 한 테이블(보통 더 작은 테이블)을 메모리에 해시 테이블로 만들고 다른 테이블과 비교하는 방식이지만, 데이터 양이 지나치게 많을 경우 해시 테이블 생성과 집계 처리에 시간이 오래 걸릴 수 있는 단점이 있음


2.2 최적화
- JOIN을 수행하기 전에 GROUP BY 진행
- post_id를 사용할 수 있기 때문
- post_comment에 대해서만 GROUP BY를 진행하고 여기서 추출한 3개의 post_id에 대해서만 JOIN 진행
- 3개 row에 대해서만 JOIN을 하면 되므로 NESTED JOIN 알고리즘 적용 (따라서 Hash Join 과정이 없어짐에 따라 성능 개선)

3. 공통 테이블 표현식 (Common Table Expression)
- 쿼리의 앞부분에 WITH절을 사용하여 정의하는 임시 결과 집합
- 임시 뷰(View)를 쿼리 내에서 선언하는 것과 비슷
- CTE는 쿼리 본문에서 여러 번 재사용할 수도 있으며, 자기 자신을 참조하는 재귀적 CTE도 만들 수 있음
- CTE의 특징은 다음과 같음
- 쿼리의 시작 부분에 WITH절로 정의
- 메인 쿼리에서 여러 번 사용할 수 있고, 가독성이 뛰어남
- 여러 개의 CTE를 연달아 정의할 수 있음
- 재귀적 표현이 가능하여 트리 구조 등 복잡한 데이터 처리에 유용
- 대부분의 최신 DBMS에서 지원함
- 가독성과 유지보수성이 뛰어나 복잡한 쿼리에 적합함
4. 재귀적 공통 테이블 표현식 (Recursive CTE)
- Recursive CTE는 SQL의 WITH절을 이용해 자기 자신을 반복적으로 참조하는 임시 결과 집합을 정의하는 기능이며 이를 통해 트리나 그래프와 같은 계층(재귀) 구조를 데이터베이스 쿼리에서 손쉽게 탐색하거나 펼칠 수 있음
- Recursive CTE는 두 부분으로 나뉨
- Anchor Member(기준 부분): 재귀의 시작점, 보통 최상위 노드(예: root, top-level)에 해당하는 데이터를 반환
- Recursive Member(재귀 부분): 바로 앞에서 반환된 결과를 기반으로, 자기 자신을 다시 호출하며 계층을 한 단계씩 펼쳐 나감
- 데이터베이스 엔진은 Anchor Member를 먼저 실행한 뒤, Recursive Member를 반복적으로 실행하여 전체 계층을 완성하며 해당 반복은 새로운 결과가 더 이상 나오지 않을 때까지 계속됨
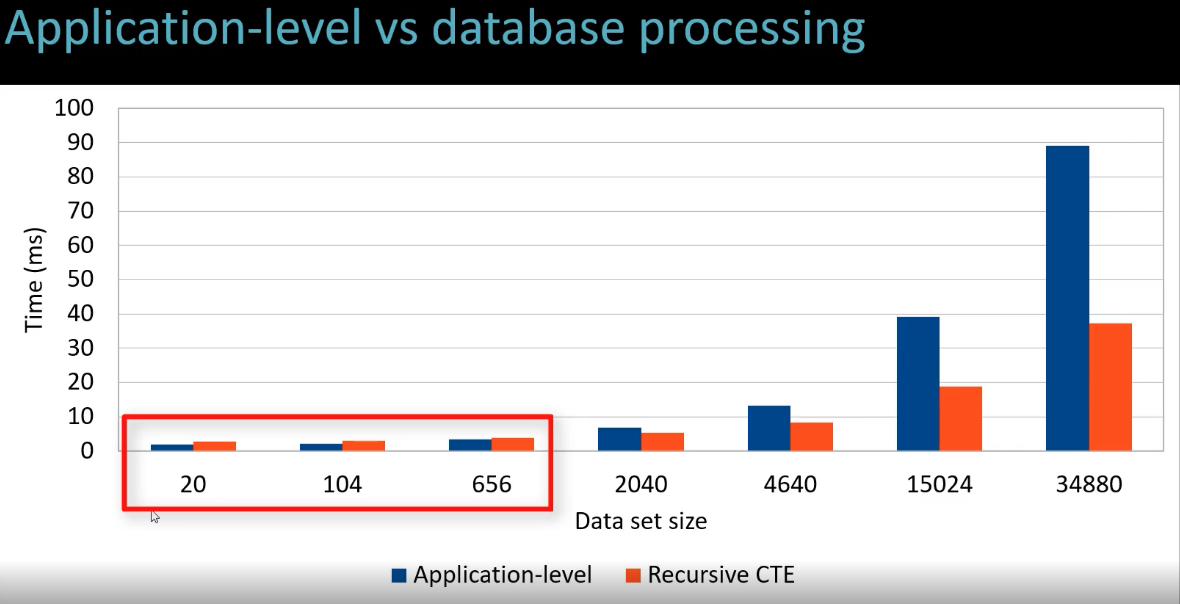
- Recursive CTE를 사용하지 않고 애플리케이션 레벨에서 계층 구조를 처리하는 것도 가능하지만 장단점이 존재함
- 장점: 데이터베이스 쿼리가 간단해지며 복잡한 계층 구조 조작을 프로그래밍 언어의 유연함으로 처리 가능
- 단점: 댓글이 많을 경우, 모든 데이터를 한 번에 읽어와야 하므로 네트워크와 메모리 사용량이 증가할 수 있으며 계층 구조를 직접 구현해야 하므로 애플리케이션 코드가 복잡해질 수 있음 (성능 저하 우려)
4.1 Recursive CTE 예제
- 특정 게시글(post_id=1)에 달린 모든 댓글과 대댓글을 계층적으로 조회하는 쿼리
부연 설명
- 해당 쿼리는 댓글과 대댓글을 계층적으로 조회할 수 있을 뿐 아니라, 각 댓글의 깊이(level)와 경로(path) 정보까지 함께 제공
- 트리 구조의 댓글 시스템을 구현하거나, 계층적 UI를 그릴 때 기초 데이터로 활용 가능
참고
인프런 - JPA (ORM) 개발자를 위한 고성능 SQL
반응형
'DB' 카테고리의 다른 글
| [RDBMS] 트랜잭션 (0) | 2025.05.14 |
|---|---|
| [RDBMS] 페이징 (Pagination) (0) | 2025.05.12 |
| [RDBMS] JOIN 성능 (0) | 2025.05.12 |
| LATERAL JOIN 개요 (0) | 2025.04.30 |